
Networking with Java (1)
지난 4개의 포스트로 Collection Framework는 마무리가 되었습니다. 글을 잘 쓰는 편이 아니라 혹시라도 이해가 안가는 부분이 있다면 댓글을 달아주시기 바랍니다. 최대한 아는 선에서 설명드릴 수 있도록 글을 보완해나가도록 하겠습니다.
이번에는 Java를 사용한 네트워크 프로그램을 다루는 주제입니다. 네트워크 프로그램을 다루기 위해서는 네트워크에 대한 배경지식이 필요한데, 이번 포스트에서는 그 배경지식과 함께 간단한 프로그램을 Java로 만들어보고, 다음 포스트에서 소켓 프로그래밍을 다뤄보도록 하겠습니다.
Background
최근 대부분의 프로그램은 네트워크를 사용하여 연결되고 있습니다. 웹 서핑을 하기 위한 웹 브라우저부터 게임과 같은 어플리케이션들도 네트워크가 거의 필수적으로 요구되어 있습니다. Java에서는 java.net 패키지를 통해 쉽고 간편하게 네트워크 기능을 제공하고 있습니다.
Network Architecture는 크게 클라이언트-서버(Client-Server) 방식과 피어 투 피어(Peer-to-Peer; P2P) 방식으로 나뉘어 있습니다. 클라이언트-서버 방식은 서버 하나, 또는 서버의 군집이 여러 클라이언트에게 서비스를 제공하는 방식입니다. 서버가 대기하고 있으면 클라이언트가 서버에 연결을 시도하는 방식으로 네트워크가 이루어집니다. 대표적으로 메일 서버, 웹 서버 (HTTP), 파일 서버 (FTP) 등이 있습니다.
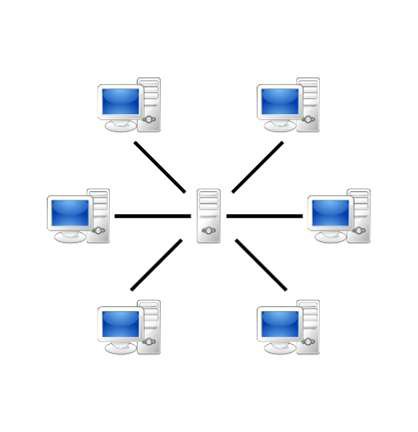
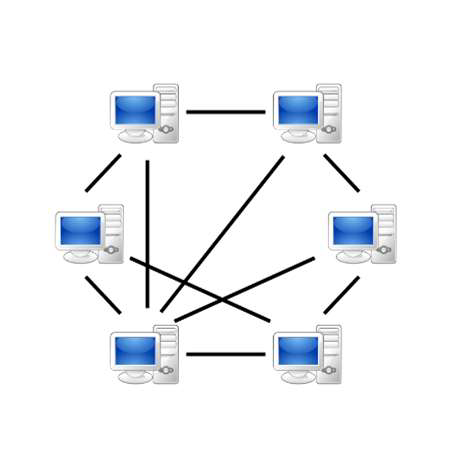
P2P 방식은 단말기들이 클라이언트나 서버로 분류되지 않고 상황에 따라 클라이언트가 될 수도, 서버가 될 수도 있는 방식입니다. 현재 많은 사람들이 사용하고 있는 BitTorrent가 대표적인 P2P 방식입니다.
단말기가 인터넷에 연결되기 위해서는 반드시 고유한 IP 주소가 필요합니다. IP 주소는 현실의 집 주소와 비슷하게 상대방을 찾는 용도로 사용됩니다. 현재 사용하고 있는 IPv4 기준으로 IP 주소는 32 bit이며, 약 43억개의 고유 주소를 사용할 수 있습니다. 하지만 단말기가 점점 늘어남에 따라 고유 주소가 부족해지고 있으며, 이를 해결하기 위해 128 bit의 주소를 사용하는 IPv6가 고안되었습니다. 하지만 아직은 IPv4를 사용하고 있기 때문에 IP 주소라고 하면 IPv4를 의미합니다.
