
Subprograms

9장의 주제는 부프로그램입니다. 다룰 내용은 부프로그램의 매개변수 전달 방법, 지역 참조 환경, 중복 부프로그램 등이 있습니다. 여기서는 부프로그램에 대해서만 알아보고, 부프로그램을 구현하는 방법은 다음 장에서 자세히 다룰 예정입니다. 이번 장의 핵심 문구는 다음과 같습니다.
“부프로그램은 프로그램의 기본 요소이므로 프로그래밍 언어 설계에서 가장 중요한 개념 중 하나입니다”

프로그래밍 언어에 포함되는 기본적인 두 개의 추상화는 프로세스 추상화와 데이터 추상화입니다. 데이터 추상화는 11장에서 다룰 예정이고, 이번 장에서 다룰 부프로그램이 바로 프로세스 추상화에 해당합니다.
부프로그램의 개념은 배비지(Babbage)의 해석기관에서 유래했습니다. 해석기관은 프로그램이 다양한 장소에서 명령어의 묶음을 재사용하는 능력이 있었는데, 현대 프로그래밍 언어에서는 이를 부프로그램으로 구현하였습니다. 이러한 재사용은 메모리 공간과 코딩 시간을 절약하는 장점이 있습니다.
해당 명령어의 묶음을 호출(Call)하는 명령어를 통해 프로그램에 명령어의 묶음을 배치하는 것은 곧 추상화로 볼 수 있습니다. 왜냐하면 명령어 묶음의 세부 사항이 부프로그램으 호출하는 문장 하나로 대치되기 때문입니다.
프로시저와 매크로는 비슷하면서도 차이가 있는데, 매크로는 함수 호출이나 반환과 같은 오버헤드가 발생하지 않지만 프로그램 길이가 길어질 수 있는 문제가 있습니다. 짧은 코드라면 매크로가 유리하지만, 긴 코드라면 프로시저를 이용하는 것이 좋습니다.

먼저 부프로그램의 기초부터 알아보겠습니다. 일반적인 부프로그램의 특성은 다음과 같습니다.
- 각각의 부프로그램은 단일 진입점을 갖는다.
- 호출 프로그램 단위는 호출된 부프로그램이 실행되는 동안 일시중지된다. 즉, 주어진 시간 동안 실행 중인 부프로그램은 1개만 존재한다.
- 부프로그램 실행이 종료되면 제어가 항상 호출한 프로그램으로 돌아간다.
이러한 가정은 코루틴(Coroutine)과 동시성(Concurrency)에서 예외가 있습니다만, 이것은 해당 장에서 구체적으로 다루겠습니다.
부프로그램의 정의는 부프로그램 추상화의 인터페이스와 동작을 서술하는 것입니다. 부프로그램 호출(Subprogram Call)은 부프로그램이 실행되도록 명시적으로 요청하는 것이고, 부프로그램이 호출된 후 실행을 시작했지만 아직 끝나지 않은 경우에는 활성화(Actice)되었다고 합니다.

부프로그램 헤더(Subprogram Header)는 첫 줄에 선언되는 부프로그램의 정의입니다. 이것은 부프로그램 이름과 함께 매개변수 목록을 지정하는데 사용합니다.
Fortran 언어에서는 SUBROUTINE 이라는 명령어를 사용하여 헤더를 정의하고, Ada 언어에서는 procedure ~ is 명령어를 이용하여 헤더를 정의합니다. 함수는 값을 반환하고 프로시저는 명령어를 실행하는 차이가 있지만, C 언어는 함수(Function)라는 한 종류의 부프로그램만 있습니다. 대신 헤더를 보고 그 함수가 값을 반환하는지 안하는지를 알 수 있습니다.

부프로그램이 데이터에 접근할 수 있는 방법은 두 가지가 있습니다. 하나는 비지역 변수로의 직접적인 접근과, 나머지 하나는 함수의 매개변수를 통해 접근하는 방법입니다. 비지역 변수를 통한 접근은 프로그램의 신뢰성을 감소시키기 때문에 매개변수를 통해 데이터를 전달하는 방법이 권장됩니다.
어떤 상황에서는 부프로그램의 매개변수로 데이터가 아닌 계산이 전달되는 것이 편리합니다. 이런 경우에는 계산을 구현하는 부프로그램의 이름이 매개변수로 사용됩니다. 이것은 나중에 9.6절에서 더 자세히 알아보겠습니다.
매개변수는 형식 매개변수(Formal Parameter)와 실 매개변수(Actual Parameter)로 나눌 수 있습니다. 형식 매개변수는 부프로그램 머리부에서 선언되는 매개변수입니다. 이 변수는 일반적인 의미의 변수가 아니기 때문에 독립 변수로 간주됩니다. 이런 변수들은 보통 부프로그램이 호출될 때만 기억장소에 바인딩되고, 이 바인딩도 다른 프로그램 변수를 통해 이루어집니다. 부프로그램의 형식 매개변수에 바인딩되는 부프로그램 호출의 매개변수를 실 매개변수라고 합니다.

