
Three Learning Principles

17장은 기계학습에서 중요한 3가지 원칙에 대해 소개합니다.
Outline

각각의 주제는 이번 장의 제목과 같이 3가지 원칙을 하나씩 나열하고 있습니다. Occam’s Razor는 Learning Model과 관련이 있는 주제이고 Sampling Bias는 데이터 수집(Collecting), Data Snooping은 데이터 처리(Handling)에 관련이 있는 주제입니다.
Occam’s Razor

Occam’s Razor를 설명하기 전에, 먼저 아인슈타인의 말을 인용하면서 시작합니다.
“데이터에 대한 설명은 가능한 한 단순해야 하지만, 더 단순해서는 안됩니다.”
이것이 바로 Occam’s Razor의 기본 아이디어입니다. 이것과 면도날이 왜 관련이 있는지 궁금하실 수도 있는데, 만약에 면도기로 설명을 깎는다고 생각해봅시다. 우리가 어떤 물건을 10개의 문장으로 설명하고 있다고 합시다. 그런데 그 설명을 깎아 5개의 문장만으로 동일한 설명이 가능하다고 하면, 그것이 더 좋은 설명이라는 논리입니다.
이렇게 되면 인용구의 뒷 소절인 더 단순해서는 안됩니다의 의미가 궁금해집니다. 이것은 만약에 설명을 더 깎을 수 있더라도, 그것이 원래의 의미를 퇴색시킨다면 그렇게는 하면 안 된다는 의미입니다.

이 아이디어를 기계학습으로 가져와봅시다. 기계학습에서 Occam’s Razor를 한 문장으로 정리하면 다음과 같습니다.
“데이터에 맞는 가장 간단한 모델은 가장 타당하기도 합니다.”
문장은 멋있지만, 이것에 대한 의미를 해석하려면 그 전에 먼저 두 가지 질문에 대답해야 합니다.
- Model이 단순하다는 것은 어떤 의미인가?
- 이 말이 맞다는 것을 어떻게 알 수 있나? (=성능 측면에서 단순할수록 더 좋다는 것을 어떻게 알 수 있나?)
이 궁금증에 대해 하나씩 풀어보도록 합시다.
※ Occam’s Razor는 기계학습에서만 사용하는 용어가 아니기 때문에, 좀 더 일반적인 뜻을 알고 싶으시다면 위키백과를 함께 읽어보시는 것을 추천드립니다.

