
Collection Framework (3)
안녕하세요, 오늘은 Collection Framework 3번째 포스트입니다. 이번에 다룰 Collection Framwork는 HashSet과 TreeSet입니다.
HashSet
HashSet은 Set Interface를 구현한 클래스입니다. HashSet은 원소의 중복을 허용하지 않고(= e1.equals(e2)를 만족하는 e1, e2가 없음), 최대 1개의 null 원소가 존재할 수 있으며, 원소의 순서가 중요하지 않다는 특징을 가지고 있습니다.
HashSet을 생성하는 방법은 다음 4가지가 있습니다.
- HashSet() : 비어있는 새 HashSet을 생성한다. 기본적으로 16의 Capacity와 0.75의 Load Factor를 갖습니다.
- HashSet(int initialCapacity) : 비어있는 새 HashSet을 생성한다. 매개변수로 넣은 initialCapacity만큼의 Capacity와 0.75의 Load Factor를 갖습니다.
- HashSet(int initialCapacity, float loadFactor) : 비어있는 새 HashSet을 생성한다. 매개변수로 넣은 initialCapacity만큼의 Capacity와 loadFactor 만큼의 Load Factor를 갖습니다.
- HashSet(Collection<? extends E> c) : 매개변수로 넣은 Collection을 포함한 새로운 Set을 생성한다.
HashSet에는 특이하게 Load Factor라는 것이 있는데, 이것은 언제 Capacity를 2배로 늘릴지 정하는 기능입니다. 예를 들어, Load Factor가 0.75라면 Capacity의 75%가 채워지면 자동으로 Capacity를 2배로 늘린다는 뜻입니다.
다음으로 HashSet의 메소드를 정리해보도록 하겠습니다.
- boolean add(E e) : 원소 e가 set에 존재하지 않는 경우 추가한다.
- void clear() : set에 들어있는 모든 원소를 제거한다.
- Object clone() : HashSet 인스턴스를 복제한다. 단, 원소들은 복제되지 않는다.
- boolean contains(Object o) : set에 o가 포함되어 있으면 true를, 그렇지 않으면 false를 반환한다.
- boolean isEmpty() : set에 원소가 없으면 true를, 그렇지 않으면 false를 반환한다.
- iterator
iterator() : 이 set의 원소에 대한 iterator를 반환한다. - boolean remove(Object o) : 이 set에서 특정 원소인 o를 제거한다.
- int size() : 이 set의 원소의 수(Cardinality)를 반환한다.
이 외에도 AbstractCollection 클래스에서 선언된 addAll(), containsAll(), retainAll(), toArray(), toArray(T[] a), toString() 메소드도 사용 가능하고, AbstractSet 클래스에서 선언된 equals(), hashCode(), removeAll() 메소드 또한 사용이 가능합니다.
이해를 돕기 위해 몇 가지 예제를 통해 HashSet에 대해 자세히 알아보도록 하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import java.util.*;
class Main {
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
for( ; set.size() < 6; ) {
int num = (int)(Math.random()*45) + 1;
set.add(Integer.valueOf(num));
}
List<Integer> list = new LinkedList<>(set);
Collections.sort(list);
System.out.println(list);
}
}
첫 번째 예제는 로또 번호 6개를 무작위로 뽑는 프로그램입니다. HashSet은 중복을 허용하지 않기 때문에, 무작위로 뽑은 번호가 이미 뽑힌 번호라도 HashSet에 추가되지 않습니다. 리스트라면 숫자를 뽑을 때마다 중복인지 아닌지 확인해야 하지만, HashSet은 그럴 필요가 없다는 장점이 있습니다.
이 예제에서는 로또 번호를 출력하기 전에 Set을 List로 변환하는 부분이 있습니다. 그 이유는 Set은 순서가 없기 때문에 오름차순으로 정렬하기 위해서는 List를 사용해야하기 때문입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import java.util.*;
class Person {
String name;
int age;
Person(String name, int age) { this.name = name; this.age = age; }
public String toString() { return name + ":" + age; }
}
public class Main {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person("David", 10));
set.add(new Person("David", 10));
System.out.println(set);
}
}
두 번째 예제는 인적사항을 저장하는 Person 클래스를 활용하여 HashSet에 저장하는 프로그램입니다. main 메소드를 보시면 나이가 10살인 David라는 사람을 Set에 두 번 넣은 것이 보입니다. Set은 중복을 허용하지 않기 때문에 동일한 사람을 2번 삽입해도 1개만 저장되어야 하지만, 프로그램을 실행해보시면 이상하게도 2개 모두 저장이 되어버리는 문제가 발생합니다.