매개변수를 전달할 때, 매개변수의 위치에 따라 실 매개변수를 형식 매개변수에 바인딩하는 방법을 위치 매개변수(Positional Parameter)라고 합니다. 매개변수 리스트가 짧은 경우에는 이 방법이 효율적이고 안전한 방법입니다,
만약 매개변수 리스트가 길다면 프로그래머는 매개변수를 작성하는 도중 오류를 범할 가능성이 높습니다. 이 문제를 해결하는 방법은 키워드 매개변수(Keyworkd Parameter)를 이용하는 것입니다. 키워드 매개변수에서는 실 매개변수가 바인딩될 형식 매개변수의 이름을 함께 호출하는 방식으로 지정합니다. 예를 들어, 슬라이드에 나온 것처럼 Ada 언어에서 LENGTH => MY_LENGTH와 같이 형식 매개변수 LENGTH에 실 매개변수 MY_LENGTH를 직접 지정해주는 방식입니다. 이 방법의 단점은 프로그래머가 부프로그램의 형식 매개변수의 이름을 반드시 알고 있어야 한다는 것입니다.
C++ 언어나 Ada에서는 형식 매개변수가 기본값(Default Value)을 가질 수 있습니다. 기본값은 부프로그램을 호출할 때 실 매개변수가 전달되지 않는 경우 사용됩니다. 예를 들어, 슬라이드의 코드와 같이 EXEMPTION의 기본값은 정수 1로 설정되어 있습니다. 만약 이 부프로그램을 호출할 때, 이 매개변수가 생략된다면 자동으로 1이 들어가게 됩니다.
형식 매개변수의 기본값을 지원하지 않는 경우, 호출의 실 매개변수의 수는 반드시 부프로그램 헤더에서 정의한 형식 매개변수의 수와 일치해야 합니다. 그러나 C 언어는 이것이 필수가 아닙니다. 예를 들어, C 언어의 printf 함수는 가변 개수의 매개변수를 허용하기 때문에 임의의 개수의 항목을 출력합니다.

부프로그램은 프로시저(Procedure)와 함수(Function)로 나눌 수 있습니다. 이 둘의 가장 큰 차이는 반환값이 있느냐 없느냐의 여부입니다. 프로시저는 값을 반환하지 않지만, 함수는 값을 반환합니다. 이 두 역할이 명백하게 구분되어 있는 언어도 있지만, C 언어는 함수 한 가지만 존재하는 대신 함수에 반환값을 설정하지 않아서 프로시저처럼 사용할 수 있게 구현되어 있습니다.
프로시저는 매개변수화된 계산을 정의하는 명령문의 모음입니다. 프로시저는 값을 반환하지 않기 때문에 호출자에게 결과를 전달할 수 있는 방법이 매우 제한되는데, 대표적인 방법이 프로시저 내에서 보이는 변수를 변경하거나, 호출자에게 데이터 전달을 허용하는 형식 매개변수를 갖는다면 그것을 변경시키는 방법입니다.
함수는 요구되는 실 매개변수와 함께 표현식에서 이름으로 나타남으로써 호출됩니다. 함수에 의해 생성된 값은 효율적으로 호출을 대체하면서 호출 코드로 반환됩니다. 함수를 통해 새로운 사용자 정의 연산을 정의할 수 있습니다. 예를 들어서, 어떤 언어가 지수 연산자를 갖지 않는다면 이를 수행하는 함수를 만들 수 있습니다. Fortran와 같은 언어에서는 지수 연산을 지원하기 때문에 굳이 이것을 함수로 구현할 필요가 없습니다. 대부분의 언어에서는 프로그래머가 새로운 함수를 정의함으로써 연산자를 중복하는 것을 허용하는데, 이것은 9.12 절에서 자세하게 다루겠습니다.

부프로그램은 프로그래밍 언어에서 복잡한 구조를 갖고 있기 때문에 그만큼 설계에 고려할 사항이 많습니다.
- 매개변수의 전달 방법은 무엇을 사용할 것인가?
- 형식 매개변수의 타입과 실 매개변수의 타입에 대해 타입 검사를 수행할 것인가?
- 지역 변수는 정적으로 할당되는가, 동적으로 할당되는가?
- 매개변수로 전달된 부프로그램의 참조 환경은 무엇인가?
- 부프로그램을 매개변수로 전달할 수 있는 경우, 전달된 부프로그램에 대한 호출에서 매개변수 타입을 검사하는가?
- 부프로그램이 오버로딩 될 수 있는가?
- 부프로그램이 제네릭일 수 있는가?
- 부프로그램이 분리된 컴파일, 또는 독립적인 컴파일이 가능한가?

부프로그램 내에서 선언된 변수를 지역 변수(Local Variable)이라고 합니다. 지역 변수에 대한 접근은 일반적으로 해당 변수가 선언된 부프로그램으로 제한됩니다. 5장에서 다룬대로, 지역 변수는 정적(Static)이거나 스택 동적(Stack Dyanmic)입니다. 지역 변수가 스택 동적이라면, 지역 변수는 부프로그램이 실행을 시작할 때 기억공간에 바인딩되고, 실행이 종료되면 저장소에서 해제됩니다.
스택 동적 지역 변수의 장점은 유연성입니다. 특히, 재귀적 부프로그램을 만들기 위해서는 스택 동적 변수가 필수적입니다. 그 외의 장점은 활성 부프로그램에 있는 지역 변수의 기억 장소가 다른 모든 비활성 부프로그램의 지역 변수와 같은 공간을 공유하므로 저장공간을 아낄 수 있다는 것이지만, 기억공간이 충분히 늘어난 지금은 큰 장점이라고 보진 않습니다.
스택 동적 지역 변수의 단점은 부프로그램이 호출될 때마다 지역 변수를 할당, 초기화, 해제하는 시간이 소모된다는 것입니다. 또한 간접 주소 방식을 통해 기억 공간에 접근하므로 접근 속도가 느리다는 단점이 있습니다. 또한 과거 민감형(History-sensitive)이 아니므로 호출 사이에 지역 변수에 데이터 값을 유지할 수 없다는 단점이 있습니다.

반대로 정적 지역 변수를 사용한다면 매우 효율적이라는 장점이 있습니다. 기본적으로 프로그램이 실행될 때 저장공간에 바인딩되기 때문에 할당이나 해제에 실행 시간 부담이 없고, 접근이 빠르며 과거 민감형 부프로그램을 허용한다는 것입니다. 그러나 재귀를 허용하지 않고 기억공간을 다른 비활성 부프로그램의 변수들과 공유할 수 없다는 단점도 있습니다.
ALGOL 60과 그 후속 언어들에서 지역 변수는 기본적으로 스택 동적으로 구현되어 있습니다. 그러나 C 언어 같은 경우에는 static 이라는 명령어를 이용하여 정적 변수로 선언할 수 있는 옵션을 제공합니다. Fortran 77의 경우에는 재귀가 없기 때문에 모든 지역 변수가 정적 지역 변수입니다.