첫번째 질문부터 생각해봅시다. 단순하다라는 것은 정확히 무엇을 의미할까요?
Complexity (복잡성)를 측정할 때는 기본적으로 두 가지 유형이 있습니다. 첫 번째는 Object의 복잡성입니다. 기계학습에서는 가설 $h$나 최종 가설 $g$를 의미합니다. 두 번째로는 Set of Object의 복잡성입니다. 이것은 기계학습에서 가설 집합 $\mathcal{H}$를 의미합니다.
가설 $h$의 Complexity의 예로는 Minimum Description Length (MDL), 다항식의 차수 등이 있습니다. MDL은 Object를 만들고 가능한 한 적은 Bit로 표현하는 것을 말합니다. 예를 들어, 100만에서 1을 뺀 수를 가정해보겠습니다. 이를 숫자로 표현하면 999999 입니다. 100만에서 1을 뺀 수와 999999 중에 어떤 방법이 더 간단하게 표현하는 것일까요? 당연히 전자가 더 편리한 표현임을 쉽게 알 수 있습니다.
다항식의 차수는 더 간단합니다. 17차 다항식과 100차 다항식이 있다고 하면 높은 차수의 다항식이 더 복잡한 모델임을 이미 알고 있습니다. 이것은 11장에서 Deterministic Noise를 통해 배웠습니다.
다음으로 가설 집합 $\mathcal{H}$의 Complexity의 예로는 Entropy와 VC Dimension이 있습니다. VC Dimension은 7장에서 이미 다루었기 때문에 넘어가겠습니다. Entropy는 Information Theory에 나오는 개념으로, 정보량을 측정하는 척도를 의미합니다. 가장 유명한 식으로 Shannon’s Entropy가 있는데, 지금 중요한 부분은 아니니 여기서는 생략하겠습니다.
다시 원래의 질문으로 돌아오면, 일반적으로 단순하다에 대해 언급할때는 첫 번째인 가설 $h$의 단순함을 일컫는 것입니다. 하지만 Occam’s Razor를 수학적으로 증명할 때 언급하는 단순함은 가설 집합 $\mathcal{H}$의 단순함을 말하는 것입니다.
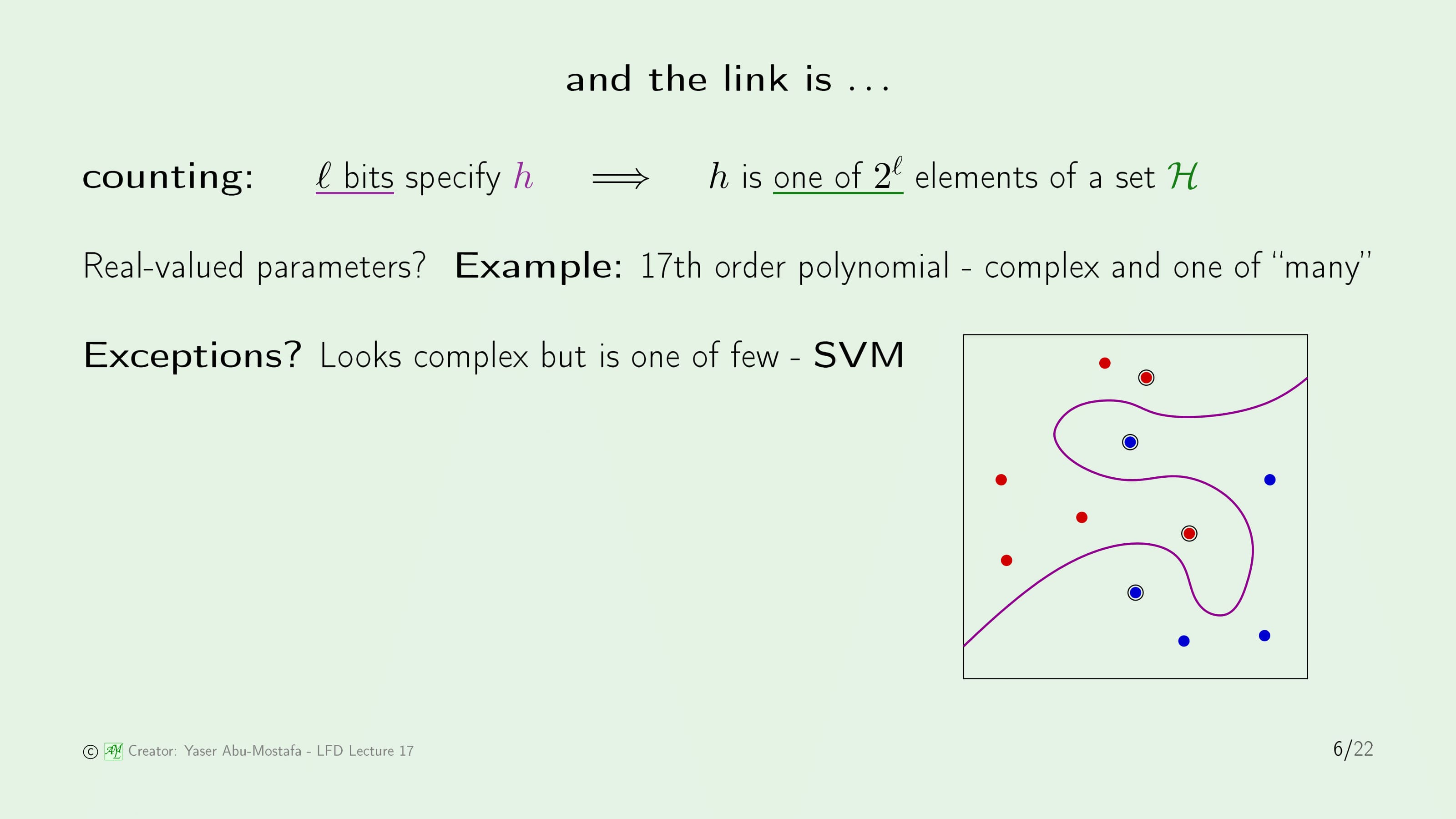
그렇다면 가설 $h$의 Complexity와 가설 집합 $\mathcal{H}$의 Complexity 사이에는 어떤 관련이 있는지 알아봅시다.
먼저, 가설 $h$를 특정하기 위해서는 $l$ bit가 필요하다고 가정해봅시다. 이 가정에서 가설 $h$의 복잡도는 $l$ bit가 됩니다. 이것을 가설 집합 $\mathcal{H}$에 관련지어 표현하면, 가설 $h$는 가설 집합 $\mathcal{H}$의 $2^l$개의 원소 중 하나가 된다고 말할 수 있습니다.
이것을 기계학습과 연관지어 예를 들어보면, 17차 다항식을 생각해봅시다. 17차 다항식을 특정하기 위해서는 17개의 Parameter가 필요하기 때문에 가설 집합 $\mathcal{H}$는 무한대가 됩니다. 그렇기에 이것은 복잡하다라고 말할 수 있습니다.
이 규칙에는 예외가 있는데, 복잡해 보이지만 실제로는 그렇지 않은 SVM이 있습니다. 오른쪽의 그림을 보시면 SVM으로 나눈 평면은 굉장히 복잡해 보이지만, 실제로는 극소수의 Support Vector로 정의되기 때문입니다.