IP 주소는 32 bit의 주소를 8 bit씩 나누어 .(dot)으로 구분하여 표기하고 있습니다. 8 bit이기 때문에 IP 주소는 이론적으로 0.0.0.0부터 255.255.255.255까지 가능합니다. 하지만 이 모든 주소를 사용할 수 있는 것은 아니며 일부 주소는 사설 네트워크(Private Network)로 분류되어 있습니다. 다음은 사설 네트워크로 분류되어 있는 주소입니다.
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
이러한 사설 네트워크에서는 외부 네트워크와 연결하기 위해 Network Address Translation (NAT)가 필요합니다. NAT가 무엇인지는 여기서 설명드리는 것보다 위키백과를 참고해주시기 바랍니다.
또한 단말기도 사람처럼 이름이 존재합니다. 단말기를 식별하는데 사용되는 할당된 문자열 레이블을 호스트 이름(Host Name)이라고 합니다. 호스트 이름을 확인하려면 윈도우 10을 기준으로 시스템의 장치 이름을 보시면 됩니다.

단말기의 이름 외에도 네트워크 상의 IP 주소를 대체하는 도메인 이름(Domain Name)도 있습니다. 도메인 이름 또한 IP 주소처럼 고유하며 주로 웹 사이트의 주소를 식별하는데 사용합니다. 예를 들어 네이버 웹 사이트의 도메인 이름은 naver.com 입니다.
도메인 이름과 유사한 Internet Hostname도 있습니다. Local Hostname과 도메인 이름을 이은 명칭을 Internet Hostname이라 부릅니다. 예를 들어 www.naver.com이 있습니다. Local Hostname은 대부분 www이기 때문에 도메인 이름과 크게 다를 것이 없기 때문에 보통 도메인 이름만을 사용합니다. 주소창에 Local Hostname을 제외한 도메인 이름만 입력해도 상관없기도 하구요.
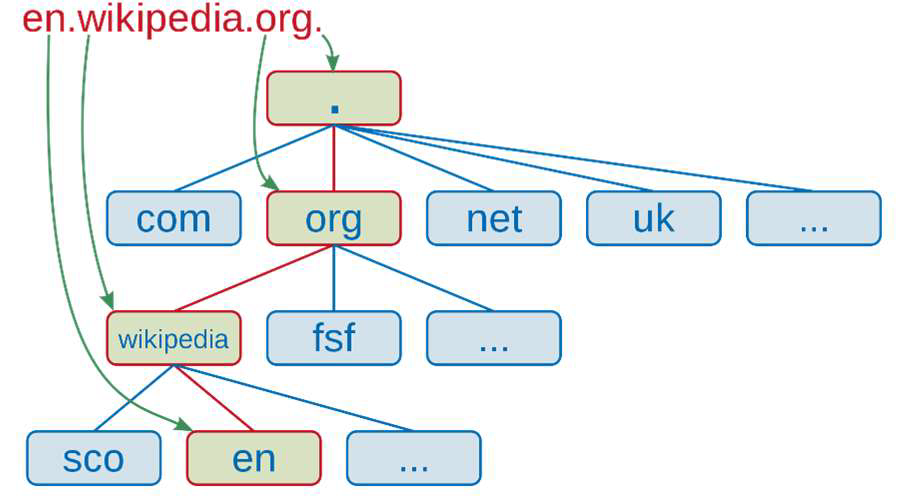
마지막으로 Fully Qualified Domain Name (FQDN)이 있습니다. FQDN은 Absolute Domain Name이라고도 불리며, Domain Name 시스템의 트리 계층 구조에서 정확한 위치를 지정하는 Domain Name을 말합니다. 예를 들어, en.wikipedia.org를 FQDN으로 표현하면 아래 그림과 같습니다.
네임 서버(Name Server)는 위에서 언급한 IP 주소와 도메인 이름을 연결해주는 역할을 하는 서버입니다. 웹 브라우저에서 웹 사이트를 방문할 때, IP 주소는 외우기 힘들기 때문에 주로 도메인 이름을 입력합니다. 예를 들어 웹 브라우저 주소창에 www.naver.com을 입력하면 브라우저는 www.naver.com에 Mapping된 IP 주소를 자동으로 연결해주게 됩니다. 만약 브라우저에서 IP 주소를 알 수 없다면, 브라우저는 네임 서버에 IP 주소를 물어보고 네임 서버는 클라이언트 브라우저에 IP 주소를 보내주는 방식이 됩니다.