다음은 이번 장에서 가장 중요한 매개변수 전달 방법에 대해 알아보겠습니다.
형식 매개변수는 3개의 의미적 모델 중 하나로 결정됩니다.
- 형식 매개변수가 해당 실 매개변수로부터 데이터를 받는다. (in mode)
- 형식 매개변수가 데이터를 실 매개변수에 전달한다. (out mode)
- 형식 매개변수가 실 매개변수로부터 데이터를 받고, 반대로 데이터를 실 매개변수에 전달한다. (inout mode)
데이터 이동이 매개변수 전달에서 일어나는 방법은 두 가지 개념적인 모델이 있습니다.
- 실제 값이 물리적으로 이동된다.
- 접근 경로(포인터나 참조)가 이동한다.

세 가지의 기본 매개변수 전달 모드의 구현을 위해, 다양한 모델이 언어 설계자에 의해 개발되었습니다. 여기서 소개하는 것은 그 중 많이 고려되는 5가지의 매개변수 전달 모델을 소개합니다.
첫 번째 모델은 매개변수를 값으로 전달하는 Pass by Value 입니다. Pass by Value에서 실 매개변수의 값은 해당 형식 매개변수를 초기화하는데 사용되며, 이 매개변수는 부프로그램에서 지역 변수로 간주됩니다. 따라서, Pass by Value는 in mode의 의미가 구현된 것으로 볼 수 있습니다. Pass by Value는 보통 데이터를 복사하는 것으로 구현합니다. 왜냐하면 Pass by Value에서 실 매개변수가 가지고 있는 값은 쓰기로부터 보호가 되어야 하기 때문입니다. 따라서 매개변수가 배열과 같이 큰 개체인 경우에는 이것을 기억공간에 복사하는데 많은 비용이 들 수 있습니다.

두 번째 모델은 out mode의 의미를 구현한 Pass by Result 입니다. 매개변수가 전달될 때, 어떠한 값도 부프로그램에 전달되지 않습니다. 이 때 매개변수는 지억 변수로 작동하긴 하지만, 제어가 호출자에게 반환되기 직전에 그 값이 호출자의 실 매개변수에 전달됩니다. Pass by Result도 Pass by Value의 단점을 그대로 갖는데, 실 매개변수로 전달되는 것도 데이터가 복사되어 전달되는 것이기 때문에 추가적인 기억공간이 필요하다는 것입니다.
그런데 Pass by Result는 실 매개변수의 충돌과 같은 추가적인 문제점도 가지고 있습니다. 예를 들어, 슬라이드의 코드와 같이 sub 라는 부프로그램은 x와 y라는 두 가지 형식 매개변수를 가지고 있습니다. 부프로그램 내에서 x에는 3, y에는 5가 배정됩니다. 그런데 main()에서 sub를 호출할 때 실 매개변수로 모두 p1이 들어갑니다. 이 때, 함수 호출이 끝나고 p1에는 어떤 값이 들어가야 할까요? 이 상황에서는 나중에 실 매개변수에 배정되는 것이 p1의 값이 됩니다. (즉, 실 매개변수에 값이 복사되는 순서)
Pass by Result의 또 다른 문제는 구현자가 실 매개변수의 주소를 평가하기 위해 두 개의 다른 시점(호출 시, 복귀 시) 중에서 하나를 선택할 수 있다는 것입니다. 슬라이드 아래쪽에 있는 코드를 보면 list[index]의 주소가 부프로그램 중간에서 변경됩니다. 만약 주소가 부프로그램 진입 시 바인딩된다면 list[3]에 3이 반환될 것입니다. 그런데 반환 바로 전에 바인딩된다면 list[5]에 3이 반환될 것 입니다. 이것은 언어의 구현에 따라 다르기 때문에, 똑같이 Pass by Result를 선택한 언어 사이에도 이식하는 것을 어렵게 만듭니다.

Pass by Value Result는 Pass by Value와 Pass by Result를 결합하여 inout mode를 구현한 것입니다. 실 매개변수의 값은 해당 형식 매개변수를 초기화하는데 사용되며, 그 후 지역 변수로써 사용됩니다. 또한 부프로그램 종료 시 형식 매개변수의 값이 실 매개변수로 다시 복사됩니다. 이 과정은 실 매개변수 -> 형식 매개변수의 복사와 형식 매개변수 -> 실 매개변수의 복사가 이루어지는 방식이기 때문에 Pass by Copy라고 부르기도 합니다.
Pass by Reference는 또 다른 inout mode를 구현한 모델입니다. 그러나 이전 모델들처럼 데이터 값을 복사하는 것 대신에 접근 경로(일반적으로 주소)를 전송합니다. 따라서 부프로그램이 호출자의 실 매개변수에 접근하는 것을 허용합니다. Pass by Reference의 장점은 전달 과정이 시간과 기억공간적 관점에서 효율적이라는 것입니다.