이와 관련해서 간단한 퍼즐을 하나 풀어보도록 하겠습니다.
매주 월요일 저녁에 축구 경기가 있다고 가정합시다. 그런데 어느 월요일 아침, 당신 앞으로 편지가 한통 왔습니다. A팀과 B팀이 경기하는데 A팀이 이길 것이라는 내용입니다. 아직 경기가 있기 전이고, 대부분이 B팀의 승리를 예측했기 때문에 당신은 편지의 내용을 믿지 않았지만, 실제로 그날 경기는 A팀이 이기게 됩니다.
다음 주 월요일 아침, 또 동일한 사람에게 편지가 왔습니다. 역시 그 날 저녁의 축구 경기 결과를 예측하는 내용이었으며, 또 맞춰버리고 말았습니다. 이렇게 5주 연속 편지가 왔고, 5주 내내 편지에서는 그 날의 축구 경기 결과를 정확하게 예측하였습니다.
그런데 6주 째가 되었을 때, 또 편지가 왔지만 이번에는 다른 내용이었습니다. 축구 경기 예측 결과를 더 보고 싶으면 50달러를 지불하라는 내용이었습니다. 이런 상황에서, 당신은 그 가격을 지불할 것인가요?
정답부터 말씀드리면 당연히 지불해서는 안됩니다. 만약에 편지를 보내는 사람이 처음엔 32명을 대상으로 절반은 A팀 승리/나머지 절반은 B팀 승리로 적어서 편지를 보내고, 맞은 쪽에만 다시 절반은 A팀 승리/나머지 절반은 B팀 승리라는 편지를 보내는 과정을 반복했을지도 모르기 때문입니다.
그렇기 때문에 기계학습에서는 예측 값이 의미가 없습니다.

