
Multithreaded Programming with Java (1)
안녕하세요, 지난 Networking with Java에 이은 마지막 주제는 Multithreaded Programming with Java입니다. 원래 순서는 Network 1 - Multithread 1 - Network 2 - Multithread 2 이지만 같은 주제는 묶어서 진행하는 것이 좋을 것 같아 임의로 순서를 변경하였습니다. 그로 인해 지난 Network 2번째 포스트에서 뜬금없이 쓰레드가 언급되었는데, 이번 포스트로 쓰레드에 대한 설명을 보충하도록 하겠습니다.
Background
저희는 지금 Java를 사용해서 프로그램(Program)을 만들고 있습니다. 프로그램을 실행시키기 위해서는 OS에서 프로그램을 실행하기 위한 프로세스(Process)를 만들어줘야 합니다. 각 프로세스에는 필요한 만큼의 메모리가 할당됩니다. 윈도우 10에서는 작업 관리자의 프로세스 탭을 통해 실행 중인 프로세스를 확인할 수 있습니다.

쓰레드(Thread)란 프로그램된 명령어의 가장 작은 시퀀스(Sequence)로 스케줄러(Scheduler)에 의해 독립적으로 관리됩니다. 하나의 프로세스는 1개 이상의 쓰레드를 갖고 있습니다. 즉, 이 말은 프로세스가 1개의 쓰레드만 갖고 있을 수도 있고 필요에 따라서 여러 개의 쓰레드를 가질 수도 있다는 뜻입니다. 후자처럼 프로세스가 2개 이상의 쓰레드를 갖고 있을 경우 멀티쓰레드 프로세스(Multi-threaded Process)라고 부릅니다.
멀티쓰레딩(Multithreading)과 이름도 비슷하고 의미도 비슷하다보니 멀티태스킹(Multitasking)과 혼동하시는 분들도 있습니다. 멀티태스킹은 OS가 여러 개의 프로세스(즉, Task)를 동시에 실행하는 것을 말하고, 멀티쓰레드는 프로세스가 여러개의 쓰레드를 동시에 실행하는 것을 말합니다. 이 차이점을 꼭 기억하시기 바랍니다.
프로세스와 쓰레드의 관계는 공장과 노동자의 관계로 생각하시면 쉽게 이해하실 수 있습니다. 프로세스는 공장이고, 쓰레드는 노동자입니다. 쓰레드가 많을수록(=노동자가 많을 수록) 프로세스의 일처리 능력(=공장의 생산력)이 올라가는 방식입니다.
멀티쓰레딩의 장점으로는 시스템 자원을 효율적으로 사용할 수 있다는 것입니다. 예를 들어, 한 쓰레드가 디스크에서 파일을 읽는 동시에 다른 쓰레드로 연산을 수행할 수 있습니다. 네트워크 프로그램 같은 경우에는 동시에 여러 사용자와 통신도 가능하다는 장점이 있습니다. 예를 들어 지난 포스트에서 배운 채팅 프로그램의 경우에는 서버 프로그램에서 클라이언트 하나당 한 개의 쓰레드를 할당하여 동시에 여러 클라이언트와 채팅이 가능하도록 구성하였습니다.
반대로 멀티쓰레딩을 사용함으로써 단점도 있습니다. 첫째로, 동기화(Synchronization) 문제입니다. 예를 들어 은행의 계좌를 관리하는 프로그램이 있다고 가정해봅시다. 현재 계좌에 100만원이 있는데, 한 쓰레드가 입금을 처리하고 다른 쓰레드가 출금을 처리합니다. 만약 10만원을 입금하는 것과 거의 동시에 10만원을 출금하려고 합니다. 두 쓰레드는 각자 100만원이라는 금액을 읽었습니다. 원래라면 100만원에서 10만원 입금 -> 10만원 출금으로 100만원이 남아있어야 하는데, 입금 쓰레드에서는 110만원을 저장하고, 출금 쓰레드는 90만원을 저장하여 최종적으로 90만원을 저장되는 문제가 발생할 수 있습니다.
두 번째로 교착 상태(Dead-lock) 문제입니다. 쓰레드 A가 자원 alpha를 보유하고 있고 쓰레드 B가 자원 beta를 보유하고 있습니다. 그런데 쓰레드 A는 beta가 필요하고 쓰레드 B는 alpha가 필요합니다. 이 경우 각자 필요한 자원을 요청하는데, 보유하고 있는 자원 또한 필요할 때 서로 요청만 할 뿐 자원을 교환하지 않습니다. 즉, 두 쓰레드는 서로 대기만 하는 교착 상태가 발생해버리고 맙니다.
마지막으로는 비효율성(Inefficientcy) 문제입니다. 쓰레드가 항상 바쁘다면 문제가 되지 않지만, 할 일이 없는 경우에도 다른 작업에 할당되지 못하고 쓰레드 자원을 낭비할 수 있는 문제가 있습니다. 이것은 그나마 위의 두 가지보다는 나은 경우입니다.
이렇게 멀티쓰레딩을 사용함으로써 원래라면 고려하지 않아도 될 문제를 고려해야하기 때문에 프로그래머의 피로도가 증가하는 문제가 있습니다.