그러나 Pass by Reference에도 단점은 존재합니다. 첫 번째 단점은 형식 매개변수에 접근할 때 한 단계 더 많은 간접 주소를 사용하기 때문에 형식 매개변수에 접근할 때 더 느릴 수 있습니다. 두 번째 단점은 프로그래머의 실수로 인해 잘못된 값이 실 매개변수에 적용될 수 있습니다. 하지만 이 두 가지 단점보다 더 큰 세 번째 단점은 별칭(Alias)를 만들 수 있다는 것입니다. 이것은 Pass by Reference가 부프로그램이 호출자에 접근 가능한 경로를 만들기 때문에 비지역 변수를 건드릴 수 있기 때문에 발생합니다. 별칭은 이전 장에서도 설명했었지만 프로그램의 가독성과 신뢰성에 악영향을 미치고, 프로그램 검증을 어렵게 만듭니다.
슬라이드에 제시된 코드를 통해 어떤 식으로 Pass by Reference에서 별칭이 만들어지는지 확인해 보겠습니다. 왼쪽의 코드에서는 global이 전역 변수로 선언되어있고, local이 smallsub의 형식 매개변수로 선언이 되어 있습니다. 그런데 smallsub를 호출할 때 실 매개변수로 global이 사용되었습니다. 따라서 smallsub 내에서 global과 local은 별칭이 되어 버립니다.
오른쪽의 코드에서는 sub라는 부프로그램에서 first와 second라는 두 개의 형식 매개변수가 정의되었습니다. 그런데 어쩌다가 sub를 호출할 때 두 매개변수에 모두 실 매개변수로 total을 사용했습니다. 이 경우 sub의 first와 second는 별칭이 되어 버립니다.
이러한 별칭 문제는 Pass by Reference가 아니라 Pass by Value Result를 사용하면 해결됩니다. 그러나 이 경우에는 별칭 말고도 다른 문제가 발생하기 때문에 설계자가 전달 방법을 신중하게 선택할 필요가 있습니다.
마지막 모델은 Pass by Name 입니다. 이 방법도 Pass by Value Result나 Pass by Reference와 같은 inout mode를 구현한 모델입니다. 이 방법은 매개변수가 이름으로 전달될 때, 실 매개변수가 부프로그램에 나타나는 해당 모든 형식 매개변수를 그대로 대체합니다.

지금까지 논의한 방법들은 부프로그램을 호출할 때 형식 매개변수의 값이나 주소에 바인딩되었는데, Pass by Name은 전혀 다른 방법을 사용하여 inout mode를 구현하였습니다. Pass by Name에서 형식 매개변수는 부프로그램 호출 시에 바인딩되지만, 값이나 주소의 실제 바인딩은 형식 매개변수에 값이 배정되거나 참조될 때까지 연기됩니다. (늦은 바인딩)
Pass by Name의 구현은 매우 어려운데, 실 매개변수의 타입에 따라 구현 방법이 결정되기 때문입니다. 예를 들어, 변수를 전달할 때는 Pass by Reference와 같은 방법을 사용하고, 상수를 전달할 때는 Pass by Value와 같은 방법을 사용합니다. 배열을 전달할 때가 매우 골치아픈데, 이 때는 형식 매개변수를 참조할 때마다 변경될 수 있습니다. 예를 들어, 슬라이드 내에 있는 코드를 확인해봅시다. LIST는 2개의 원소가 있는 배열로 정의가 되었고, GLOBAL은 전역 변수입니다. SUB가 호출되기 전에 GLOBAL에는 1이 배정되므로 SUB가 호출될 때는 SUB(LIST[1])이 됩니다. SUB 내의 첫 명령어인 PARAM 에 3을 대입하는 것은 당연히 LIST[1]에 배정됩니다. 그런데 그 다음 줄에는 GLOBAL의 값을 1 증가시키는 명령어가 있습니다. Pass by Name은 형식 매개변수가 참조될 때마다 변경되므로, 다음 줄의 PARAM := 5는 LIST[2] := 5가 됩니다.

Pass by Name에서 발생하는 또 다른 문제를 알아봅시다. 왼쪽 코드를 보시면 swap이라는 프로시저가 있습니다. 이 프로시저는 FIRST와 SECOND를 매개변수로 받아 두 개의 값을 서로 교환하는 작업을 수행합니다. 만약 오른쪽의 윗부분 예시처럼, KK, II라는 두 개의 정수가 매개변수로 들어온다면 문제없이 수행됩니다. 그런데 만약 그 아래의 코드처럼 I와 A[I]가 매개변수로 들어오면 어떻게 될까요? I에 A[I]값이 먼저 삽입되기 때문에, A[I]에 TEMP의 값이 들어가는 것이 아니라 A[A[I]]에 TEMP의 값이 들어가게 됩니다.
Pass by Name은 높은 유연성을 가지지만, 그로 인해 프로세스 속도가 느리고, 구현이 어려우며, 프로그램의 가독성과 신뢰성을 낮추는 문제가 있습니다.

Jensen’s Devices는 Pass by Name을 활용하여 하나의 프로시저를 다양한 목적으로 사용하기 위한 방법입니다. 식과 식에 나타나는 한 개 이상의 변수를 매개변수로 부프로그램에 전달하는데, 부프로그램에서 매개변수의 변수 중 하나가 변경될 때마다 해당 변경으로 인해 형식 매개변수의 값이 변경될 수 있습니다.
Jensen’s Devices의 대표적인 예는 바로 합을 계산하는 프로시저입니다. 예제 코드에서 나온 SUM 프로시저는 ADDER, INDEX, LENGTH 3개의 매개변수를 받아 INDEX가 LENGTH에 도달할 때까지 TEMPSUM에 ADDER를 더합니다. 이 프로시저는 얼핏 보면 단순하지만, 매개변수에 따라 다양한 계산을 수행할 수 있습니다.
- 만약
SUM(A, I, 100)으로 호출한 경우, 100 * A 계산을 수행 - 만약
SUM(A[I], I, 100)으로 호출할 경우, 배열 A의 1부터 100까지의 합 계산을 수행 - 만약
SUM(A[I] * A[I], I, 100)으로 호출할 경우, 배열 A 제곱의 1부터 100까지의 합 계산을 수행 - 만약
SUM(A[I] * B[I], I, 100)으로 호출할 경우, 배열 A와 B의 곱을 1부터 100까지의 합 계산을 수행

Jensen’s Devices의 아이디어는 식과 식에 사용된 하나 이상의 변수를 모두 서브루틴에 전달하는 것입니다. ALGOL 60이 대표적으로 Call by Name을 사용하는데, ALGOL 60은 Call by Name을 구현하기 위해 호출자의 참조 환경에서 실 매개변수를 평가하는 숨겨진 서브루틴을 전달하는 방법을 사용했습니다. 이러한 숨겨진 루틴을 일반적으로 Thunk라고 부릅니다.