이제 두 번째 질문을 해결해봅시다. 왜 단순한 것이 더 좋을까요? 여기서 더 좋다는 의미는 우아해 보인다는 것이 아니라 Out of Sample에서의 성능이 더 좋다는 의미입니다.
이것에 대해 더 엄밀한 증명은 이상적인 상황을 가정하지만, 여기서는 증명의 요점만을 짚고 넘어가겠습니다.
- 단순한 가설이 복잡한 가설보다 적다. (이것은 5장에서 Growth Function을 통해 배웠습니다)
- 단순한 가설은 주어진 데이터 셋에 맞추기 더 적합하지 않다.
- 그렇기 때문에 단순한 가설이 데이터 셋에 맞춰지는 일이 발생한다면, 그것이 더 중요하다.
방금 전에 다루었던 우편 퍼즐의 Growth Function을 생각해보면, 편지를 받는 당신은 자신만 그러한 편지를 받았다고 생각했었지만 (일어나기 힘든 일), 현실적으로는 가능한 모든 경우를 고려해서 편지를 보낸 것 (무조건 일어나는 일)이기 때문에 의미가 없던 것이었습니다.
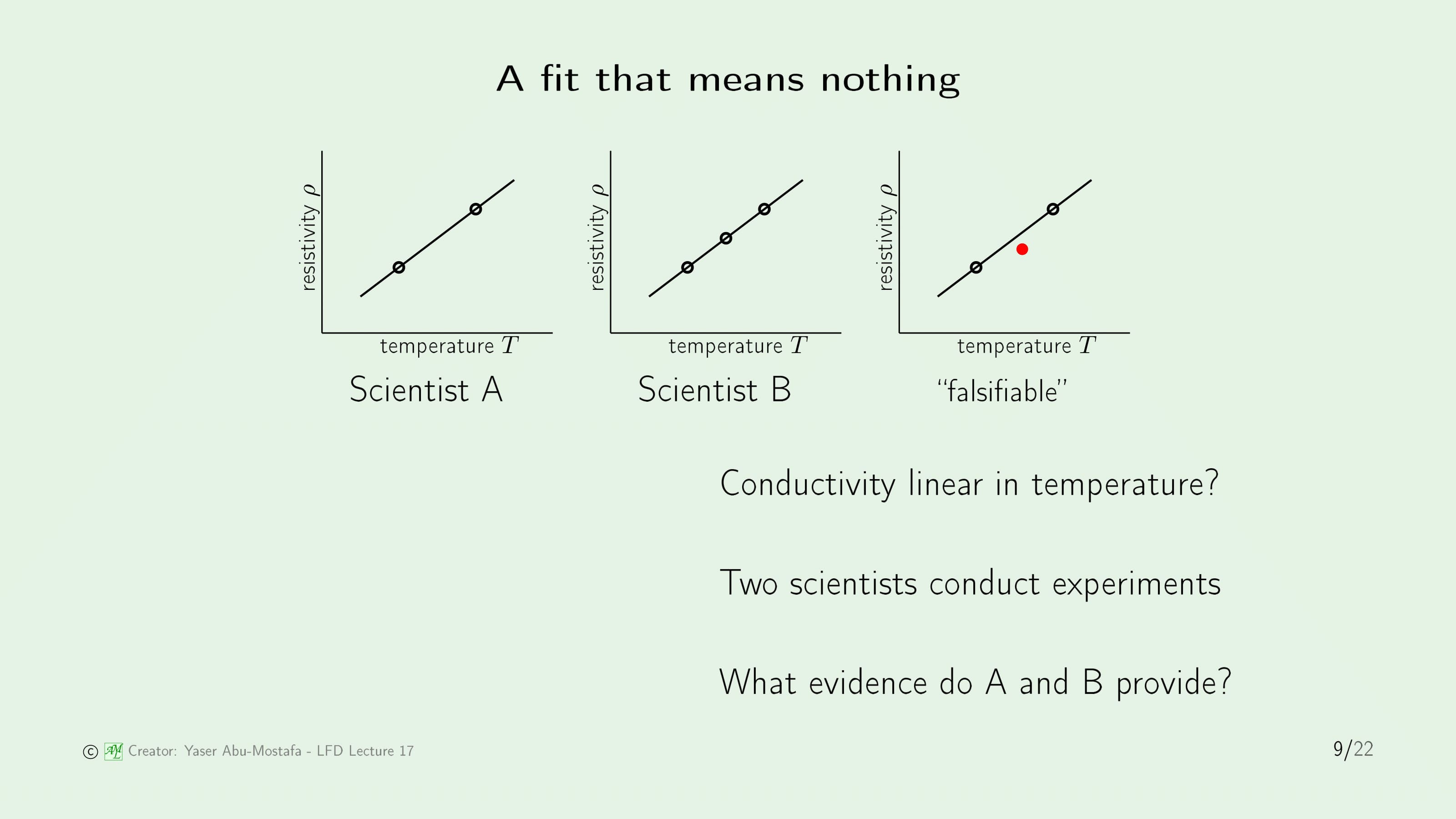
적합이 무의미한 과학 실험을 살펴보겠습니다. 실험의 주제는 어떤 특정한 금속의 Conductivity (전도성)이 Temperature (온도)에 선형이라는 가설을 증명하는 것입니다. 이 주제를 가지고 두 명의 과학자가 실험을 하였습니다.
과학자 A는 두 지점에서 실험을 하였고, 그 둘을 잇는 선을 그렸습니다.
과학자 B는 세 지점에서 실험을 하였고, 그 셋을 잇는 선을 그렸습니다.
Conductivity (전도성)이 Temperature (온도)에 선형이라는 가설을 더 명확하게 밝힌 사람은 누구인가요? 오래 생각하지 않더라도 과학자 B가 더 많은 정보를 제공하는 것을 알 수 있습니다. 왜냐하면, 과학자 A가 제시한 2개의 점은 항상 선으로 연결할 수 있기 때문입니다.
이와 관련된 개념을 Falsifiable (위조 가능성)이라고 합니다. 과학자 A가 제시한 그래프는 사실 위 슬라이드의 3번째 그림처럼 선을 벗어난 점이 있을 수 있기 때문입니다.
Sampling Bias