Implementing threads in Java
Java에서 쓰레드를 생성하는 방법은 두 가지가 있습니다. 하나는 Thread 클래스를 상속받는 것이고, 다른 하나는 Runnable 인터페이스를 확장하는 것입니다. Runnable 인터페이스를 사용하는 경우 run() 메소드를 반드기 구현해야 하고, Thread 클래스를 상속받는 경우에는 run() 메소드를 그대로 사용할 수도 있지만 재정의(Override) 하는 것이 보통입니다. 두 방법의 일반적인 구조는 다음과 같습니다.
class MyThread extends Thread {
public void run() { // overriding
/* tasks to run on a thread */
}
}
class MyThread implements Runnable {
public void run() {
/* tasks to run on a thread */
}
}
그렇기 때문에 Thread를 상속받는 것과 Runnable 인터페이스를 확장하는 것은 큰 차이가 없습니다. 본인의 기호에 따라 사용하시면 되긴 하지만, Java에서는 한 개의 클래스만 상속이 가능하므로 Thread를 상속받게 되면 다른 클래스를 상속받지 못하는 문제가 있습니다. 그렇기 때문에 일반적으로는 Runnable 인터페이스를 확장하는 것을 선호합니다.
Thread를 상속받는 것과 Runnable 인터페이스를 확장하는 방법은 사용하는 방법이 조금 다릅니다. 간단한 예제로 각각의 경우 어떻게 쓰레드를 만들고 사용하는지 알아보도록 하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Main {
public static void main(String[] args) {
ThreadEx1_1 t1 = new ThreadEx1_1();
Runnable r = new ThreadEx1_2();
Thread t2 = new Thread(r);
t1.start();
t2.start();
}
}
class ThreadEx1_1 extends Thread {
public void run() {
for(int i=0; i<5; i++) System.out.println(getName());
}
}
class ThreadEx1_2 implements Runnable {
public void run() {
for(int i=0; i<5; i++) System.out.println(Thread.currentThread().getName());
}
}
ThreadEx1_1 클래스는 Thread 클래스를 상속받아 만든 클래스이고, ThreadEx1_2 클래스는 Runnable 인터페이스를 확장하여 만든 클래스입니다. 두 클래스 모두 run() 메소드는 반복문을 사용해서 쓰레드의 이름을 다섯 번씩 출력하도록 만들었습니다.
가장 먼저 보이는 두 방법의 차이점은 main() 메소드에서 객체를 생성하는 부분입니다. Thread를 상속받는 ThreadEx1_1 클래스는 바로 ThreadEx1_1형 인스턴스를 선언하는 한 줄로 끝이지만, ThreadEx1_2 객체는 먼저 Runnable 인스턴스로 생성 후 Thread 인스턴스의 매개변수로 삽입합니다.
두 번째로 보이는 부분은 두 클래스의 run() 메소드입니다. 분명히 같은 동작을 하는 부분인데, 코드가 다른 것이 보입니다. getName() 메소드는 Thread 클래스에 정의되어있는 메소드이기 때문에 Runnable을 확장한 ThreadEx1_2 클래스는 사용할 수 없기 때문입니다. 따라서 Thread.currentThread 메소드를 호출하여 간접적으로 쓰레드의 이름을 출력해야 합니다.
차이점은 아니지만 두 방법 모두 쓰레드를 실행하기 위해서는 start() 메소드를 호출해야 합니다. 만약 같은 쓰레드에서 start() 메소드를 두 번 호출하면 IllegalThreadStateException이 발생합니다. start() 메소드가 호출되면 쓰레드는 스케줄러로 이동하고 스케줄러는 CPU로 쓰레드를 보내 CPU에서 실행합니다.
Threads : Start and Run
방금 전 예제에서 하나의 의문이 있습니다. 대체 왜 구현한 run() 메소드를 직접 호출하지 않고 start() 메소드를 통해 실행하는 걸까요? 그 이유는 Java의 심오한 구조 때문입니다.
만약 main() 메소드에서 run() 메소드를 호출한다면 새로운 쓰레드를 만들지 않고 그냥 메소드로써 호출되기 때문입니다. 메소드를 호출하게 되면 stack에 쌓이고 가장 위에 있는 메소드 순서대로 실행이 되는데요, main() 메소드에서 run() 메소드를 호출했을 때의 스택 상황은 이렇습니다.

이렇게 실행되면 run() 메소드가 끝날 때까지 기다려야하기 때문에 우리가 원하는 쓰레드를 실행할 수 없습니다. 그렇기 때문에 Java에서는 start() 메소드를 호출하여 start() 메소드로 새로운 쓰레드를 만들고, 그 쓰레드에서 run()을 호출함으로써 쓰레드를 구현합니다. 이렇게 되면 할일이 끝난 start() 메소드는 스택에서 빠지게 되고 run() 메소드를 실행하는 동안 main() 메소드도 같이 실행할 수 있게 되는 것입니다.