개별 변수의 값을 변경함으로써, 호출된 루틴은 내장된 표현식의 값을 의도적이고 체계적으로 변경할 수 있습니다. 이러한 장치는 합산 루틴을 작성하는 데 사용할 수 있습니다.
그러나 사실 Pass by Name을 이렇게 영리하게 사용하는 경우는 매우 드물며, 이러한 방법은 Pass by Name 아닌 다른 매개변수 전달로도 충분히 구현할 수 있습니다. 게다가, 형식 매개변수를 사용할 때마다 Thunk를 호출하는 비용이 엄청나다는 것이 입증되었기 때문에 ALGOL 68에서는 이러한 전달 방법이 삭제되었습니다.

그렇다면 주요 언어들에서 매개변수 전달 방법을 어떻게 사용하고 있는지 알아보겠습니다.
먼저 Fortran 언어는 Fortran 77 이전까지 Pass by Reference를 사용하다가, Fortran 77부터는 Pass by Value Result를 사용하는 것으로 변경되었습니다. ALGOL 60은 이전 슬라이드에서도 언급했듯이, Pass by Name을 사용했습니다. SIMULA-67 또한 마찬가지로 Pass by Name을 사용했습니다.
그러나 ALGOL 68과 C 언어부터는 Pass by Value를 사용하기 시작했습니다. 만약 매개변수를 변경할 필요가 있을 때는 포인터 타입을 사용함으로써 Pass by Reference와 같은 효과를 얻을 수 있습니다. 이 언어들의 특징은 형식 매개변수를 나열할 때, 매개변수의 이름 옆에 매개변수의 타입을 같이 선언하는 문법을 가지고 있습니다.
ALGOL W의 경우에는 Pass by Result를 사용합니다.

Pascal 언어와 Modula-2 언어의 경우는 조금 특이한데, 기본적으로 Pass by Value로 매개변수를 전달하지만, var 이라는 예약어를 사용하여 형식 매개변수를 정의한다면 Pass by Reference로 전달합니다.
Ada 언어는 이보다 더 특이하게 기술적으로 이 문제를 접근했습니다. Ada 언어는 매개변수 앞에 in/out/in out 예약어를 붙임으로써 매개변수가 전달되는 방법을 구분합니다. 각각 in mode / out mode / in out mode를 의미합니다.
이전에는 실 매개변수의 타입이 형식 매개변수의 타입과 같은지 확인하는 절차가 따로 없었으나, 최근에는 이것을 검사하는 것이 소프트웨어의 신뢰성을 높인다고 알려져 있습니다.

Fortran 77나 초창기 C 언어 같은 초기 프로그래밍 언어는 매개변수 타입 검사를 요구하지 않았습니다. 그러나 그 이후 개발된 Pascal, Modula-2, Fortran 90과 같은 언어들은 매개변수의 타입 검사를 실시합니다.
ANSI C 언어는 조금 특이한 방식을 가지고 있습니다. 만약 함수를 선언할 때 형식 매개변수에 타입을 작성하지 않으면, 초창기 C 언어와 마찬가지로 타입 검사를 하지 않습니다. 물론 C 언어에 기반했기 때문에 프로그램 내에서 해당 형식 매개변수의 타입을 명세하기는 하지만, 그렇다고 실 매개변수와 타입이 같을 필요는 없습니다.
만약 함수를 선언할 때 형식 매개변수의 타입을 작성하면 타입 검사를 수행합니다. 만약 타입 검사 후에 타입이 다르더라도, int - double과 같이 같은 숫자형 변수라면 강제 변환(Coercion)이 일어납니다. 만약 변환이 가능하지 않거나 매개변수의 개수가 틀리다면 오류가 발생합니다.
C++ 언어(C99 포함)는 ANSI C와는 다른 방식으로 타입 검사를 피할 수 있습니다. 형식 매개변수를 선언할 때, 생략 기호(Ellipsis)를 사용하면 매개변수의 개수나 타입 검사를 피할 수 있습니다. 예를 들어, 교재에 나온 코드인 printf 함수의 경우 적어도 한 개의 매개변수가 필요합니다. 그 외에는 몇 개의 매개변수를 갖던 상관이 없습니다.