다음으로는 데이터 수집에서 발생할 수 있는 문제인 Sampling Bias에 대해 알아보겠습니다.

두 번째 퍼즐은 1948년에 일어났던 미국 대통령 선거입니다. 당시 후보는 Truman과 Dewey 였는데, 한 신문사가 선거가 끝난 직후 당선자를 예측하기 위해 여론조사를 실시하였습니다. 여론조사의 방법은 무작위 사람에게 전화를 걸어 누구에게 투표했는지 물어보는 것이었습니다.
여론조사를 해보니 오차를 감안하더라도 Dewey가 확실하게 Truman을 이긴다는 결론을 내렸고, 사진과 같이 Dewey가 Truman을 이겼다고 신문에 실었습니다.

그런데 문제는 실제로 Truman이 당선되었다는 것입니다.
더 이상한 것은 통계의 산출 방법이 틀리지 않았다는 것입니다. 충분한 양의 표본을 모았고, 결과를 계산하는 과정도 아무런 문제가 없었습니다.
단순히 운이 없어서 이런 일이 발생했다고 생각할 수도 있지만, 그렇지 않았습니다. 신문사는 데이터 표본을 10배, 100배 늘린다고 해도 똑같은 결과가 나올 것이라고 판단했기 때문입니다.

그렇다면 이 여론 조사의 문제점은 무엇일까요? 바로 표본에 Bias (편향)가 있었습니다. 지금이야 누구나 휴대폰을 갖고 있지만, 1948년에는 전화기 자체가 비싼 물건이었기 때문에 전화를 갖고 있다는 것 자체가 부유한 계층이라는 뜻이었기 때문입니다. 부유한 사람들에게만 여론 조사를 했기 때문에, 부유한 사람이 많이 지지했던 Dewey에게 투표한 사람이 많았고, 그 결과 표본 자체가 부유한 사람들의 의견만을 반영한 결과가 나온 것입니다.
“만약 데이터가 편항된 방식으로 수집된다면, 학습은 비슷하게 편향된 결과를 낳는다.”
학습은 사용자가 제공한 데이터를 통해 세상을 봅니다. 사용자가 비뚤어진 데이터를 준다면, 학습 또한 사용자에게 비뚤어진 가설을 줍니다.
이와 비슷한 또 하나의 예제를 보겠습니다. 재무 예측에서 기계학습은 많이 사용되는 방법입니다. 당신은 시장의 정상적인 기간을 구하려고 합니다. 실제로 사람들이 사고팔 때 특정한 패턴이 존재합니다. 만약에 실제 시장에서 일어나는 Live Trading를 데이터로 사용한다면, 이것은 데이터 편향이 존재한다고 말할 수 있습니다. 왜냐하면 Live Trading 이외의 부분은 어떠할지 전혀 알 수 없기 때문입니다.

Sampling Bias를 처리하는 한 가지 방법은 분포를 일치시키는 것입니다. 실제로 많이 사용하는 방법인데, Input Space에 분포가 있다고 가정하는 것입니다. Hoeffding’s Inequality와 VC Analysis에서는 Training과 Testing이 같은 분포를 갖고 있다고 가정하였습니다. 그렇기에 이 경우 Sampling Bias가 존재하면 가정에 위배되므로 문제가 발생합니다.
따라서 애초부터 Training과 Testing의 분포가 동일하지 않다고 가정하는 것입니다. 그래서 Training과 Testing의 분포를 일치시키기 위해 Training Data에 가중치를 부여하거나, 또는 Resampling 할 수도 있습니다. 단순한 방법이지만, 이 방법을 사용하면 Sampling Bias를 처리할 수 있다고 합니다.
하지만 만약 Training에서의 확률은 0인데, Testing에서의 확률이 0보다 큰 경우에는 사용할 수 없다고 합니다. 방금 보았던 미국의 대선이 바로 이것을 설명하는 예시인데, 전화기가 없는 사람이 실제(Testing)에서는 확률이 0보다 크지만 표본(Training)에서는 확률이 0이었기 때문입니다. 이 때는 확률이 0인 부분에서 어떤 일이 일어날 지 알 수 없기 때문에 데이터에 가중치를 부여하는 등의 작업이 불가능함을 알 수 있습니다.

