
Collection Framework (4)
안녕하세요, 드디어 길고 길었던 Collection Framework의 마지막 시간입니다. 오늘은 지난 포스트에 이어 HashMap과 TreeMap에 대해 알아보도록 하겠습니다.
HashMap
HashMap은 이름에서부터 유추할 수 있듯이 Map Interface에서 구현된 클래스입니다. HashSet과 마찬가지로 HashMap 또한 Hash에 쓰이며, 탐색(Search)에 좋은 성능을 보인다는 장점이 있습니다. 이와 비슷한 클래스로 Hashtable이 있는데, HashMap은 비동기식(asynchronous), Hashtable은 동기식(synchronized)이라는 차이점이 있습니다.

HashMap은 꽤 복잡하게 정의되어 있습니다. Map<K,V>, Cloneable, Serializable 인터페이스를 기반으로 구현되었으며 AbstractMap<K, V>로부터의 파생 클래스입니다. HashMap은 아래와 같이 정의되어 있습니다.
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
transient Node<K,V>[] table;
...
static class Node<K,V> implements Map.Entry<K,V> {
final K key;
V value;
...
}
}
Key-Value 쌍은 table이라는 Node 배열에 저장되어 있습니다. Hash 이므로 Key의 값은 중복이 불가능하며, Key가 다르다면 Value의 값은 중복이 가능합니다.
다음으로 HashMap에 대한 메소드들의 간략한 설명입니다. 먼저 다음 4개는 HashMap을 생성하는 메소드입니다.
- HashMap() : 비어있는 새 HashMap을 생성한다. 기본적으로 16의 Capacity와 0.75의 Load Factor를 갖습니다.
- HashMap(int initialCapacity) : 비어있는 새 HashMap을 생성한다. 매개변수로 넣은 initialCapacity만큼의 Capacity와 0.75의 Load Factor를 갖습니다.
- HashMap(int initialCapacity, float loadFactor) : 비어있는 새 HashMap을 생성한다. 매개변수로 넣은 initialCapacity만큼의 Capacity와 loadFactor 만큼의 Load Factor를 갖습니다.
- HashMap(Map<? extends K, ? extends V> m) : 매개변수로 넣은 Map m을 포함한 새로운 Map을 생성한다.
HashMap을 사용하는 메소드는 다음과 같습니다.
- void clear() : Map에 들어있는 모든 원소를 제거한다.
- Object clone() : HashMap 인스턴스를 복제한다. 단, Key-Value들은 복제되지 않는다.
- boolean containsKey(Object key) : Map에 매개변수로 들어온 key가 있다면 true를, 그렇지 않다면 false를 반환한다.
- boolean containsValue(Object value) : Map에 매개변수로 들어온 value가 있다면 true를, 그렇지 않다면 false를 반환한다.
- Set<Map.Entry<K,V» entrySet() : Map에 포함된 Key-Value Mapping을 Set으로 반환한다.
- V get(Object key) : Map에서 매개변수로 들어온 key에 Mapping된 value를 반환한다. 만약 key가 없다면 null을 반환한다.
- boolean isEmpty() : Map에 Key-Value 쌍이 없으면 true를, 그렇지 않으면 false를 반환한다.
- Set
keySet() : Map에 포함된 Key들을 Set으로 반환한다. - V put(K key, V value) : 매개변수로 들어온 key와 value를 연결한다.
- void putAll(Map<? extends K, ? extends V> m) : 매개변수로 들어온 Map m의 모든 Mapping을 이 Map으로 복사한다.
- V remove(Object key) : Map에 매개변수로 들어온 key를 포함한 쌍을 제거한다.
- int size() : 이 Map의 Key-Value 쌍의 수를 반환한다.
- Collection
values() : Map에 포함된 모든 value를 Collection으로 반환한다.