이제 매개변수 전달 방법을 구현하는 방법에 대해 알아보겠습니다. ALGOL 60을 비롯한 그 후속 언어들에서는 실행 시간 스택(Run-time Stack)을 이용하여 매개변수를 연결하였습니다.
-
Pass by Value에서 매개변수는 그 값이 스택에 복사됩니다.
-
Pass by Result에서 매개변수는 실제 매개변수가 스택에 배치되고, 호출된 부프로그램이 종료할 때 부프로그램에서 사용된 형식 매개변수와 일치하는 실제 매개변수를 스택에서 검색하여 매칭됩니다.
-
Pass by Value Result는 Pass by Value와 Pass by Result를 합친 것으로 구현합니다.
-
Pass by Reference는 실 매개변수의 타입에 관계 없이 그 주소가 스택에 배치되어야 합니다. 컴파일러는 호출된 부프로그램으로 제어권을 넘기기 전에 식을 평가하는 코드를 작성해야 합니다. 해당 식의 코드 결과가 스택이 배치되는 주소입니다.
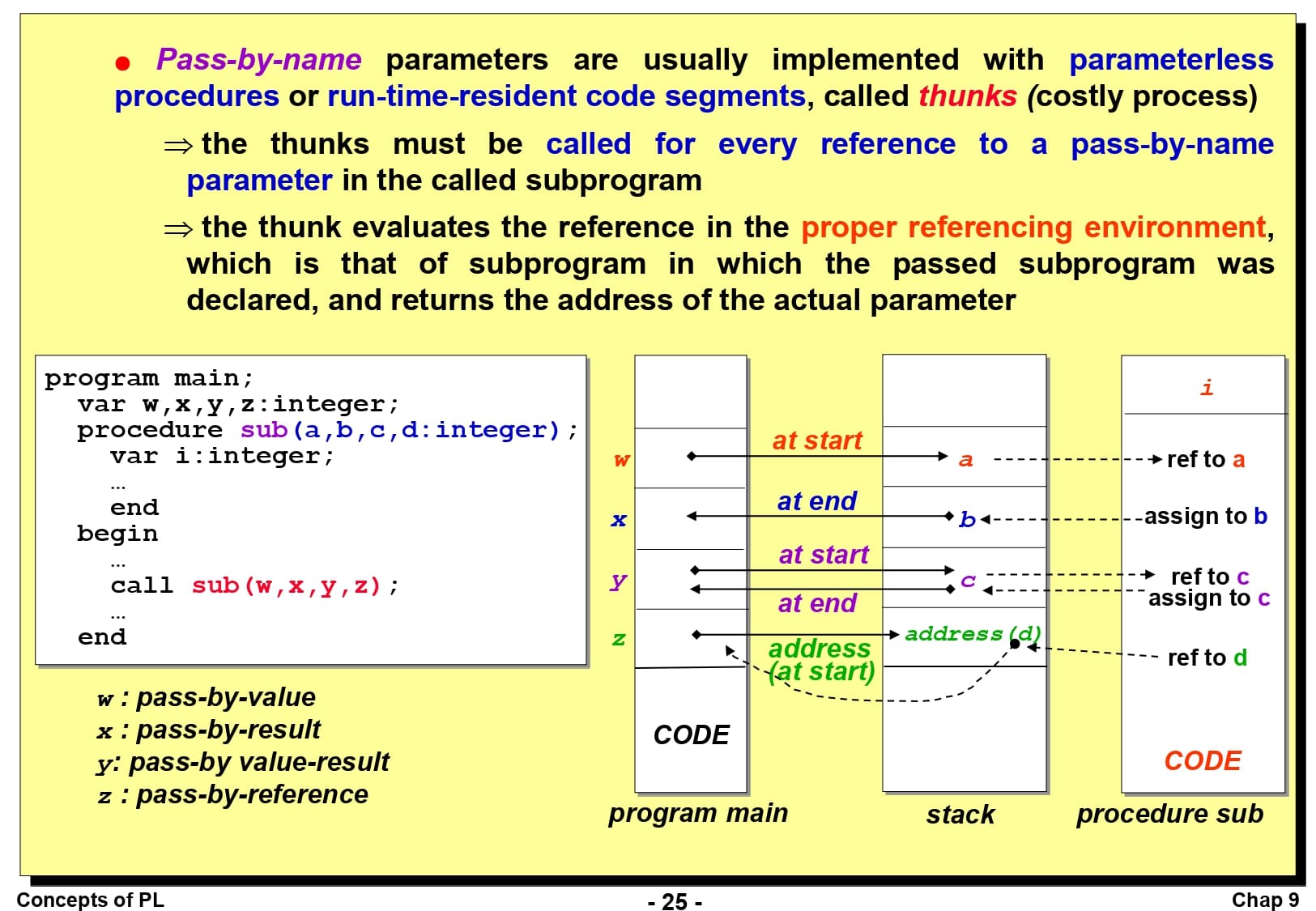
Pass by Name은 이전 방법들과 구현 방법이 상이합니다. 크게 2가지 방법으로 나눌 수 있는데, 매개변수가 없는 프로시저로 구현하거나 실행 시간 상주 코드 세그먼트인 Thunk로 구현하는 것입니다. (후자의 경우가 훨씬 많이 사용됨)
호출된 부프로그램의 Pass by Name 매개변수에 대한 모든 참조에 대해 Thunk를 호출해야 합니다.
Thunk는 전달된 부프로그램이 선언된 부프로그램의 적절한 참조 환경에서 참조를 수행하고, 실 매개변수의 주소를 반환합니다.

매개변수 전달 방법을 선택하는데는 두 가지 고려사항이 있습니다. 하나는 효율성이고, 하나는 단방향 데이터 이동과 양방향 데이터 이동의 선택입니다. 현대 소프트웨어 공학(Software Engineerning)에서는 부프로그램 밖에 있는 데이터는 부프로그램 내에서 접근을 최소화하는 것을 지향하고 있습니다. 따라서 일반적으로는 in mode를 사용하는 것이 권장됩니다.
그런데 이러한 원리와 상충되는 고려사항도 있습니다. 예를 들어, 크기가 큰 배열이 Pass by Value로 전달될 경우, 배열 전체가 실행 시간 스택에 들어가야 하는 문제가 있습니다. 이것은 시간적으로도, 공간적으로도 부담이 크기 때문에 배열은 Pass by Reference로 전달되는 경우가 있습니다. 따라서 Ada 언어나 C++ 언어는 이것을 사용자에게 선택하게끔 하고 있습니다.
다음은 부프로그램을 다른 부프로그램의 매개변수로 전달하는 방법에 대해 알아보겠습니다. 언뜻 보면 이 개념은 자연스럽고 당연한 것처럼 보이지만, 동작하는 과정은 복잡합니다. 단지 부프로그램의 코드만 전달하는 것으로도 구현은 가능하지만, 이렇게 구현하게 되면 2가지 문제점이 발생합니다.
첫 번째 문제는 매개변수로 전달된 부프로그램의 매개변수 타입 검사 문제입니다. 두 번째 문제는 중첩된 부프로그램을 허용하는 경우 발생합니다. 바로 전달된 부프로그램을 실행시키기 위해 어떤 참조 환경이 사용되어야 하는가의 문제인데, 다음 슬라이드에서와 같이 세 가지 방법이 존재합니다.