3번째 퍼즐은, 이 상황에서의 Sampling Bias를 찾아내는 것입니다.
은행에서 고객의 신용카드 발급을 자동으로 승인하는 시스템을 만드려고 합니다. 이전에 신청한 고객들의 과거 기록을 기반으로 새 고객의 신용 정보 (오른쪽 표와 같은)을 입력받았을 때 이 사람이 은행에 이익을 가져다 줄지(=신용카드를 발급해줘도 괜찮은지)를 판단하는 시스템입니다.
혹시 Sampling Bias가 어디서 일어나는지 찾으셨나요? 바로 이전에 신청한 고객들의 과거 기록입니다. 이들은 이미 은행에서 신용카드를 발급해준 대상자들입니다. 그러니까, 신용카드 발급을 거절당한 사람들의 기록은 고려되지 않는 것입니다.
그런데 사실 이것은 Sampling Bias가 크게 문제 되지 않는 상황이기도 합니다. 은행은 신용카드를 발급해줄 때 어느 정도의 위험성(ex. 고객이 카드를 쓰고 돈을 갚지 않는 상황)을 감수해야 하기 때문에, 다소 보수적으로 기준을 잡기 때문입니다.
Data Snooping

마지막 주제로 Data Snooping에 대해 이야기해봅시다.

이번에는 원칙을 먼저 설명한 후에 이야기가 진행됩니다.
“만약 데이터 집합이 학습 과정의 어떤 단계라도 영향을 미쳤다면, 결과를 평가하는 능력은 손상된다.”
이것은 실무자들에게 가장 흔하게 발생하는 실수라고 합니다. 이전에 9장에서도 Data Snooping에 대해 이야기한 적이 있었는데, 그 때는 데이터를 먼저 보고 모델을 선택했을 때 발생하는 실수라고 언급하고 넘어갔습니다. 하지만 이것은 Data Snooping에 빠질 수 있는 경우의 수 중 한 가지에 불과하며 실제로는 이런 함정에 빠지는 방법이 많다는 것입니다.
이제 Data Snooping이 일어날 수 있는 몇 가지의 예를 확인할 것입니다. 전에 보았던 예도 있지만, 그렇지 않은 것들도 있습니다. 이 예들을 통해 무엇을 피해야 하며 어떤 종류의 Data Snooping이 있는지 보겠습니다.