단말기는 통신하기 위해 일반적으로 IP 주소 1개를 배정받습니다. 하지만 단말기는 보통 여러 개의 네트워크 서비스를 사용/제공하고 있습니다. 예를 들어 컴퓨터가 웹 서버와 FTP 서버를 동시에 제공할 수 있습니다. 이런 경우 통신할 때 어떤 서비스에 연결할 것인지 구분해야하는데, 이를 위하여 포트(Port) 번호를 사용합니다.
포트 번호는 16 bit 정수로 나타내며 각 서비스마다 구분되어 있습니다. 일반적으로 알려진 포트 번호는 http(80), https(443), ftp(21), ssh(22), telnet(23) 등이 있습니다. 따라서 서버에 연결할 때, 클라이언트는 반드시 IP 주소와 포트 번호를 명시해야 합니다.
InetAddress
InetAddress는 Java에서 IP 주소를 다루기 위해 사용하는 클래스입니다. 통신에서 IP 주소를 사용하는 경우가 많기 때문에 먼저 InetAddress 클래스에 정의된 메소드를 간략하게 소개하고, 예제를 통해 사용하는 방법을 알아보도록 하겠습니다.
- byte[] getAddress() : IP주소를 byte 배열로 변환한다.
- static InetAddress[] getAllByName(String host) : 매개변수로 들어온 모든 host의 IP 주소를 배열로 반환한다.
- static InetAddress getByAddress(byte[] addr) : 매개변수로 들어온 byte 배열로 처리된 IP 주소를 원래 자료형(IndetAddress)으로 반환한다.
- static InetAddress getByName(String host) : 매개변수로 들어온 host의 IP 주소를 반환한다.
- String getCanonicalHostName() : IP 주소에 대한 FQDN을 반환한다.
- String getHostAddress() : 호스트의 IP 주소를 반환한다.
- String getHostName() : IP 주소에 대한 호스트 이름을 반환한다.
- static InetAddress getLocalHost() : Localhost의 IP 주소를 반환한다.
- boolean isMulticastAddress() : IP 주소가 멀티캐스트 주소라면 true를 반환한다.
- boolean isLoopbackAddress() : IP 주소가 루프백 주소면 true를 반환한다.
첫 번째 예제는 네이버(Naver)의 호스트 이름과 IP 주소를 출력하는 간단한 프로그램입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import java.net.InetAddress;
import java.net.UnknownHostException;
public class Main {
public static void main(String[] args) {
InetAddress ip = null;
try {
ip = InetAddress.getByName("www.naver.com");
System.out.println("getHostName(): " + ip.getHostName());
System.out.println("getHostAddress(): " + ip.getHostAddress());
System.out.println("toString(): " + ip.toString());
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
첫 번째 예제에서 중점적으로 봐야 하는 곳은 예외 처리 부분입니다. 매개변수로 넣은 호스트가 존재하지 않을 수도 있기 때문에 try-catch 블록으로 예외 처리를 해주셔야 합니다. 이 때 체크하는 예외의 종류는 UnknownHostException입니다. 만약 예외 처리를 하지 않는다면 컴파일 에러가 발생합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
InetAddress ip = null;
try {
ip = InetAddress.getByName("www.naver.com");
byte[] ipAddr = ip.getAddress();
System.out.println("getAddress(): " + Arrays.toString(ipAddr));
String result = "";
for(int i=0; i<ipAddr.length; i++) {
result += (ipAddr[i] < 0) ? ipAddr[i] + 256 : ipAddr[i];
result += ".";
}
System.out.println("getAddress()+256: " + result);
System.out.println();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
두 번째 예제는 byte 자료형을 사용할 때의 주의점을 알려주는 프로그램입니다. getAddress() 메소드는 IP 주소를 byte 자료형의 배열로 반환합니다. 그런데 byte 자료형은 -128부터 127까지의 수만 표현할 수 있습니다. 그렇기 때문에 그냥 출력하게 되면 주소에서 127보다 큰 숫자는 음수로 출력되어 버리는 문제가 있습니다. 그래서 getAddress() 메소드를 사용할 경우 예제처럼 0보다 작은 숫자라면 256을 더해야 정상적인 IP 주소가 출력됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import java.net.InetAddress;
import java.net.UnknownHostException;
public class Main {
public static void main(String[] args) {
InetAddress ip = null;
try {
ip = InetAddress.getLocalHost();
System.out.println("getHostName(): " + ip.getHostName());
System.out.println("getHostAddress(): " + ip.getHostAddress());
System.out.println();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
세 번째 예제는 Localhost의 호스트 이름과 IP 주소를 출력하는 프로그램입니다. Localhost는 쉽게 말해 자신의 컴퓨터를 말합니다. 실제로 프로그램을 실행해보시면 호스트 이름에는 자신의 컴퓨터 이름, IP 주소는 자신의 IP 주소가 출력됨을 알 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import java.net.InetAddress;
import java.net.UnknownHostException;
public class Main {
public static void main(String[] args) {
InetAddress[] ipArr = null;
try {
ipArr = InetAddress.getAllByName("www.naver.com");
for(int i=0; i<ipArr.length; i++) {
System.out.println("ipArr["+i+"]: " + ipArr[i]);
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
네 번째는 호스트가 여러 IP 주소와 연결되어 있는 경우를 보여주는 프로그램입니다. 테스트해본 결과 네이버는 2개의 IP 주소와 연결되어 있네요.