-
첫 번째 참조 환경은 전달된 부프로그램을 실행시키는 호출문의 환경인 얕은 바인딩(Shallow Binding)입니다.
-
두 번째 참조 환경은 전달된 부프로그램의 정의 환경인 깊은 바인딩(Deep Binding)입니다.
-
세 번째 참조 환경은 부프로그램을 실 매개변수로 전달한 호출문의 환경인 애드혹 바인딩(Ad-hoc Binding)입니다.
이러한 참조 환경의 차이를 알아보기 위해 슬라이드에 나와있는 코드를 확인해보겠습니다. 코드에서는 SUB1 -> SUB3 -> SUB4 -> SUB2 순서대로 프로시저가 호출됩니다. 주의할 것은, SUB3 내에 SUB4(SUB2)와 같이 프로시저가 중첩되어 있다는 것입니다.
만약 얕은 바인딩이 사용된다면, SUB2 내에서 사용되는 변수 x는 SUB4의 변수에 바인딩됩니다. 따라서 이 경우 출력이 4가 나옵니다.
만약 깊은 바인딩이 사용된다면, 구조적으로 상위에 있는 변수를 참조하므로 SUB1의 x에 바인딩됩니다. 따라서 이 경우 출력이 1이 나옵니다.
만약 애드혹 바인딩이 사용된다면, 자신(SUB2)을 호출하기 직전에 정의되었던 x에 바인딩됩니다. 따라서 이 경우 직전에 정의된 SUB3의 x 값인 3이 출력됩니다.
일반적으로 정적 바인딩을 가지는 언어는 텍스트의 위치만으로 쉽게 결정할 수 있는 깊은 바인딩을 사용하고, 동적 바인딩을 가지는 언어는 얕은 바인딩을 사용합니다. 애드혹 바인딩은 잘 사용되지 않습니다.

오버로드된 부프로그램(Overloaded Subprogram)은 같은 참조 환경에서 다른 부프로그램들과 이름이 같은 부프로그램입니다. 주의할 점은, 이름은 같지만 매개변수의 개수나 순서, 타입, 반환 타입 등은 다른 부프로그램들과는 달라야 합니다. 오버로드된 부프로그램이 어떤 부프로그램인지는 실 매개변수의 리스트에 의해 결정되기 때문입니다.
Ada 언어에서는 함수와 프로시저 모두 오버로드된 부프로그램을 허용합니다.

C++ 언어의 함수는 매개변수의 개수나 타입이 고유하다면 오버로드가 가능합니다. 컴파일러는 매개변수의 타입으로 모호함을 해결하는데, 이 과정이 생각보다 복잡합니다. 특히, C++ 언어는 매개변수의 강제 변환을 허용하기 때문에 모호함을 해결하는 것이 매우 어렵습니다. 또한 기본 매개변수도 모호함을 일으키는 요소 중 하나입니다. 예를 들어, 슬라이드에 주어진 코드에서는 두 개의 fun() 함수가 존재합니다. 그런데 위의 fun() 함수는 기본 매개변수로 실수형 매개변수 b를 가지고 있습니다. 그런데 기본 매개변수는 함수를 호출할 때 생략하는 것이 가능하므로, 만약 함수를 호출할 때 fun()이라고 호출하면 기본 매개변수를 생략한 첫 번째 fun()을 호출한 것인지, 아니면 두 번째 fun()을 호출한 것인지 알 수가 없습니다. 따라서 이 경우 모호함을 일으켜 컴파일 오류를 발생시킵니다.
제네릭 부프로그램(Generic Subprogram)은 매개변수가 다른 값일 뿐만 아니라 다른 타입을 가질 수 있게 일반적인 타입으로 정의할 수 있습니다. 이것은 소프트웨어를 재사용할 수 있게끔 가능하게 만들어 생산성을 증가시키는 이점이 있습니다. 보통 제네릭 부프로그램은 객체 지향 프로그래밍 언어를 배울 때 다형성(Polymorphism)을 언급하면서 같이 배우곤 합니다.

제네릭 부프로그램을 허용한다면 사용자 프로그램의 요청에 따라 컴파일러가 다양한 버전의 부프로그램을 자동적으로 구성합니다. 제네릭 단위는 단지 프로시저의 템플릿일 뿐, 컴파일러에 의해 코드가 생성되지 않습니다. 따라서 어떤 특정 타입으로 인스턴스화되지 않는 이상, 프로그램에 영향을 전혀 미치지 않습니다.
슬라이드에 있는 코드는 GENERIC_SORT로 정의된 제네릭 부프로그램을 INTEGER_SORT라는 이름으로 인스턴스화하여 INTEGER 유형의 변수를 정렬하는 부프로그램으로 만든 예시입니다. 다만 예시로 나온 코드는 진짜 제네릭 부프로그램은 아닙니다.
C++ 언어에서 제네릭 부프로그램은 Templete이라는 이름을 갖고, Java 언어에서는

Fortran II에서와 같이, 규모가 큰 소프트웨어의 경우 프로그램의 일부만 컴파일하는 기능은 필수적입니다. 컴파일 할 수 있는 프로그램의 일부분을 컴파일 단위(Compilation Unit)라고도 부릅니다.
먼저 부분 컴파일(Separate Compilation)에 대해서 말하자면 부분 컴파일은 매개변수 타입 검사가 필요합니다.
컴파일 단위끼리는 서로 다른 시간에 컴파일될 수 있지만, 만약 해당 컴파일 단위가 다른 컴파일 단위에 접근하거나 영향을 미치는 경우에는 해당 컴파일이 서로 독립적이지 않습니다.
안정적으로 독립적인 컴파일을 수행하기 위해서는 컴파일러가 프로그램의 속성(변수, 타입, 인터페이스를 포함한 부프로그램)에 대한 정보에 접근할 수 있어야 합니다.
Ada 언어에서는 컴파일러가 접근할 수 있는 라이브러리에 이러한 종류의 단위 인터페이스 정보를 유지함으로써 구현하였습니다.
모든 컴파일은 해당 컴파일의 인터페이스 정보를 라이브러리에 배치하게 만듭니다.
Ada, Modula-2, Fortran 90이 이러한 방법을 사용합니다.

