
Collection Framework (1)
이번 포스트부터 시작해서 앞으로 4개 정도의 포스트에서는 Collection Framework에 대해 다룰 예정입니다. Collection Framework는 Java의 자료구조라고 생각하시면 됩니다. 정확히는 다수의 데이터를 처리할 때 사용하는 미리 정의된 클래스의 집합입니다. Java에서는 크게 3가지 타입의 자료구조가 정의되어 있으며 Interface로 구현되어 있습니다.
List
- List는 순서가 있는 데이터를 처리하며, 데이터의 중복을 허용한다.
- ex) 식당에서 대기하고 있는 고객 명단
- ArrayList, LinkedList, Stack, Vector 클래스로 구현되어 있다.
Set
- Set은 순서가 없는 데이터를 처리하며, 데이터의 중복을 허용하지 않는다.
- ex) 자연수의 집합, 소수(Prime)의 집합
- HashSet, TreeSet 클래스로 구현되어 있다.
Map
- Map은 key-value 쌍으로 이루어진 데이터를 처리하며, 순서가 없고 value의 중복은 허용하나 key의 중복은 허용하지 않는다.
- ex) 주소-우편번호
- HashMap, TreeMap, Hashtable, Properties 클래스로 구현되어 있다.
Interfaces defined in the Collection Framework
먼저 Collection Framework Interface가 어떻게 구성되어 있는지부터 살펴보도록 하겠습니다. 아래 그림을 보시면 List Interface와 Set Interface는 Collection Interface의 subtype으로 분류됨을 알 수 있습니다. 그러나 Map Interface는 이와 별개로 정의된 Interface입니다.
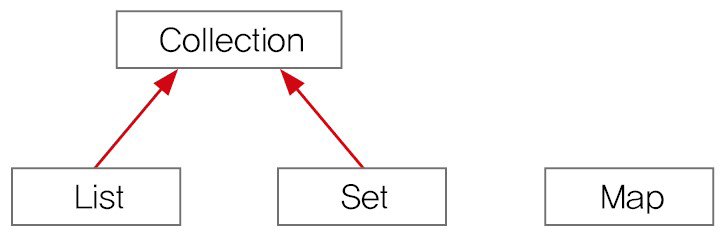
다음으로 Collection
- boolean add(E e) : Collection에 Object를 추가한다.
- boolean addAll(Collection<? extends E> c) : Collection의 Object를 다른 Collection에 추가한다.
- void clear() : Collection에 있는 모든 Object를 삭제한다.
- boolean contains(Object o) : Collection에 Object o가 포함되는지 확인한다.
- boolean containsAll(Collection<?> c) : Collection의 Object o가 다른 Collection에 포함되는지 확인한다.
- boolean equals(Object o) : Collection이 다른 Collection과 같은지 확인한다.
- int hashCode() : Collection의 Hash Code를 반환한다.
- boolean isEmpty() : Collection이 비어있는지 확인한다.
- Iterator iterator() : Collection의 Iterator를 반환한다.
- boolean remove(Object o) : Collection의 Object o를 제거한다.
- boolean removeAll(Collection<?> c) : Collection에서 다른 Collection의 Object를 제거한다.
- boolean retainAll(Collection<?> c) : Collection에서 다른 Collection에 Object를 제외한 나머지를 모두 제거한다.
- int size() : Collection의 Obejct 수를 반환한다.
- Object[] toArray() : Collection에 저장된 Object를 Object Array로 변환하여 반환한다.
-
T[] toArray(T[] a) : Object Array를 Collection Object로 변환한다.
Lists
먼저 List Interface에 대해 자세히 알아보도록 하겠습니다. List는 이전에 설명드린바와 같이 순서가 있는 데이터 집합이며 데이터의 중복을 허용하는 자료구조입니다. 기본적으로 Vector, ArrayList, LinkedList 클래스가 이에 속하며 Stack 클래스는 Vector 클래스의 Sub Class라고 보시면 됩니다.
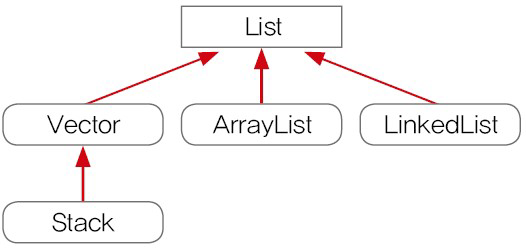
다음으로 List
- void add(int index, E element) : 지정된 index에 E를 삽입한다.
- boolean addAll(int index, Collection<? extends E> c) : 지정된 index에 Collection c의 원소들을 모두 삽입한다.