URL
URL은 Uniform Resource Locator의 약자로 컴퓨터 네트워크에서 웹 리소스의 위치를 나타내는 규약입니다. 다른 말로 “Web address”라고도 불리며 웹 브라우저의 주소 표시줄에 나타나 있습니다. 예를 들어, 이 포스트의 URL은 https://keepmind.net/java/networking-with-java-1/ 입니다.
URL의 포멧은 scheme:[//authority]path[?query][#fragment] 으로 나타냅니다. 각각이 나타내는 바가 무엇인지 정리하면 다음과 같습니다.
- scheme : 자원에 접근하는데 사용되는 프로토콜 (ex. http)
- authority : [userinfo@]host[:port]
- host : 웹 리소스를 보유하고 있는 호스트 이름 (ex. www.example.com)
- port : 서버가 수신중인 포트 번호 (ex. http=80, https=443)
- path : 웹 리소스의 경로 및 파일 이름
- query : 파일에 대한 argument
- fragment : 파일 내 fragment의 index
Java에서는 URL을 다루는 URL 클래스가 존재합니다. URL 객체를 생성하는 방법으로 3가지 메소드가 있습니다.
- URL(String spec) : 매개변수로 들어온 spec 문자열로 URL 객체를 생성한다.
- URL(String protocol, String host, String file) : 매개변수로 들어온 프로토콜, 호스트 이름, 파일 이름으로 URL 객체를 생성한다.
- URL(String protocol, String host, int port, String file) : 매개변수로 들어온 프로토콜, 호스트 이름, 포트 번호, 파일 이름으로 URL 객체를 생성한다.
각 메소드의 사용 예는 다음과 같습니다.
URL url = new URL("http://docs.oracle.com/javase/10/docs/api/java/net/URL.html");
URL url = new URL("http", "docs.oracle.com", "/javase/10/docs/api/java/net/URL.html");
URL url = new URL("http", "docs.oracle.com", 80, "/javase/10/docs/api/java/net/URL.html");
다음으로 URL 클래스에 정의된 메소드 목록입니다.
- String getAuthority() : URL의 Authority 부분을 반환한다.
- Object getContent() : URL의 컨텐츠를 반환한다. (ex. 이미지라면 이미지로 반환)
- Object getContent(Class<?>[] classes) : URL의 컨텐츠를 반환한다.
- int getDefaultPort() : URL에 관련된 기본 포트 번호를 반환한다.
- String getFile() : URL의 파일 이름을 반환한다.
- String getHost() : URL의 호스트 이름을 반환한다.
- String getPath() : URL의 Path 부분을 반환한다.
- int getPort() : URL의 포트 번호를 반환한다.
- String getProtocol() : URL의 프로토콜 이름을 반환한다.
- String getQuery() : URL의 Query 부분을 반환한다.
- String getRef() : URL의 Reference 부분을 반환한다.
- String getUserInfo() : URL의 UserInfo 부분을 반환한다.
- URLConnection openConnection() : URL이 참조하는 원격 개체에 대한 연결을 나타내는 URLConnection 인스턴스를 반환한다.