독립적인 컴파일(Independent Compilation)은 부분 컴파일과는 다르게 매개변수의 타입 검사를 필요로 하지 않습니다. 따라서 프로그램 유닛은 다른 프로그램 유닛에 대한 정보 없이 컴파일이 가능합니다.
게다가 별도로 컴파일된 유닛간 인터페이스의 일관성을 확인하지도 않습니다.
Fortran 77, C 언어가 이러한 방법을 사용합니다.
다음으로는 함수의 설계 고려 사항에 대해 알아보겠습니다. 함수의 설계 고려 사항에는 다음과 같은 3가지 요소가 있습니다.
- 부작용(Side Effect)이 허용되는가?
- 어떤 타입의 값이 반환되는가?
- 몇 개의 값이 반환될 수 있는가?
먼저 부작용에 대해 생각해봅시다. 5장에서 나왔던대로, 식에서 호출되는 함수의 부작용으로 인해 함수의 매개변수는 항상 in mode여야 합니다. 예를 들어, Ada 언어의 함수는 항상 in mode 형식 매개변수만 가질 수 있습니다. 이러한 제약은 함수가 매개변수에 의한 부작용, 또는 매개변수와 전역 변수의 별칭(Alias)에 의한 부작용이 발생하는 것을 효과적으로 방지합니다.

그러나 Pascal이나 C 언어에서 함수는 Pass by Value 또는 Pass by Reference 매개변수를 가질 수 있으므로 부작용이나 별칭을 발생시키는 함수를 허용합니다.
두 번째 고려사항으로 넘어가면, 대부분의 명령형 언어는 해당 함수에서 반환할 수 있는 타입을 제한하고 있습니다. 몇몇 언어의 반환 타입 제한을 살펴보면 다음과 같습니다.
- Fortran 77 : 함수는 구조화되지 않은 타입만 반환할 수 있음
- Pascal, Modular-2 : 함수가 단순한 타입만 반환할 수 있음 (정수, 실수, 문자, 불리안, 포인터, 열거 타입)
- C : 배열과 함수를 제외한 모든 타입이 함수에 의해 반환될 수 있음 (C++ 언어는 클래스도 반환 가능)
- Ada (+ Python, Ruby) : 모든 타입을 반환할 수 있음
세 번째 고려사항인 반환 값의 개수에 대해 논하자면, 대부분의 명령형 언어는 한 개의 값만 반환이 가능합니다. 그러나 Ruby, Lua, Python 같은 언어는 여러 개의 값이 반환되는 것을 허용합니다.

부프로그램 간에 필요한 소통의 대부분은 매개변수를 통해 수행할 수 있지만, 대부분의 언어는 외부 환경에서 변수에 접근하는 다른 방법을 제공합니다. 부프로그램의 비지역 변수는 부프로그램 내에서 볼 수 있지만, 지역적으로 선언되지 않은 변수입니다.
만약 정적 영역 언어라면, 필요한 것보다 비지역 변수에 대한 더 많은 접근 방법을 제공합니다.
그러나 동적 영역 언어라면, 부프로그램의 모든 지역 변수는 텍스트가 얼마나 가까이 있는지에 상관 없이, 실행중인 다른 부프로그램에서 접근할 수 있습니다.
그러나, 이런 식으로 비지역 변수를 참조할 때는 정적으로 타입을 검사할 수 없습니다.

Fortran 언어는 COMMON이라는 명령어를 통해 전역 저장소 블록에 대한 접근 방법을 제공합니다. COMMON 블록은 블록 이름을 선언하는 첫 번째 COMMON 문이 컴파일러에 의해 발견될 때 생성됩니다. 그런데 만약 두 개의 부프로그램에 이름이 다른 동일한 데이터 블록이 포함될 수 있다는 문제가 존재합니다. 슬라이드에 나온 코드에서도 A/B가 차지하는 영역과 C/D/E가 차지하는 공간이 겹치는 문제점이 발생하였습니다. 이것과 비슷한 이유로, 동적 배열도 COMMON 블록에 넣을 수 없습니다. 따라서 COMMON 블록을 최대한 사용하지 않는 것이 바람직합니다.
Modula-2와 Ada 언어는 접근이 필요한 외부 모듈을 지정할 수 있도록 데이터 공유의 대안적인 방법을 제공합니다. 모든 모듈은 접근이 필요한 다른 모듈을 정확하게 지정할 수 있습니다.

C 언어는 다른 언어들과 다르게 전역 변수는 함수의 정의 외부에서 선언하여 생성할 수 있습니다. 또한 extern 문을 사용하여 다른 파일에 있는 전역 변수를 접근할 수 있습니다.
다음은 마지막으로 사용자 정의 연산자 오버로딩(User-defeind Overloaded Operator)에 대해 알아보겠습니다. Ada, C++, Python과 같은 언어에서는 매개변수의 타입이나 수, 반환 타입이 다르다면 사용자가 연산을 재정의할 수 있습니다.
9장의 내용은 여기까지입니다. 읽어주셔서 감사합니다!
Leave a comment