- E get(int index) : index에 있는 원소를 반환한다.
- int indexOf(Object o) : Object o가 처음 나오는 index를 반환한다. 만약 해당 Object가 존재하지 않는다면 -1을 반환한다.
- int lastIndexOf(Object o) : Object o가 마지막으로 나오는 index를 반환한다. 만약 해당 Object가 존재하지 않는다면 -1을 반환한다.
- ListIterator
listiterator() : List의 Iterator를 반환한다. - ListIterator
listiterator(int index) : 지정된 index에서 시작하는 List의 Iterator를 반환한다. - E remove(int index) : 지정된 index에 위치한 원소를 삭제한다.
- E set(int index, E element) : 지정된 index에 위치한 원소를 element로 변경한다.
- void sort(Comparator<? super E> c) : 지정된 Comparator 순서에 의해 List를 정렬한다.
- List
subList(int fromIndex, int toIndex) : fromIndex부터 toIndex까지의 원소로 새로운 List를 만들어 반환한다.
Sets
다음으로 Set Interface입니다. Set은 중복을 허용하지 않기 때문에 임의의 두 원소를 선택했을 때 동일한 경우가 절때 존재하지 않습니다. 그리고 데이터의 순서가 없습니다. Set Interface의 구조를 도식화하면 다음과 같습니다.
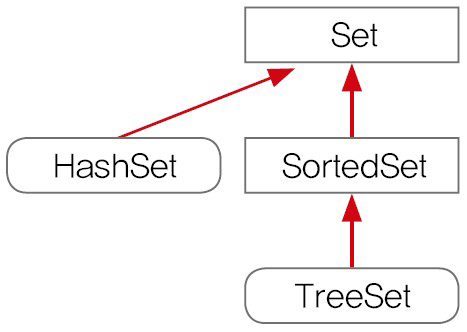
Set
Maps
Map Interface는 key-value의 쌍으로 이루어져 있는 독특한 특징을 가지고 있습니다. value는 중복이 가능하나 key의 중복은 불가능하고, 각 key는 최대 한 개의 value와 mapping 할 수 있습니다. Map Interface의 구조는 다음과 같습니다.
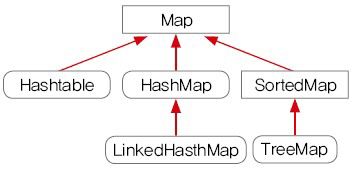
Map<K, V> Interface에 정의된 메소드의 목록입니다. Map Interface는 key와 value가 모두 쓰이다보니 Type variable이 K와 V 2개가 존재합니다.
- void clear() : 이 map에서 모든 mapping을 제거한다.
- boolean containsKey(Object key) : 이 map의 mapping 중 특정 key가 있는지 확인한다. 있다면 true를 반환한다.
- boolean containsValue(Object value) : 이 map에서 value를 mapping하는 원소가 하나 이상 있는지 확인한다. 있다면 true를 반환한다.
- Set<Map.Entry<K, V» entrySet() : 이 map에 포함된 mapping을 모두 반환한다.
- boolean equals(Object o) : Object가 이 map과 동일한지 확인한다.
- V get(Object key) : 지정된 key가 mapping하는 value를 반환한다. 만약 없다면 null을 반환한다.
- int hashCode() : 이 map의 Hash Code를 반환한다.
- boolean isEmpty() : 이 map이 mapping이 하나도 없는지 확인한다. 하나도 없다면 true를 반환한다.
- Set
keySet() : 이 map에 포함된 key 집합을 반환한다. - V put(K key, V value) : 이 map에 포함된 해당 key를 value와 mapping한다.
- void putAll(Map<? extends K, ? extends V> m) : 이 map에 포함된 모든 mapping을 복사한다.
- V remove(Object key) : 이 map에서 key의 mapping을 제거한다.
- int size() : 이 map에 포함된 key-value mapping 갯수를 반환한다.
- Collection
values() : 이 맵에 포함된 Collection view의 값을 반환한다.
Map Interface의 메소드를 보시면 Map.Entry<K, V>라는 Interface가 보입니다. Map.Entry는 Map Interface 안에 정의된 또 다른 Interface입니다. 간략하게 표현하면, 아래처럼 정의되어 있습니다.
public interface Map<K,V> {
...
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
...
}
}
Map.Entry<K, V> Interface에 정의된 메소드를 정리하면 다음과 같습니다.
- boolean equals(Object o) : 지정된 Object와 이 entry가 같은지 비교한다.