이전에 배웠던 Nonlinear Transform으로 시작해봅시다. 오른쪽 그림은 9장에서 Data Snooping을 처음 언급할 때 나왔던 예제입니다. 이때 2차식을 사용하여 Transform 하는 방법으로 문제를 풀었고, 그 결과 $\mathbf{z}$는 6차원의 벡터가 되었습니다.
문제는 이것을 보고 더 간단하게 표현하고 싶어 $\mathbf{z}$를 직접 손댔을 때 발생했습니다. 이렇게 하면 VC Dimension이 3이기 때문에 더 좋다고 생각할 수 있습니다. 하지만 이렇게 함으로써 실제로 하는 일은 데이터가 아닌, 사용자 스스로 학습하게 일이 되어 버립니다.
Data Snooping은 데이터 집합 $\mathcal{D}$와 관련이 있습니다. 그렇기 때문이 주어진 데이터 집합에서는 잘 수행될지 모르지만, 독립적으로 생성된 다른 데이터 집합에서도 잘 수행될지의 여부는 알 수 없습니다.
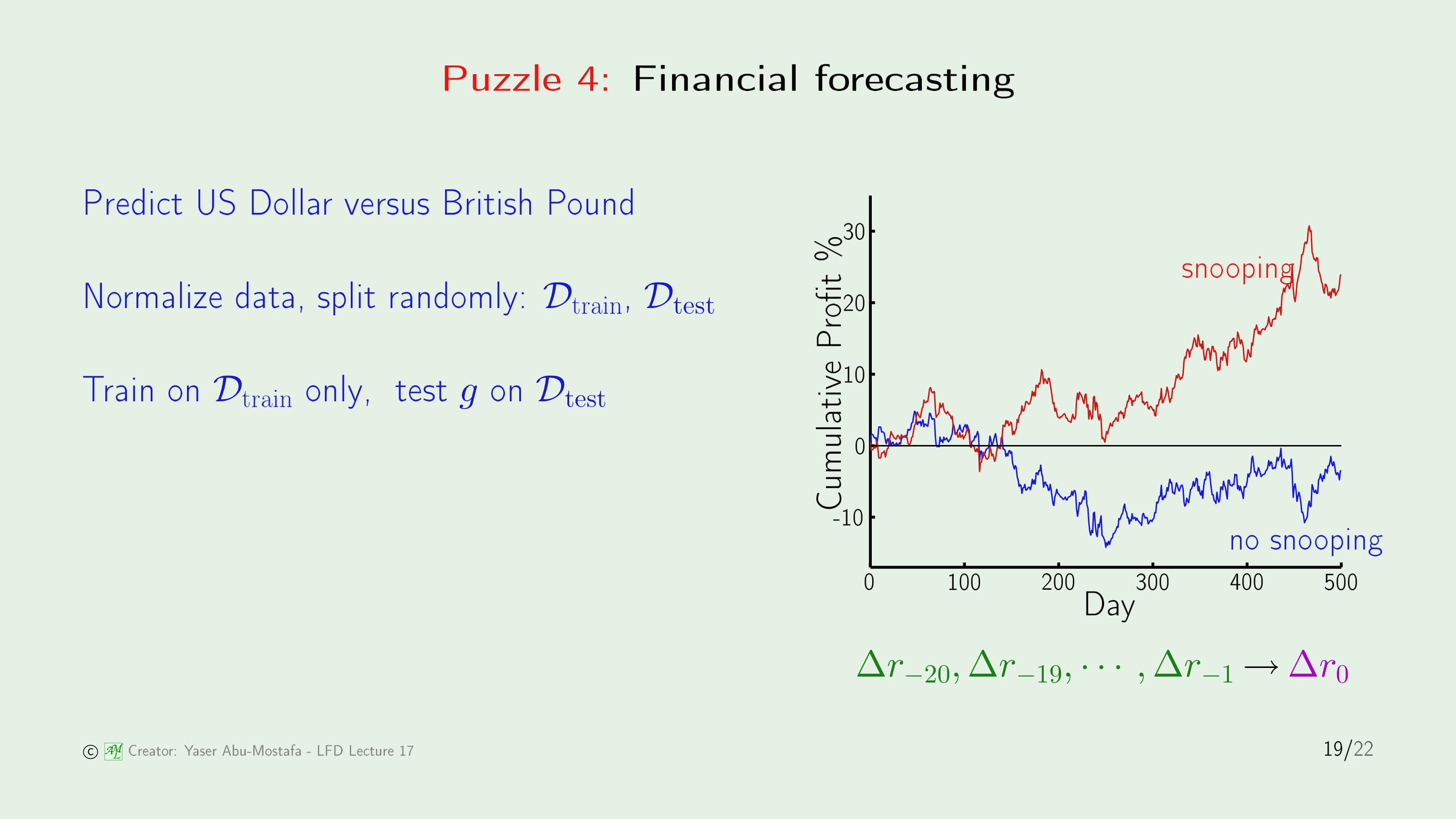
또 퍼즐이 나왔습니다. 4번째 퍼즐은 재무 예측 문제에서 Data Snooping이 일어나는 곳을 찾는 것입니다.
이것은 미국 달러와 영국 파운드 사이의 환율을 예측하는 문제입니다. 여기 8년 분량의 일일 거래 자료가 있습니다. 오른쪽 하단의 초록색 $\Delta r$은 오늘을 기준으로 20일 전까지 일어났던 예측 오율입니다.
가장 먼저 데이터를 평균과 단위 분산이 0이 되도록 Normalize합니다. 총 2000여 일간의 데이터 중 1500일을 Training Set으로 사용하고, 500일을 Testing Set으로 사용합니다. 물론 두 집합 모두 무작위로 추출합니다.
이 과정에서 사용자는 어떤 데이터도 눈으로 보지 않았습니다. 방금까지 설명한 모든 과정을 자동으로 수행한 다음, Training Data를 통해 최종 가설을 세우고 Test Set에서 그 성능을 확인합니다. 그 결과 오른쪽 그래프의 빨간 선처럼 우상향 곡선을 그리게 됩니다.
지금까지 봤을 때, 어느 지점에서도 Data Snooping이 일어나지 않은 것 같습니다. 하지만 분명히 이 과정에서 Data Snooping이 일어났고, 그렇기에 실제 예측 (파란색 곡선)과 큰 차이가 벌어진 것입니다.
정답을 말씀드리면, Data Snooping은 Data를 Normalize 할 때 발생하였습니다. Normalize 자체가 잘못된 것은 아닙니다. Normalize를 하는 과정에서 Test Set이 포함되었기 때문에, 다시 말해 Training Set이 Test Set에 영향을 주었기 때문에 Data Snooping이 일어난 것입니다. 올바르게 Normalize를 하기 위해서는, 데이터를 먼저 Training Set과 Test Set으로 나눈 다음 Normalize를 해야 합니다.