이런 문제가 발생하는 이유는 두 개의 Object를 중복으로 판단하는 기준이 equals() 메소드와 hashCode() 메소드이기 때문입니다. 따라서 이 부분은 동일한 사람이 입력되면 수동으로 equals()가 true를 반환하도록, hashCode() 메소드가 같은 값을 반환하도록 설정해주어야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import java.util.*;
class Person {
String name;
int age;
Person(String name, int age) { this.name = name; this.age = age; }
public boolean equals(Object obj) {
if(obj instanceof Person) {
Person tmp = (Person)obj;
return name.equals(tmp.name) && age==tmp.age;
}
return false;
}
public int hashCode() { return (name+age).hashCode(); }
public String toString() { return name + ":" + age; }
}
public class Main {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person("David", 10));
set.add(new Person("David", 10));
System.out.println(set);
}
}
두 번째 예제가 목적에 맞게 실행되기 위해서는 Person 클래스를 이렇게 수정해주시면 됩니다.
여기에서는 기존에 존재하는 hashCode() 메소드를 재정의(Override)함으로써 문제를 해결하였습니다. 하지만 hashCode() 메소드는 마음대로 수정하면 안되고, 수정할 때는 반드시 아래 규칙을 따라야만 합니다.
같은 프로그램에서 hashCode() 메소드는 동일한 Object에 대해 동일한 값을 반환해야 합니다. (다른 프로그램에서는 달라도 상관이 없습니다)
equals()가 두 객체에 대해 true를 반환하면hashCode()또한 동일해야 합니다.equals()가 두 객체에 대해 false를 반환할 때hashCode()가 반드시 다를 필요는 없으나, 다를 것을 권장합니다. 왜냐하면 서로 다른 두 객체가HashCode()반환값이 같을 경우 HashSet이나 HashMap에서 원소를 검색할 때 성능이 저하되기 때문입니다.
TreeSet
TreeSet은 이진 검색 트리(Binary Search Tree)를 사용하여 데이터를 저장합니다. 이진 검색 트리는 트리 자료구조의 한 종류로써, 각 노드는 최대 2개의 자식 노드(Child node)를 가질 수 있습니다. 이 때 왼쪽에 있는 자식 노드는 부모 노드(Parent node)보다 작은 값, 오른쪽에 있는 자식 노드는 부모 노드보다 큰 값을 갖습니다.
TreeSet도 Set Interface로부터 구현된 클래스이기 때문에, 마찬가지로 중복을 허용하지 않습니다. 하지만 데이터의 저장 방식(BST)으로 인해 입력과 함께 정렬되므로 일반적인 Set Interface 파생 클래스에 비해 차이가 있습니다. TreeSet은 정렬 및 검색에서 좋은 성능을 보인다는 장점이 있습니다.
먼저, TreeSet을 생성하는 메소드부터 알아보도록 하겠습니다.
- TreeSet() : 비어있는 새 TreeSet을 생성한다. (기본 Ordering으로 정렬)
- TreeSet(Collection<? extends E> c) : Collection c를 포함한 새 TreeSet을 생성한다. (기본 Ordering으로 정렬)
- TreeSet(Comparator<? super E> comparator) : 비어있는 새 TreeSet을 생성한다. (매개변수로 들어온 Ordering으로 정렬)
- TreeSet(SortedSet
s) : 정렬되어있는 Set s를 포함한 TreeSet을 생성한다. (Ordering은 s를 따른다)
다음으로 TreeSet에서 사용하는 메소드입니다. HashSet에 비해 그 종류가 상당히 많습니다.
- boolean add(E e) : 원소 e가 set에 존재하지 않는 경우 추가한다.
- boolean addAll(Collection<? extends E> c) : Collection c를 전부 set의 원소로 추가한다.
- E ceiling(E e) : 매개변수 e보다 크거나 같은 set의 원소 중에 가장 작은 값을 반환한다. 만약 그런 원소가 없다면 null을 반환한다.
- void clear() : set의 모든 원소를 제거한다.
- Object clone() : TreeSet 인스턴스를 복제한다.
- boolean contains(Object o) : set에 원소 o가 포함되어 있으면 true를 반환하고 그렇지 않으면 false를 반환한다.
- Iterator
descendingIterator() : 이 set에 대한 iterator를 내림차순으로 반환한다. - NavigableSet
descendingSet() : 이 set의 원소들을 역순으로 반환한다. - E first() : 이 set의 원소 중 첫 번째(가장 작은) 원소를 반환한다.
- E floor(E e) : 매개변수 e보다 작거나 같은 set의 원소 중에 가장 큰 값을 반환한다. 만약 그런 원소가 없다면 null을 반환한다.
- SortedSet
headSet(E toElement) : toElement보다 작은 원소들을 반환한다. - NavigableSet
headSet(E toElement, boolean inclusive) : 원소가 toElement보다 작은(inclusive가 true인 경우 동일한 것도 포함) 이 set의 일부를 반환합니다. - E higher(E e) : 매개변수 e보다 크거나 같은 set의 원소 중에 가장 작은 값을 반환한다. 만약 그런 원소가 없다면 null을 반환한다.
- boolean isEmpty() : set에 원소가 없으면 true를, 그렇지 않으면 false를 반환한다.
- Iterator
iterator() : 이 set에 대한 iterator를 오름차순으로 반환한다. - E last() : 이 set의 원소 중 마지막 (가장 큰) 원소를 반환한다.
- E lower(E e) : 매개변수 e보다 작은 set의 원소 중에 가장 큰 값을 반환한다. 만약 그런 원소가 없다면 null을 반환한다.