- K getKey() : 이 entry에 해당하는 key를 반환한다.
- V getValue() : 이 entry에 해당하는 value를 반환한다.
- int hashCode() : 이 map entry의 Hash Code 값을 반환한다.
- V setValue(V value) : 이 entry의 해당하는 value를 지정된 value로 변경한다.
ArrayLists
이제 각 Collection Framework의 Class들을 하나하나 알아보도록 하겠습니다. 가장 먼저 List Interface로 구현된 ArrayList 입니다. List로부터 구현된 클래스이기 때문에 당연히 리스트처럼 원소의 순서가 있고, 중복이 허락되는 특성도 갖고 있습니다. ArrayList와 관련된 클래스의 정의는 다음과 같습니다.
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
public class AbstractList<E> extends AbstractCollection<E> implements List<E>
public class AbstractCollection<E> extends Object implements Collection<E>
ArrayList와 관련된 클래스는 인스턴스 변수로 Object 배열을 갖고 있으며, 이 때 배열의 크기는 원소의 개수에 따라 자동으로 할당됩니다. 내부에서는 아래와 같이 정의되어 있습니다.
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable {
...
transient Object[] elementData;
...
}
이제 ArrayList를 사용한 예제를 몇 개 살펴보도록 하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import java.util.Collections;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
ArrayList<Integer> list1 = new ArrayList<Integer>(10);
list1.add(Integer.valueOf(5));
list1.add(Integer.valueOf(4));
list1.add(Integer.valueOf(2));
list1.add(Integer.valueOf(0));
list1.add(Integer.valueOf(1));
list1.add(Integer.valueOf(3));
ArrayList<Integer> list2 = new ArrayList<Integer>(list1.subList(1,4));
print(list1, list2);
Collections.sort(list1);
Collections.sort(list2);
print(list1, list2);
System.out.println("list1.containsAll(list2):"+list1.containsAll(list2));
list2.add(Integer.valueOf(11));
list2.add(Integer.valueOf(12));
list2.add(Integer.valueOf(13));
print(list1, list2);
list2.set(3, Integer.valueOf(21));
print(list1, list2);
System.out.println("list1.retainAll(list2):"+list1.retainAll(list2));
print(list1, list2);
for(int i=list2.size()-1; i>=0; i--) {
if(list1.contains(list2.get(i)))
list2.remove(i);
}
print(list1, list2);
}
static void print(ArrayList<Integer> list1, ArrayList<Integer> list2) {
System.out.println("list1:"+list1);
System.out.println("list2:"+list2);
System.out.println();
}
}
첫 번째 예제는 List의 삽입과 삭제에 관련된 예제입니다. 소스를 보시면 정수형 ArrayList 객체 list1을 선언한 다음, 순서대로 5 4 2 0 1 3을 삽입합니다. List는 순서가 있기 때문에 list1을 출력한다면 삽입한 순서대로 출력됩니다. list2는 list1의 1번째 원소부터 4번째 원소까지 복사하여 만든 List인데, 출력해보면 4 2 0 1이 아니라 4 2 0까지만 출력됩니다. 그 이유는 SubList 메소드 자체가 마지막 Index를 제외하기 때문입니다.
다음으로 Collection.sort() 메소드는 이름에서 유추할 수 있다시피 내부의 원소를 정렬하는 기능을 가지고 있습니다. Collection.sort() 메소드를 실행 후 list1과 list2를 출력해보면 앞서 출력된 원소가 정렬되어 출력됨을 확인할 수 있습니다.
list1.ContainsAll(list2) 메소드는 list1가 list2의 원소들을 모두 포함하고 있는지 체크하는 메소드입니다. 위에서 list1의 일부를 복사하여 list2를 만들었기 때문에 체크 후 결과는 true로 출력됩니다.
그 다음줄에서는 list2에 순서대로 11, 12, 13을 삽입합니다. 역시 예상대로 0 2 4 뒤에 11 12 13이 이어서 출력되는 것을 확인할 수 있습니다.
21은 이전과 다르게 set을 사용하여 삽입하는데, 앞에 3이라는 매개변수가 추가되었습니다. 이는 Index 3의 위치에 21을 삽입하겠다는 의미입니다. 배열의 Index는 0부터 시작하기 때문에 3번째가 아니라 4번째 위치에 21이 삽입됨을 유의하시가 바랍니다.
retainAll 메소드는 교집합을 구한다는 뜻입니다. list1.retainAll(list2)는 list1과 list2가 모두 갖고 있는 원소들을 출력하는 것이니, 그 결과는 0 2 4가 됩니다. 비슷한 기능으로 addAll(합집합), removeAll(차집합)이 있습니다.