이제 HashMap을 사용한 예제를 하나씩 살펴보도록 하겠습니다. 먼저 다음 프로그램은 HashMap을 사용하여 로그인 시스템을 구현한 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import java.util.*;
public class Main {
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<>();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234");
Scanner s = new Scanner(System.in);
while(true) {
System.out.println("Please enter id and password.");
System.out.print("id: ");
String id = s.nextLine().trim();
System.out.print("password: ");
String password = s.nextLine().trim();
System.out.println();
if(!map.containsKey(id)) {
System.out.println("id does not exist.");
continue;
} else {
if(!(map.get(id)).equals(password)) {
System.out.println("password does not match.");
} else {
System.out.println("welcome.");
break;
}
}
}
s.close();
}
}
첫 번째 예제에서는 ID를 Key, 비밀번호를 Value로 사용하여 Mapping하고 있습니다. ID와 Value가 일치하면 로그인에 성공하고, 그렇지 않으면 실패했다는 메시지를 띄운 후 다시 ID와 비밀번호를 입력하는 구조입니다. 문제는 7~8번째 라인에서 동일한 Key 값을 가진 노드를 삽입하는 것입니다. 실제로 테스트를 해보면 asdf – 1111 로는 로그인이 되지 않고, asdf – 1234로만 로그인이 가능합니다. 이렇게 Key 값이 같은 노드를 삽입한다면 나중에 삽입한 노드만 남게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import java.util.*;
public class Main {
static HashMap<String,HashMap<String,String>> phoneBook = new HashMap<>();
public static void main(String[] args) {
addPhoneNo("friend", "Lee Java", "010-111-1111");
addPhoneNo("friend", "Kim Java", "010-222-2222");
addPhoneNo("friend", "Kim Java", "010-333-3333");
addPhoneNo("work", "Kim Daeri", "010-444-4444");
addPhoneNo("work", "Kim Daeri", "010-555-5555");
addPhoneNo("work", "Park Daeri", "010-666-6666");
addPhoneNo("work", "Lee Guajang", "010-777-7777");
addPhoneNo("laundary", "010-888-8888");
printList();
}
static void addPhoneNo(String groupName, String name, String tel) {
addGroup(groupName);
HashMap<String,String> group = phoneBook.get(groupName);
group.put(tel, name); // use phone number as key because names can have duplicates.
}
static void addGroup(String groupName) {
if(!phoneBook.containsKey(groupName)) phoneBook.put(groupName, new HashMap<String,String>());
}
static void addPhoneNo(String name, String tel) {
addPhoneNo("others", name, tel);
}
static void printList() {
Set<Map.Entry<String,HashMap<String,String>>> set = phoneBook.entrySet();
Iterator<Map.Entry<String,HashMap<String,String>>> it = set.iterator();
while(it.hasNext()) {
Map.Entry<String,HashMap<String,String>> e = (Map.Entry<String,HashMap<String,String>>)it.next();
Set<Map.Entry<String,String>> subset = e.getValue().entrySet();
Iterator<Map.Entry<String,String>> subIt = subset.iterator();
System.out.println(" * " + e.getKey() + "[" + subset.size() + "]");
while(subIt.hasNext()) {
Map.Entry<String,String> subE = (Map.Entry<String,String>)subIt.next();
String telNo = subE.getKey();
String name = subE.getValue();
System.out.println(name + " " + telNo);
}
System.out.println();
}
}
}
두 번째 예제는 전화번호부를 HashMap으로 구현한 프로그램입니다. 보통 이름 - 전화번호 순으로 저장하기 때문에 이름을 Key, 전화번호를 Value로 저장하겠지만, 이름에는 동명이인이 있을 수 있기 때문에 여기서는 전화번호를 Key로, 이름과 그룹을 Value로 정의하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import java.util.*;
public class Main {
public static void main(String[] args) {
String[] data = {"A", "K", "A", "K", "D", "K", "A", "K", "K", "K", "Z", "D"};
HashMap<String,Integer> map = new HashMap<>();
for(int i=0; i<data.length; i++) {
if(map.containsKey(data[i])) {
Integer value = map.get(data[i]);
map.put(data[i], Integer.valueOf(value.intValue() + 1));
} else {
map.put(data[i], Integer.valueOf(1));
}
}
Iterator<Map.Entry<String,Integer>> it = map.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<String,Integer> entry = it.next();
int value = entry.getValue().intValue();
System.out.println(entry.getKey() + ": " + printBar('#', value) + " " + value);
}
}
public static String printBar(char ch, int value) {
char[] bar = new char[value];
for(int i=0; i<bar.length; i++) bar[i] = ch;
return new String(bar);
}
}
세 번째 예제는 HashMap을 사용하여 같은 입력이 몇 번 들어왔는지 카운트하는 프로그램입니다. Key의 값과 일치하는 입력이 들어올 때마다 Value의 값을 1씩 증가시키는 간단한 프로그램입니다.