Data Snooping의 또 다른 이름은 Reuse of a Data set (데이터 집합의 재사용) 입니다. 만약 사용자가 어떤 데이터 집합을 가지고 이것저것 학습모델을 사용하다 보면 언젠가는 학습에 성공할 것입니다. 이 말은 다시 말하게 되면,
“만약 당신이 데이터를 충분히 오래 고문하면, 결국에는 자백한다.”
여기서 자백한다는 의미는 결과적으로 아무 의미가 없다는 뜻입니다.
왜 문제가 발생하는지 예를 들어봅시다. 만약에 사용자가 카드 발급을 승인해주는 문제를 푼다고 가정해봅시다. 사용자는 데이터를 전혀 보지 않았고, 정규화시키지도 않았습니다. 그런데 사용자는 우연히 인터넷에서 글을 보다가 카드 발급 승인 문제에서 SVM이 가장 효과가 뛰어나다는 사실을 발견했습니다. 이것을 보고 사용자가 자신도 SVM을 사용하겠다고 결정하면, 데이터를 보지 않았더라도 그 영향을 받은 사실을 사용했기 때문에 문제가 되는 것입니다.
이것에 대한 핵심적인 문제는 바로 특정한 데이터 집합을 너무 잘 일치시킨다는 사실입니다.

Data Snooping에는 두 가지 해결책이 있습니다. 하나는 Data Snooping을 피하는 것[…]이고 다른 하나는 Data Snooping을 설명하는 것입니다.
Data Snooping을 피하기 위해서는 엄격한 훈련이 필요하다고 합니다. 말은 정말 간단합니다. 만약 이것이 쉽지 않다면 두 번째 방법으로, 데이터가 얼마나 오염되었는지를 알아야 한다고 합니다. 물론 그냥 알기만 하면 안되고, 이전에 데이터 분포를 일치시켰던 것처럼 그에 맞는 대처를 해 주어야 합니다.

드디어 마지막 퍼즐입니다. 주식에서 장기간 Buy and Hold (=장기 투자) 했을 때의 성능을 테스트하려고 합니다. 이를 위해 여기서는 50년간의 데이터를 사용합니다. 이를 확인하기 위해 다음과 같은 방법을 사용합니다.
먼저, 현재 거래되는 모든 주식 회사를 대상으로 합니다. 만약에 50년 전에 당신이라면, 어떤 주식을 구매할 것인지 스스로 판단하고, 50년 후 (즉, 현재) 얼마가 되어있을지를 계산하는 겁니다.
이 간단한 작업에도 Sampling Bias가 생겼습니다. 현재 거래되는 주식은 50년 전에 분명히 있었지만, 50년 전에 있던 주식회사 중 망한 회사는 선택에서 배제되었기 때문입니다. 문제는 이 과정은 (50년 전을 기준으로) 미래의 데이터를 보고 결정한 것이기 때문에 Sampling Bias 보다는 Data Snooping과 혼동이 생긴다는 것입니다. 여기에서는 두 가지 성질을 모두 가지고 있으므로, Snooping으로 인한 Sampling Bias라고 결론지었습니다.
이번 장은 여기까지입니다. 읽어주셔서 감사합니다.
Leave a comment