마지막으로 나오는 반복문은 list2의 마지막 원소부터 하나씩 체크하며 list2의 i번째 Index의 원소를 list1이 갖고 있다면 list2에서 그 원소를 삭제하는 소스입니다. 소스 자체는 간단하지만 동작 방식은 상당히 심오한데요, 만약 저 소스를 아래처럼 바꾼다고 가정해봅시다.
for(int i=0; i<=list2.size()-1; i++) {
if(list1.contains(list2.get(i)))
list2.remove(i);
}
사실 소스만 보면 뒤에서부터 체크하는지, 앞에서부터 체크하는지만 달라진 모습입니다. 그러나 그 결과는 동일하게 나오지 않고 list2의 2가 사라지지 않는 결과가 나오게 됩니다.
그 이유는 list2에서 원소를 삭제하는 순간 list2의 index가 바뀌기 때문입니다. 하나씩 따져보면, list2의 원소는 순서대로 0 2 4 21 12 13이 됩니다. 그런데 앞에서부터 삭제하는 경우, 0이 list1에 있으니 list2의 0이 삭제되고, 그렇게 되면 list2[1]에 있던 2는 list[0]의 위치로 이동하게 됩니다. 반복문에 의해서 i=0에서 i=1로 넘어가게 되면, list[1]에는 2가 아니라 4가 있게 되므로 2가 삭제되지 않고 남는 결과가 생기게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import java.util.List;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
final int LIMIT = 10;
String source = "0123456789abcdefghijABCDEFGHIJ!@#$%^&*()ZZZ";
int length = source.length();
List<String> list = new ArrayList<String>(length/LIMIT + 10);
for(int i=0; i<length; i+=LIMIT) {
if(i+LIMIT < length) list.add(source.substring(i, i+LIMIT));
else list.add(source.substring(i));
}
for(int i=0; i<list.size(); i++) {
System.out.println(list.get(i));
}
}
}
두 번째 예제는 간단하게 List의 크기를 초과하도록 String을 추가하는 예제입니다. List는 배열과는 달리 크기를 초과하더라도 자동으로 부족한 크기만큼 크기가 늘어나는 특징을 가지고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import java.util.*;
public class Main {
public static void main(String[] args) {
Vector<String> v = new Vector<>(5);
v.add("1");
v.add("2");
v.add("3");
print(v);
v.trimToSize();
System.out.println("=== After trimToSize() ===");
print(v);
v.ensureCapacity(6);
System.out.println("=== After ensureCapacity(6) ===");
print(v);
v.setSize(7);
System.out.println("=== After setSize(7) ===");
print(v);
v.clear();
System.out.println("=== After clear() === ");
print(v);
}
public static void print(Vector<?> v) {
System.out.println(v);
System.out.println("size: " + v.size());
System.out.println("capacity: " + v.capacity());
}
}
세 번째 예제는 Vector 클래스를 보여주는 예제입니다. Vector는 ArrayList와 유사하지만, 동기화가 된다는 차이점이 있습니다. 이것은 한번에 단 하나의 쓰레드만 Vector에 접근할 수 있다는 의미입니다.
Vector에서는 크기를 나타내는 메소드가 Size와 Capacity가 있는데, 이것이 처음 배울 때는 혼동되기 쉽기 때문에 위에서부터 하나하나 따져보도록 하겠습니다. Line 5에서 Vector의 Capacity는 5로 정의됩니다. 이후 순서대로 1, 2, 3을 삽입합니다. 원소의 개수가 3개이므로 이 Vector의 Size는 3이 됩니다.
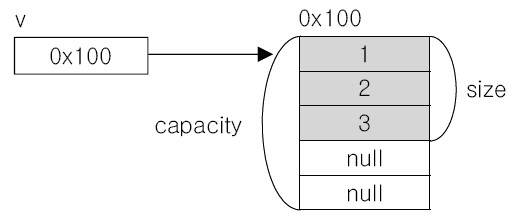
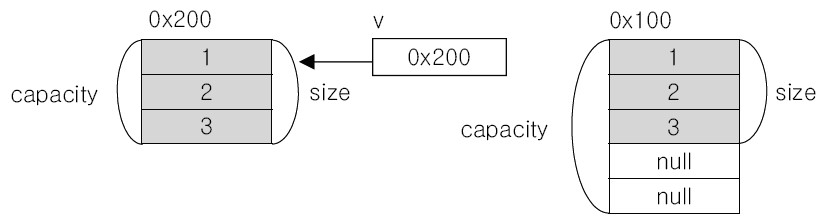
trimToSize() 메소드는 Capacity와 Size를 같게 만드는 명령어입니다. 정확하게 표현하면, 아래 그림처럼 Capacity와 Size가 동일한 새로운 인스턴스를 만들어서 원소의 내용을 복사합니다.