HashMap은 이름처럼 Hashing을 하는데도 사용됩니다. 첫 번째나 두 번째의 경우처럼 기본적인 1-1 Hashing으로 사용할 수도 있으나, 아래처럼 Linked List를 활용한 구조 또한 가능합니다.
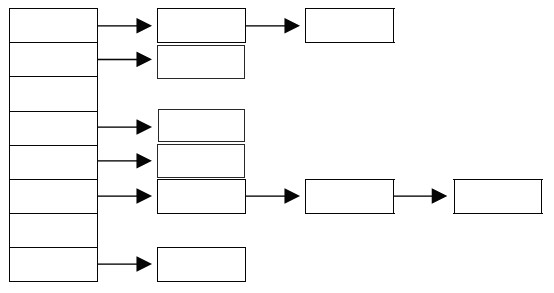
Hashing에서의 성능상의 이점은 Hash 함수를 사용하여 Hash 값을 계산하는 것이 매우 빠르다는 것입니다. 하지만 위처럼 Linked List를 사용하여 한 Hash 값에 여러 데이터를 저장하는 경우 데이터 검색이 느려지는 단점이 있습니다. 따라서 검색 성능이 중요한 프로그램이라면 1개의 슬롯에 1개의 데이터(Value)만 있는 것이 좋습니다.
HashMap과 같이 Hashing을 사용하는 Collection 클래스는 HashCode() 메소드를 Hash 함수로 사용하여 슬롯을 계산합니다. HashCode() 메소드는 Object 클래스에 정의되어 있으며 매개변수가 다른 경우 항상 다른 값을 반환합니다.
물론 이전 포스트의 HashSet처럼 HashCode() 메소드를 재정의(Overriding)해서 사용할 수도 있습니다. 이 경우 HashCode()를 Key로 사용하여 HashMap의 슬롯을 계산하여야 합니다. 만약 equals()를 재정의해서 사용한다면 equals()의 요구사항(지난 포스트 참조)을 반드시 지켜야 합니다.
클래스에서 equals()를 재정의하지만 HashCode()를 재정의하지 않는 경우 클래스는 equals()가 true를 반환하더라도 두 Object를 다른 Object로 간주할 수 있으니 주의해야 합니다.
TreeMap
TreeMap은 이름대로 Tree 자료구조를 사용하여 데이터를 저장하는 Map입니다. 하지만 Binary Search Tree를 사용하는 TreeSet과는 다르게 TreeMap은 Red-Black Tree를 사용합니다. Red-Black Tree는 Tree의 각 노드를 특정한 규칙에 따라 Red나 Black으로 나눈 Binary Search Tree입니다. 자세한 내용은 위키백과를 참고해주시기 바랍니다. 추후 자료구조 관련 포스트를 쓰게 되면 Red-Black Tree에 대해 자세히 다뤄보도록 하겠습니다.
TreeMap은 Key를 기준으로 정렬됩니다. 이 때, Key에 사용하는 클래스가 비교가능(Comparable)하지 않은 경우, Exception이 일어납니다. (이 점은 TreeSet과 같습니다) TreeMap은 Key로 원소들을 정렬할 때 유용하지만, 탐색할 때는 HashMap보다 느리다는 단점이 있습니다.
TreeMap을 생성하는 메소드들은 다음과 같습니다.
- TreeMap() : 비어있는 새 TreeMap을 생성한다. (기본 Ordering으로 정렬)
- TreeMap(Comparator<? super K> comparator) : 비어있는 새 TreeMap을 생성한다. (매개변수로 들어온 Ordering으로 정렬)
- TreeMap(Map<? extends K, ? extends V> m) : Map m을 포함한 새 TreeMap을 생성한다. (기본 Ordering으로 정렬)
- TreeMap(SortMap<K, ? extends V> m) : 정렬되어있는 Map m을 포함한 TreeMap을 생성한다. (Ordering은 m를 따른다)
다음으로 TreeMap에 사용되는 메소드 목록입니다. TreeSet과 마찬가지로 메소드가 워낙 많아 정리가 힘드네요.
- Map.Entry<K,V> ceilingEntry(K key) : Map에서 매개변수로 들어온 key보다 크거나 같은 Key중 가장 작은 Key-Value 쌍을 반환한다. 만약 없다면 null을 반환한다.