- E pollFirst() : set의 첫 번째 원소를 제거하고 반환한다. 만약 set이 비어있다면 null을 반환한다.
- E pollLast() : set의 마지막 원소를 제거하고 반환한다. 만약 set이 비어있다면 null을 반환한다.
- boolean remove(Object o) : set에서 원소 o가 존재한다면 제거한다.
- int size() : 이 set의 원소의 수(Cardinality)를 반환한다.
- Spliterator
spliterator() : 이 집합의 원소에 대해 late-binding과 fail-fast spliterator를 생성한다. - NavigableSet
subset(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) : fromElement부터 toElement까지의 set 원소를 반환한다. (inclusive가 true라면 경계값을 포함한다) - SortedSet
subset(E fromElement, E toElement) : fromElement (경계값 포함)부터 toElement(경계값 제외)까지의 set 원소를 반환한다. - SortedSet
tailSet(E fromElement) : set의 원소 중 fromElement보다 크거나 같은 원소들을 반환한다. - NavigableSet
tailSet(E fromElement, boolean inclusive) : 원소가 fromElement보다 큰(inclusive가 true인 경우 동일한 것도 포함) 이 set의 일부를 반환합니다.
TreeSet으로도 예제를 몇 가지 다뤄보도록 하겠습니다. 먼저 HashSet의 첫 번째 예제였던 로또 추첨 프로그램을 TreeSet으로 구현한 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<>();
for( ; set.size() < 6; ) {
int num = (int)(Math.random() * 45) + 1;
set.add(Integer.valueOf(num));
}
System.out.println(set);
}
}
프로그램의 실행 결과는 HashSet에서의 예제와 동일합니다. HashSet의 경우에는 숫자를 정렬하기 위해 HashSet의 데이터를 List에 삽입하여 정렬하였는데, TreeSet은 기본적으로 정렬되어 있기 때문에 정렬이 필요 없어 더 깔끔한 코드가 나옵니다.
1
2
3
4
5
6
7
8
9
10
11
12
import java.util.*;
public class Main {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<Integer>();
int[] score = {80, 95, 50, 35, 45, 65, 10, 100};
for(int i=0; i<score.length; i++)
set.add(Integer.valueOf(score[i]));
System.out.println("less than 50: " + set.headSet(Integer.valueOf(50)));
System.out.println("greater than or equal to 50: " + set.tailSet(Integer.valueOf(50)));
}
}
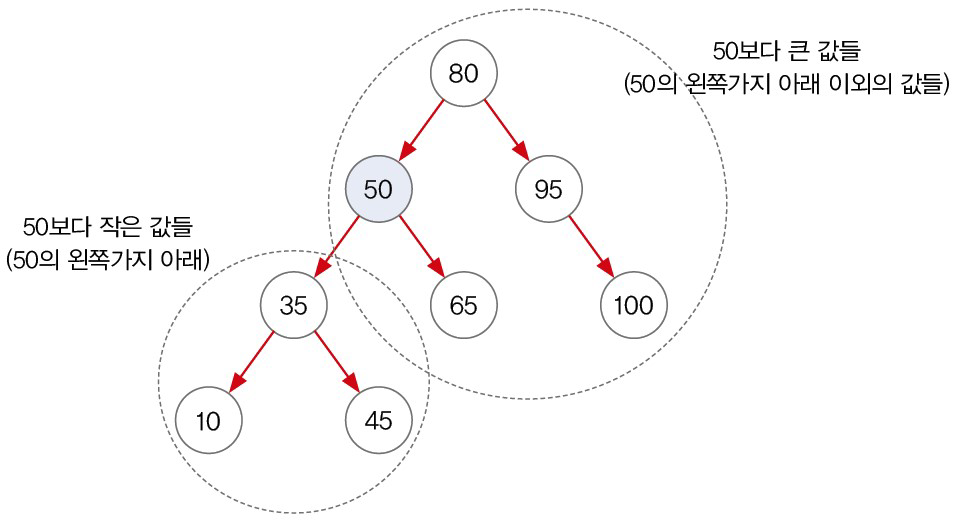
두 번째 예제는 TreeSet을 사용하여 크기를 분류하는 예제입니다. 프로그램에서는 50을 기점으로 50 이상인 숫자와 50 미만인 숫자를 분류하고 있습니다. List라면 원소 하나하나마다 크기를 비교하여 분류하겠지만, TreeSet은 이진 검색 트리(BST)를 사용하고 있기 때문에 그럴 필요가 없습니다. 50을 저장하고 있는 노드를 찾으면 50 왼쪽에 있는 값들은 50보다 작은 값들이고, 그 외의 값들은 50보다 큰 값들이기 때문입니다. 아래 그림을 보시면 무슨 말인지 이해가 빠를 겁니다.
이번 포스트는 여기까지입니다. 다음 포스트는 Collection Framework 마지막 포스트로써 HashMap과 TreeMap에 대해 소개하도록 하겠습니다. 읽어주셔서 감사합니다!
Leave a comment