- URLConnection openConnection(Proxy proxy) : openConnection()과 동일하나 매개변수로 지정된 프록시를 통해 연결한다.
- InputStream openStream() : URL을 연결하고 읽기 위한 InputStream을 반환합니다.
- boolean sameFile(URL other) : 두 URL을 비교하여 같은 리소스인지 비교한다. 같으면 true를 반환한다.
- String toExternalForm() : URL을 문자열로 반환한다.
- URI toURI() : URL에 해당하는 URI (Uniform Resource Identifier)를 반환한다.
다음 예제는 위에 정리된 메소드 중 일부를 테스트하는 간단한 프로그램입니다. URL을 변경해가며 테스트해보시기 바랍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import java.net.URL;
public class Main {
public static void main(String[] args) {
try {
URL url = new URL("http://www.google.com");
System.out.println("url.getAuthority(): " + url.getAuthority());
System.out.println("url.getContent(): " + url.getContent());
System.out.println("url.getDefaultPort(): " + url.getDefaultPort());
System.out.println("url.getPort(): " + url.getPort());
System.out.println("url.getFile(): " + url.getFile());
System.out.println("url.getHost(): " + url.getHost());
System.out.println("url.getPath(): " + url.getPath());
System.out.println("url.getProtocol(): " + url.getProtocol());
System.out.println("url.getQuery(): " + url.getQuery());
System.out.println("url.getRef(): " + url.getRef());
System.out.println("url.getUserInfo(): " + url.getUserInfo());
System.out.println("url.toExternalForm(): " + url.toExternalForm());
System.out.println("url.toURI(): " + url.toURI());
} catch (Exception e) {
e.printStackTrace();
}
}
}
두 번째 예제는 웹 페이지의 컨텐츠를 긁어오는 프로그램입니다. 이전에 배웠던 파일에서 데이터를 읽는 방법과 구조가 크게 다르지 않습니다. 파일 위치가 URL로 바뀐 것 외에는 똑같다고 보시면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
public class Main {
public static void main(String[] args) {
try {
URL url = null;
BufferedReader input = null;
String address = "https://www.google.com/";
String line = "";
try {
url = new URL(address);
input = new BufferedReader(new InputStreamReader(url.openStream()));
while((line=input.readLine()) != null) {
System.out.println(line);
}
input.close();
} catch(Exception e) {
e.printStackTrace();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
세 번째 예제는 URL로부터 파일을 다운로드받는 프로그램입니다. 다운로드 경로를 딱히 지정하지 않으면 프로그램이 들어있는 프로젝트 폴더 내에 다운로드 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import java.io.InputStream;
import java.io.FileOutputStream;
import java.net.URL;
public class Main {
public static void main(String[] args) {
URL url = null;
InputStream in = null;
FileOutputStream out = null;
String address = "https://keepmind.net///wp-content/uploads/2021/01/KEEPMIND-Logo-544x180-1.png";
int ch = 0;
try {
url = new URL(address);
in = url.openStream();
out = new FileOutputStream("KEEPMIND_Logo.jpg");
while((ch=in.read()) != -1) {
out.write(ch);
}
in.close();
out.close();
} catch(Exception e) {
e.printStackTrace();
}
System.out.println("File download complete.");
}
}
네 번째 예제는 웹 페이지의 소스를 분석하여 원하는 부분만을 정리하여 출력하는 Parsing 프로그램입니다. 예제에서는 교보문고의 베스트셀러 페이지를 방문하여 첫 페이지 (1위 ~ 20위)의 도서들을 출력하고 있습니다. 교보문고 베스트셀러 페이지의 소스 코드를 확인해보시면 href로 시작하는 부분에서 ~ 사이에 도서의 이름이 나와있으므로 이것을 이용하는 방법입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import java.util.ArrayList;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
public class Main {
static ArrayList<String> lines = new ArrayList<String>();
public static void main(String[] args) {
URL url = null;
BufferedReader input = null;
String address = "http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf";
String line = "";
try {
url = new URL(address);
input = new BufferedReader(new InputStreamReader(url.openStream()));
while ((line = input.readLine()) != null) {
if (line.trim().length() > 0) lines.add(line);
}
input.close();
} catch (Exception e) {
e.printStackTrace();
}
int rank = 1;
int status = 0;
for (int i = 0; i < lines.size(); i++) {
String l = lines.get(i);
if (status == 0) {
if (l.contains("div class=\"detail\"")) status = 1;
} else if (status == 1) {
if (l.contains("div class=\"title\"")) status = 2;
} else if (status == 2) {
if (l.contains("href")) {
int begin = l.indexOf("<strong>") + "<strong>".length();
int end = l.indexOf("</strong>");
System.out.println("rank " + rank + " : " + l.substring(begin, end));
status = 0;
rank++;
}
}
}
}
}
JSOUP
Parsing을 좀 더 간편하게 하기 위해 jsoup이라는 API가 있습니다. Java에 내장된 라이브러리가 아니기 때문에 따로 설치해야하는 번거로움이 있는데요, 여기서 간단하게 설치 방법과 사용 방법을 소개해드리도록 하겠습니다.