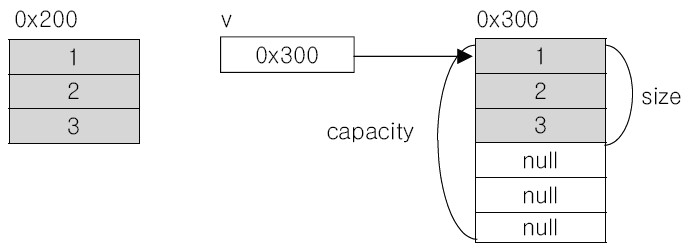
다음으로는 ensureCapacity(6) 메소드를 사용하는데, 이것은 해당 Vector의 Capacity가 6 이상이면 아무 일이 일어나지 않지만 그렇지 않으면 크기가 6인 새로운 인스턴스를 만들어서 기존 Vector의 원소를 복사합니다.
다음으로 나오는 setSize(7) 메소드는 ensureCapacity() 메소드처럼 Capacity가 7 이상이라면 아무 일이 일어나지 않습니다. 하지만 그렇지 않을 때 동작하는 방식은 조금 다른데요, Vector는 Capacity가 부족할 경우 자동적으로 기존의 Capacity를 2배 늘린 새로운 인스턴스를 생성합니다. 즉, 현재 Capacity가 6인 상태에서 setSize(7) 메소드를 호출한다면 Capacity가 6의 2배인 12가 되는 것입니다.
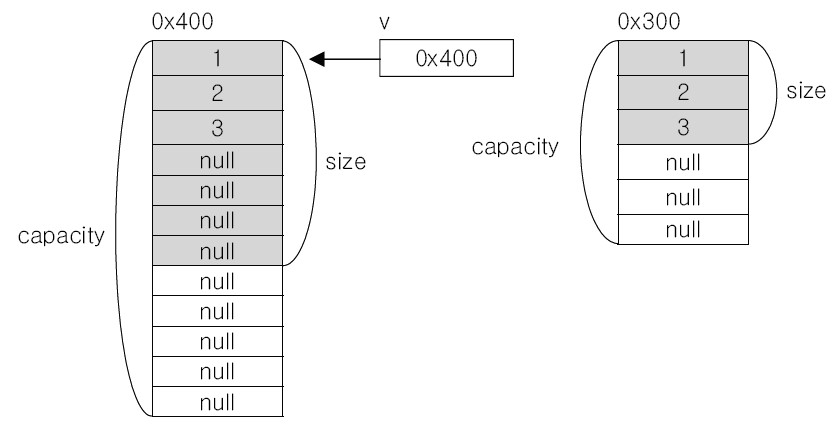
마지막으로 clear() 메소드를 사용하면 Size는 0이 되고 Capacity는 그대로 유지됩니다.
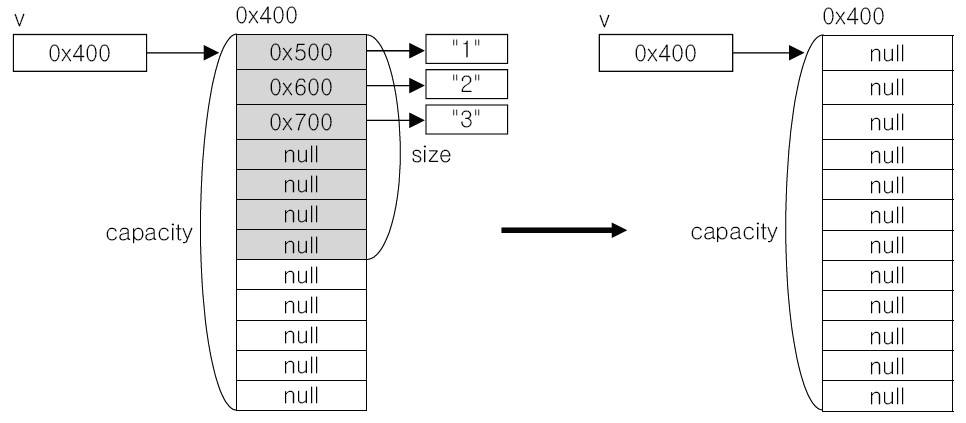
위의 예제에서는 매번 명령어를 수행 후 Size와 Capacity를 출력하여 어떻게 변화하는지를 보여주고 있습니다. 프로그램을 실행해보기 전에 먼저 머릿속으로 위와 같이 Size와 Capacity를 직접 계산해보시기 바랍니다.