- K ceilingKey(K key) : Map에서 매개변수로 들어온 key보다 크거나 같은 Key중 가장 작은 Key를 반환한다. 만약 없다면 null을 반환한다.
- void clear() : Map에서 모든 Mapping을 제거한다.
- Object clone() : 이 TreeMap 인스턴스를 복제하여 반환한다.
- boolean containsKey(Object key) : Map에서 매개변수로 들어온 key가 존재한다면 true를 반환한다.
- boolean containsValue(Object value) : Map에서 매개변수로 들어온 value가 존재한다면 true를 반환한다.
- NavigableSet
descendingKeySet() : Map의 Key를 역순으로 반환한다. - NavigableMap<K,V> descendingMap() : Map의 Key-Value 쌍을 역순으로 반환한다.
- Set<Map.Entry<K,V» entrySet() : Map의 Key-Value 쌍을 Set으로 반환한다.
- Map.Entry<K,V> firstEntry() : Map에서 가장 작은 Key에 대해 Key-Value 쌍을 반환한다. map이 비어있다면 null을 반환한다.
- K firstKey() : Map에서 가장 작은 Key를 반환한다.
- Map.Entry<K,V> floorEntry(K key) : Map에서 매개변수로 들어온 key보다 작거나 같은 Key중 가장 큰 Key-Value 쌍을 반환한다. 만약 없다면 null을 반환한다.
- K floorKey(K key) : Map에서 매개변수로 들어온 key보다 작거나 같은 Key중 가장 큰 Key를 반환한다. 만약 없다면 null을 반환한다.
- V get(Object key) : Map에서 매개변수로 들어온 key와 Mapping된 Value를 반환한다. 만약 없다면 null을 반환한다.
- SortedMap<K,V> headMap(K toKey) : Map에서 매개변수로 들어온 key보다 작은 Key-Value Mapping들을 반환한다.
- NavigableMap<K,V> headMap(K toKey, boolean inclusive) : Map에서 매개변수로 들어온 key보다 작은 (만약 inclusive가 true라면 같은 것도 포함) Key-Value Mapping들을 반환한다.
- Map.Entry<K,V> higherEntry(K key) : Map에서 매개변수로 들어온 key보다 큰 Key중 가장 작은 Key-Value 쌍을 반환한다. 만약 없다면 null을 반환한다.
- K higherKey(K key) : Map에서 매개변수로 들어온 key보다 큰 Key중 가장 작은 Key를 반환한다. 만약 없다면 null을 반환한다.
- Set
keySet() : Map에 포함된 모든 Key를 Set으로 반환한다. - Map.Entry<K,V> lastEntry() : Map에서 가장 큰 Key에 대해 Key-Value 쌍을 반환한다. map이 비어있다면 null을 반환한다.
- K lastKey() : Map에서 가장 큰 Key를 반환한다.
- Map.Entry<K,V> lowerEntry(K key) : Map에서 매개변수로 들어온 key보다 작은 key중 가장 큰 Key-Value 쌍을 반환한다. 만약 없다면 null을 반환한다.
- K lowerKey(K key) : Map에서 매개변수로 들어온 key보다 작은 Key중 가장 큰 Key를 반환한다. 만약 없다면 null을 반환한다.
- NavigableSet
navigableKeySet() : Map에 포함된 Key들을 NavigableSet으로 반환한다. - Map.Entry<K,V> pollFirstEntry() : Map에 포함된 Key 중 가장 작은 Key-Value 쌍을 반환하고 Map에서 삭제한다. 만약 Map이 비어있다면 null을 반환한다.
- Map.Entry<K,V> pollLastEntry() : Map에 포함된 Key 중 가장 큰 Key-Value 쌍을 반환하고 Map에서 삭제한다. 만약 Map이 비어있다면 null을 반환한다.
- V put(K key, V value) : Map에서 매개변수로 들어온 key에 매개변수로 들어온 value를 Mapping한다.
- void putAll(Map<? extends K, ? extends V> map) : 매개변수로 들어온 map을 이 Map에 복사한다.
- V remove(Object key) : Map에서 매개변수로 들어온 key를 포함한 Mapping을 제거한다.
- int size() : 이 Map의 Key-Value 쌍의 수를 반환한다.
- NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) : Map에서 매개변수로 들어온 fromKey부터 toKey까지의 Key-Value 쌍들을 반환한다.
- SortedMap<K,V> subMap(K fromKey, K toKey) : Map에서 매개변수로 들어온 fromKey부터 toKey까지의 Key-Value 쌍들을 반환한다. 이 때 fromKey는 포함하고 toKey는 포함하지 않는다.
- SortedMap<K,V> tailMap(K fromKey) : Map에서 매개변수로 들어온 fromKey를 포함하여 fromKey보다 큰 Key-Value 쌍들을 반환한다.
- NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) : Map에서 매개변수로 들어온 fromKey보다 큰 (만약 inclusive가 true라면 같은 것도 포함) Key-Value 쌍들을 반환한다.
- Collection
values() : Map에 포함된 모든 value를 Collection으로 반환한다.
메소드가 엄청나게 많지만, 비슷한 메소드들이 많습니다. 적당히 이해하고 넘어가시면 될 것 같습니다. 마지막으로 TreeMap 예제를 하나 보도록 하겠습니다. 이 프로그램은 바로 위에 있는 HashMap의 3번째 예제를 조금 수정하여, 입력 회수가 많은 순서대로 문자를 정렬하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import java.util.*;
public class Main {
public static void main(String[] args) {
String[] data = {"A","K","A","K","D","K","A","K","K","K","Z","D"};
TreeMap<String,Integer> map = new TreeMap<>();
for(int i=0; i<data.length; i++) {
if(map.containsKey(data[i])) {
Integer value = map.get(data[i]);
map.put(data[i], Integer.valueOf(value.intValue() + 1));
} else {
map.put(data[i], Integer.valueOf(1));
}
}
Iterator<Map.Entry<String,Integer>> it = map.entrySet().iterator();
System.out.println("=== basic sort ===");
while(it.hasNext()) {
Map.Entry<String,Integer> entry = it.next();
int value = entry.getValue().intValue();
System.out.println(entry.getKey() + ": " + printBar('#', value) + " " + value);
}
System.out.println();
Set<Map.Entry<String,Integer>> set = map.entrySet();
List<Map.Entry<String,Integer>> list = new ArrayList<>(set);
Collections.sort(list, new ValueComparator<Map.Entry<String,Integer>>());
it = list.iterator();
System.out.println("=== sort by the value ===");
while(it.hasNext()) {
Map.Entry<String,Integer> entry = it.next();
int value = entry.getValue().intValue();
System.out.println(entry.getKey() + ": " + printBar('#', value) + " " + value);
}
}
// inner class
@SuppressWarnings("unchecked")
static class ValueComparator<T> implements Comparator<T> {
public int compare(Object o1, Object o2) {
if(o1 instanceof Map.Entry && o2 instanceof Map.Entry) {
Map.Entry<String,Integer> e1 = (Map.Entry<String, Integer>)o1;
Map.Entry<String,Integer> e2 = (Map.Entry<String, Integer>)o2;
int v1 = e1.getValue().intValue();
int v2 = e2.getValue().intValue();
return v2 - v1;
}
return -1;
}
}
public static String printBar(char ch, int value) {
char[] bar = new char[value];
for(int i=0; i<bar.length; i++) bar[i] = ch;
return new String(bar);
}
}
basic sort를 출력하는 부분까지는 HashMap과 크게 다르지 않습니다. 그러나 HashMap의 예제와는 달리 여기에는 많이 입력된 문자를 정렬하는 부분이 추가되었습니다. 23번째 Line부터 정렬이 들어가는데, 정렬을 하기 위해 값을 비교하는 ValueComparator 클래스가 추가되었습니다. 이 경우 Key는 입력된 문자(알파벳)이기 때문에 알파벳 순서대로 정렬되기 때문입니다. 많이 입력된 순서를 따르기 위해서는 Value의 값을 참조해야 하므로 Compare 메소드를 재정의한 것입니다. 이로 인해 프로그램이 조금 길어졌지만, 말씀드린대로 각각의 구조를 살펴보시면 이해가 되실 겁니다.
이번 포스트를 마지막으로 Collection Framework 파트가 마무리되었습니다. 다음 포스트부터는 새 주제로 작성하도록 하겠습니다. 읽어주셔서 감사합니다!
Leave a comment