jsoup은 jsoup 공식 홈페이지에 방문하여 다운로드 받을 수 있습니다.

링크를 타고 들어가신 후, 가장 위에 보이는 core library를 다운로드 받으시면 됩니다.
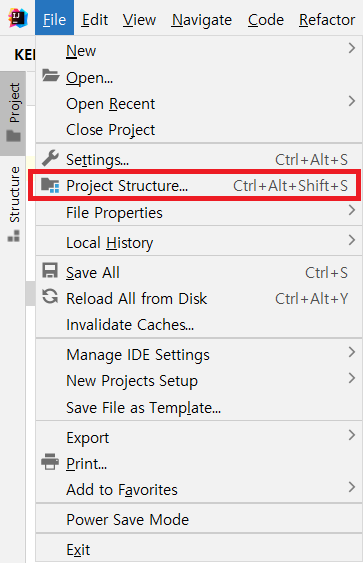
그 다음 IntelliJ IDEA를 실행하신 후, 사용하실 프로젝트를 여신 다음 File - Project Structure 메뉴를 클릭합니다.

Project Structure에서 Modules - 프로젝트 이름 - Dependencies를 순서대로 클릭합니다.

중간에 있는 + 메뉴를 클릭하면 서브 메뉴가 나오는데, 첫 번째인 JARs or Directries를 클릭합니다. 그 후, 방금 다운받은 jsoup core file을 불러오시면 됩니다.
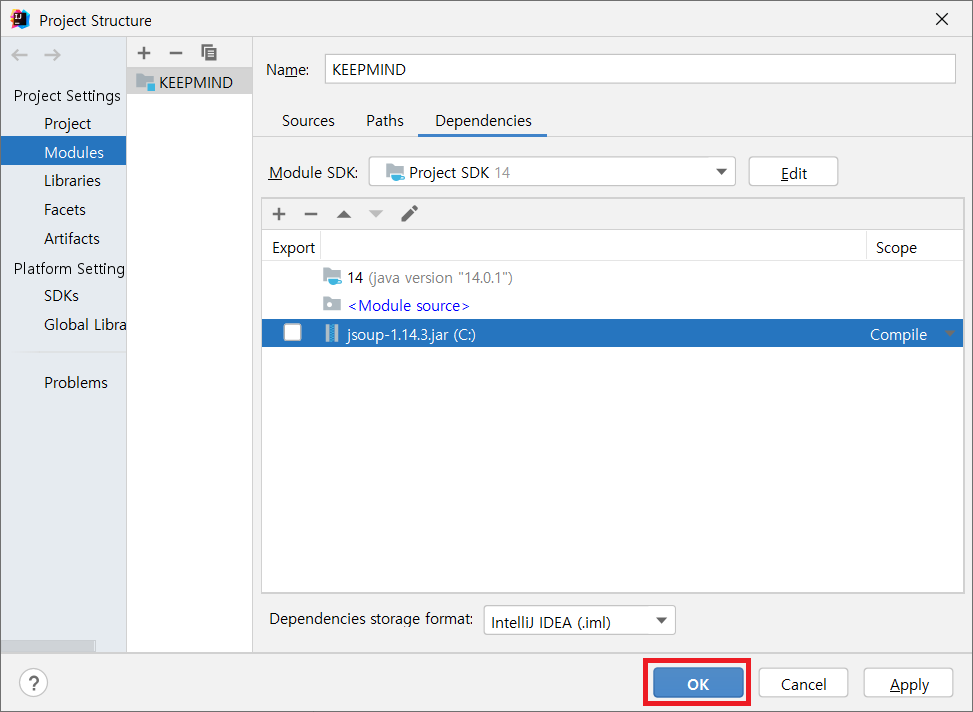
jsoup core file을 정상적으로 불러온 모습입니다. OK 버튼을 클릭합니다.