이렇게 여러 예제를 통해 ArrayList 클래스를 알아보았습니다. ArrayList의 장점은 구조가 간단하고, Array(배열)처럼 Random Access가 가능하기 때문에 접근 속도가 빠르다는 것입니다. 단점 또한 명확합니다. 마지막 예제처럼 Capacity와 Size를 조절하는 메소드를 자주 사용하게 된다면 그 때마다 새로운 인스턴스를 생성하기 때문에 메모리 낭비가 심하다는 문제가 있습니다. 또한 List 중간에 데이터를 삽입/삭제할 때 시간이 오래 걸린다는 단점이 있습니다. 삽입/삭제하는 Index의 뒷부분의 데이터를 하나씩 당기거나 밀어야 하기 때문입니다.
LinkedList
LinkedList는 다른 컴퓨터공학 수업에서도 단골로 나오는 중요한 자료구조입니다. 데이터는 Head부터 순차적으로 접근할 수 있으며, 각 데이터가 아래처럼 연결되어 있기 때문에 LinkedList라 불립니다.

데이터는 노드(Node)라는 덩어리에 저장되어 있으며, 각 노드는 다음 노드를 가리키는 방식으로 구성되어 있습니다. 가장 기본적인 LinkedList의 노드는 아래와 같이 구성할 수 있습니다.
class Node {
Node next; // a link to the next element
Object obj; // data
}
LinkedList에서 새로운 노드를 추가하는 과정은 아래 그림과 같이 1개의 인스턴스 생성과 2개의 참조 업데이트 과정을 거치게 됩니다.
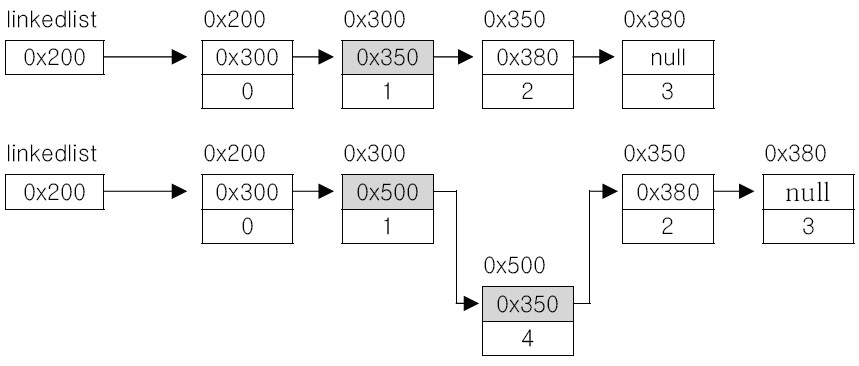
그에 반해 LinkedList에서 노드를 삭제하는 과정은 단순히 1개의 참조 업데이트만 필요합니다.
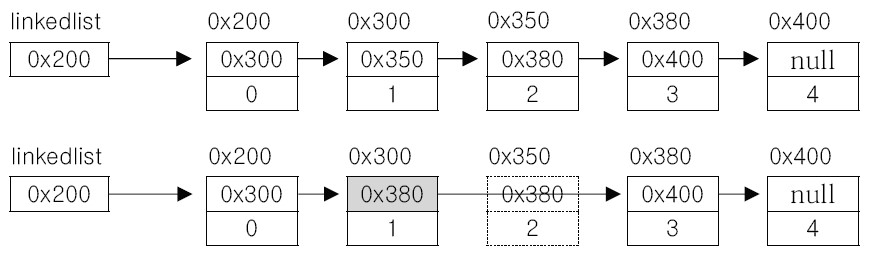
LinkedList는 처음 소개한 기본적인 구성 외에도 다양한 바리에이션이 존재합니다. Doubly Linked List는 다음 노드 뿐만 아니라 이전 노드도 가리키게 만드는 구조입니다. Doubly Linked List의 구조는 다음과 같습니다.

Doubly Linked List의 구조를 보완하여, 마지막 노드가 다음 노드로 처음 노드를 가리키게 하고 처음 노드의 이전 노드로 마지막 노드를 가리키게 만든 구조가 Doubly Circular Linked List입니다.

이렇게 Doubly한 구조는 이전 노드와 다음 노드를 모두 가리켜야하기 때문에 아래와 같이 클래스를 구성하게 됩니다.
class Node {
Node next;
Node prev;
Object obj;
}
이번에는 이전에 다룬 ArrayList와 LinkedList와의 성능 차이를 비교하는 예제를 두 개 보여드리도록 하겠습니다. 먼저, 순차적으로 데이터를 삽입/삭제하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import java.util.List;
import java.util.ArrayList;
import java.util.LinkedList;
public class Main {
public static long add1(List<String> list) {
long start = System.currentTimeMillis();
for(int i=0; i<1000000; i++) list.add(i+"");
long end = System.currentTimeMillis();
return end - start;
}
public static long add2(List<String> list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) list.add(500, "X");
long end = System.currentTimeMillis();
return end - start;
}
public static long remove1(List<String> list) {
long start = System.currentTimeMillis();
for(int i=list.size()-1; i>=0; i--) list.remove(i);
long end = System.currentTimeMillis();
return end - start;
}
public static long remove2(List<String> list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) list.remove(i);
long end = System.currentTimeMillis();
return end - start;
}
public static void main(String args[]) {
ArrayList<String> al = new ArrayList<>(2000000);
LinkedList<String> ll = new LinkedList<>();
System.out.println("=== sequential add ===");
System.out.println("ArraList : " + add1(al));
System.out.println("LinkedList: " + add1(ll));
System.out.println();
System.out.println("=== non-sequential add ===");
System.out.println("ArraList : " + add2(al));
System.out.println("LinkedList: " + add2(ll));
System.out.println();
System.out.println("=== non-sequential delete ===");
System.out.println("ArraList : " + remove2(al));
System.out.println("LinkedList: " + remove2(ll));
System.out.println();
System.out.println("=== sequential delete ===");
System.out.println("ArraList : " + remove1(al));
System.out.println("LinkedList: " + remove1(ll));
}
}
위의 예제에서는 순서대로 순차적 삽입, 비순차적 삽입, 비순차적 삭제, 순차적 삭제를 비교하여 보여주고 있습니다. 먼저 순차적 삽입과 삭제의 경우 ArrayList가 LinkedList보다 조금 더 빠르지만 큰 차이가 나지는 않습니다. 하지만 비순차적 삽입과 삭제의 경우에는 LinkedList가 ArrayList보다 월등히 빠른 속도를 보이게 됩니다. ArrayList에서는 데이터를 중간에 삽입하거나 삭제할 경우 그 뒤의 데이터를 전부 한칸식 옮기는 연산이 들어가기 때문입니다.
다음으로는 ArrayList와 LinkedList의 데이터 접근 성능을 비교하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import java.util.List;
import java.util.ArrayList;
import java.util.LinkedList;
public class Main {
public static void main(String args[]) {
ArrayList<String> al = new ArrayList<>(1000000);
LinkedList<String> ll = new LinkedList<>();
add(al);
add(ll);
System.out.println("=== access time ===");
System.out.println("ArrayList : " + access(al));
System.out.println("LinkedList: " + access(ll));
}
public static void add(List<String> list) {
for(int i=0; i<100000; i++) list.add(i+"");
}
public static long access(List<String> list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) list.get(i);
long end = System.currentTimeMillis();
return end - start;
}
}
ArrayList는 Random Access가 가능하기 때문에 어느 위치에 접근하더라도 시간이 소요되지 않습니다. 하지만 LinkedList는 항상 순차적으로만 데이터에 접근할 수 있기 때문에, 시작 노드에서 멀리 떨어진 노드일수록 접근 시간이 오래 소요됨을 알 수 있습니다.
두 예제를 통해 데이터의 삽입이나 삭제는 LinkedList가 우위에 있다고 볼 수 있으나, 접근 속도는 ArrayList가 우위에 있다고 볼 수 있습니다.
Stack and Queue
LinkedList 외에 또 중요하게 다루는 자료구조가 스택(Stack)과 큐(Queue)입니다. 이것들은 자료구조 시간에 자세하게 다루는 내용이기 때문에 여기서는 간단하게만 다루도록 하겠습니다. 스택은 먼저 삽입된 데이터일수록 나중에 나오는 구조(LIFO)이고, 큐는 먼저 들어간 데이터일수록 먼저 나오는 구조(FIFO)입니다.