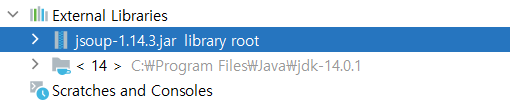
정상적으로 처리되었다면 위처럼 External Libraries에 jsoup이 추가된 것을 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Main {
public static void main(String[] args) throws Exception {
String url = "http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch(IOException e) {
System.out.println(e.getMessage());
}
Elements bestsellers = doc.select("div.detail");
Elements titles = bestsellers.select("div.title");
Elements booktitles = titles.select("a[href]");
for(int i=0; i<booktitles.size(); i++) {
System.out.println("rank " + i+1 + " : " + booktitles.eq(i).text());
}
}
}
위의 예제는 URL에서의 네 번째 예제인 Parsing과 같은 기능을 하는 프로그램입니다. 마찬가지로 교보문고에서 베스트셀러 1~20위까지의 도서들을 출력해줍니다.
프로그램을 천천히 분석해보면, 먼저 try-catch 블록은 Jsoup.connect() 라는 메소드를 사용하여 URL을 연결하고 있습니다. Connection 클래스는 get() 이라는 메소드를 가지고 있는데, 이것은 Document 타입의 객체를 반환합니다. 이것이 doc가 Document 객체로 정의된 이유입니다. Document 클래스는 Element 클래스의 서브 클래스입니다.
InetAddress나 URL 클래스와 마찬가지로 매개변수 url 주소가 존재하지 않을 수 있기 때문에 try-catch 블록을 사용하여 필수적으로 예외를 처리해주셔야 합니다. 이 때 발생할 수 있는 예외는 MalformedURLException, HttpStatusException, UnsupportedMimeTypeException, SocketTimeoutException, IOException 입니다.
다음으로 select() 메소드는 HTML 파일로부터 데이터를 추출하는 기능은 갖고 있습니다. select 메소드는 Element 클래스에 정의되어 있으며, 프로토타입은 Elements select(String cssQuery) 로 정의되어 있습니다. context에서 매개변수로 들어온 CSS query와 일치하는 요소를 찾도록 설계되어 있습니다.
예제의 15번째 Line에서는 <div class="detail"> 로 시작하는 부분을, 16번째 Line에서는 <div class="title"> 로 시작하는 부분을, 17번째 Line에서는 <a href=...>로 시작하는 부분을 찾는다는 뜻이 됩니다.
select 메소드에서 매개변수에 들어갈 수 있는 종류들은 다음과 같습니다.
- tagname : tag로 element를 찾는다 (ex. a)
- ns|tag : namespace에서 tag로 element를 찾는다 (ex. fb|name 이면 <fb:name>을 찾음)
- #id : ID로 element를 찾는다. (ex. #logo)
- .class : class 이름으로 element를 찾는다 (ex. .masthead)
- [attribute] : attribute로 element를 찾는다. (ex. [href])
- [^attr] : attribute 접두사로 element를 찾는다. (ex. [^data-] 면 HTML5 attribute element를 찾음)
- [attr=value] : attribute 값으로 element를 찾는다. (ex. [width=500])
- [attr^=value], [attr$=value], [attr*=value] : attribute 값으로 시작하는/끝나는/포함하는 element를 찾는다. (ex. [href*=/path/])
- [attr!=regex] : regular expression과 일치하는 attribute 값으로 element를 찾는다. (ex. img[src!=(?i).(png|jpe?g)])
- * : 모든 element를 찾는다. (ex. *)
이번 포스트는 여기까지입니다. 생각보다 내용이 조금 길어졌네요. 다음에는 오늘 내용에 이어서 Networking with Java 두 번째 포스트로 찾아뵙겠습니다. 읽어주셔서 감사합니다!
Leave a comment