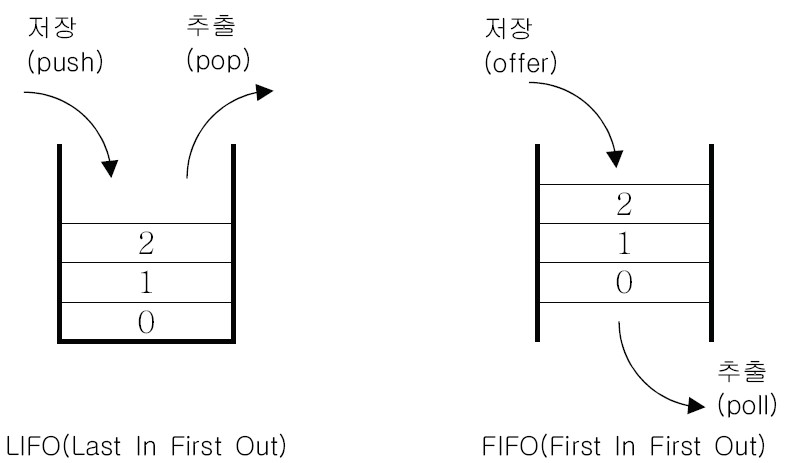
Java에서는 스택이 클래스로 구현되어 있으며, 큐는 인터페이스로 구현되어 있습니다. 이전에 다룬 LinkedList가 Queue 인터페이스로 구현된 클래스 중 하나입니다. 먼저 Stack 클래스와 Queue 인터페이스의 메소드를 간단하게 알아보도록 하겠습니다.
Stack
- boolean empty() : 스택이 비어있는지 확인한다. 비어있다면 true를 반환한다.
- E peek() : 스택에서 맨 위에 있는 원소를 반환하되, 제거하지 않는다.
- E pop() : 스택에서 맨 위에 있는 원소를 반환하며, 스택에서 제거한다.
- E push(E item) : 스택 맨 위에 item을 삽입한다.
- int search(Object o) : 해당 오브젝트가 위치한 곳을 반환한다. (1부터 시작)
Queue
- boolean add(E e) : 큐에 공간이 남았다면 e를 삽입하고, 그렇지 않다면 illegalStateException을 발생시킨다.
- E element() : 큐의 맨 앞의 원소를 반환하되, 제거하지 않는다.
- boolean offer(E e) : 큐에 공간이 남았다면 e를 삽입한다.
- E peek() : 큐의 맨 앞의 원소를 반환하되, 제거하지 않는다. 만약 큐가 비어있다면 null을 반환한다.
- E poll() : 큐의 맨 앞의 원소를 반환하며, 큐에서 제거한다. 만약 큐가 비어있으면 null을 반환한다.
- E remove() : 큐의 맨 앞의 원소를 반환하며, 큐에서 제거한다.
아래의 예제는 스택과 큐가 실제로 어떻게 데이터를 삽입/삭제하는지 보여주는 간단한 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import java.util.Stack;
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
Stack<String> st = new Stack<String>();
Queue<String> q = new LinkedList<String>();
st.push("0");
st.push("1");
st.push("2");
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("=== Stack ===");
while(!st.empty()) System.out.println(st.pop());
System.out.println("=== Queue ===");
while(!q.isEmpty()) System.out.println(q.poll());
}
}
예상했던 대로 Stack은 삽입한 순서의 반대 순서로 제거되고, Queue는 삽입한 순서대로 데이터가 제거되는 것을 알 수 있습니다. 만약 시간적 여유가 있으시다면 직접 Stack과 Queue 클래스를 구현해보는 것도 공부하는데 많은 도움이 되실 것 같습니다.
Priority Queue
우선순위 큐(Priority Queue)는 큐의 한 종류로써, 입력된 순서가 아닌 우선순위에 따라 데이터를 제거하는 자료구조입니다. 즉, 가장 높은 우선순위를 가진 데이터가 가장 먼저 제거됩니다. 우선순위 큐의 데이터들은 힙(Heap)으로 구성되며 이 힙은 배열(Array)로 구현됩니다. 우선순위 큐 또한 자료구조 시간에 자세히 다루는 내용이기 때문에 여기서는 간단한 예제만 남기도록 하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import java.util.Queue;
import java.util.PriorityQueue;
public class Main {
public static void main(String[] args) {
Queue<Integer> pq = new PriorityQueue<Integer>();
pq.offer(3);
pq.offer(1);
pq.offer(5);
pq.offer(2);
pq.offer(4);
System.out.println(pq);
Integer i = null;
while((i = pq.poll()) != null) System.out.println(i);
}
}
이번 포스트는 여기까지입니다. 다음에는 이번 포스트에 이어서 Collection Framework에 대해 더 자세히 알아보도록 하겠습니다. 읽어주셔서 감사합니다!
Leave a comment