그림상으로 표현하면 위와 같습니다만, main() 메소드와 run() 메소드가 완벽히 동시에 실행되기 위해서는 컴퓨터 CPU에 2개 이상의 코어가 필요합니다. 만약 싱글 코어 CPU라면 스케쥴러에서 언제 쓰레드를 실행할 것인지 결정합니다.
이 경우 main() 메소드를 실행하는 쓰레드와 run() 메소드를 실행하는 쓰레드가 다르기 때문에 상황에 따라서 main() 메소드가 먼저 끝나는 경우가 발생할 수 있습니다. 따라서 프로그램은 모든 쓰레드가 종료되기 전까지 끝나지 않습니다.
그렇다면 간단한 예제를 통해 start()와 run()이 어떻게 다른지 확인해보겠습니다. 먼저 예제부터 보여드리겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Main {
public static void main(String args[]) throws Exception {
ThreadExample t1 = new ThreadExample();
t1.start();
//t1.run()
}
}
class ThreadExample extends Thread {
public void run() {
throwException();
}
public void throwException() {
try {
throw new Exception();
} catch(Exception e) {
e.printStackTrace();
}
}
}
ThreadExample 클래스는 단순히 예외를 강제로 발생시키는 클래스입니다. 이 예제에서 main()에서 start()로 실행을 먼저 해보시고, start()를 주석처리하신 다음 run()을 실행해보시면 printStackTrace 메소드가 출력하는 오류문이 다를겁니다. 어떻게 오류문이 다른지 직접 확인해보시기 바랍니다.
Single thread vs Multiple threads
그렇다면 이번에는 하나의 쓰레드만 사용하는 것과 여러 쓰레드를 사용하는 것 중 어느 것이 뛰어난지 알아보도록 하겠습니다. 똑같은 프로그램을 하나의 쓰레드와 여러 쓰레드로 구현해보고 실행시간을 비교해봅시다. 먼저 하나의 쓰레드로 a와 b를 각각 300번씩 출력하는 프로그램입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class Main {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
for(int i=0; i<300; i++) {
System.out.printf("%s", new String("a"));
}
System.out.print("\nelapsed time: " + (System.currentTimeMillis() - startTime) + "\n");
for(int i=0; i<300; i++) {
System.out.printf("%s", new String("b"));
}
System.out.print("\nelapsed time: " + (System.currentTimeMillis() - startTime) + "\n");
}
}
다음은 a를 출력하는 것과 b를 출력하는 것을 각각 다른 쓰레드에 할당한 프로그램입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class Main {
static long startTime = 0;
public static void main(String[] args) {
AnotherThread th1 = new AnotherThread();
th1.start();
startTime = System.currentTimeMillis();
for(int i=0; i<300; i++) System.out.printf("%s", new String("a"));
System.out.print("\nelapsed time 1: " + (System.currentTimeMillis() - Main.startTime));
}
}
class AnotherThread extends Thread {
public void run() {
for(int i=0; i<300; i++) System.out.printf("%s", new String("b"));
System.out.print("\nelapsed time 2: " + (System.currentTimeMillis() - Main.startTime));
}
}
두 프로그램을 각각 실행해보시고 실행시간이 얼마나 차이나는지 비교해봅시다. 컴파일러에 따른 차이가 있기 때문에, 어떤 환경에서는 2개의 쓰레드의 효율이 좋지만 다른 환경에서는 그렇지 않은 경우도 있습니다. (만약 300개로 비교가 힘들다면 3000개나 30000개 출력으로 변경해서 테스트해봅시다) 왜 그런지 이유를 분석해봅시다.
먼저 단일 쓰레드 프로그램에서는 a를 출력하는 부분(A)와 b를 출력하는 부분(B)가 그림처럼 순서대로 실행됩니다.

A와 B를 각각 다른 쓰레드에서 실행할 경우 가능한 경우는 2가지가 있습니다. 만약 CPU가 1개의 코어만 갖고 있다면 쓰레드를 동시에 실행할 수 없기 때문에 스케쥴러가 두 작업을 적절히 조절하여 실행합니다. 만약 스케쥴러가 라운드-로빈(Round-Robin) 시스템을 사용한다면 A와 B를 다음과 같이 할당하여 실행합니다.
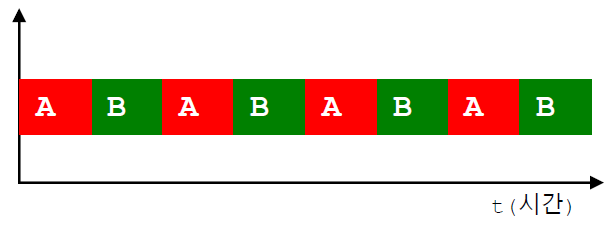
이 경우 사용자는 마치 A와 B 작업이 동시에 실행되는 것처럼 보이지만, 실제로는 짧은 시간동안 번갈아가며 실행되는 것이기 때문에 단일 쓰레드 작업에서의 실행 시간과 큰 차이가 없게됩니다. 오히려 쓰레드를 만드는데 생기는 추가 작업으로 인해 더 많은 시간이 걸릴 수도 있습니다. 따라서 단일 코어 시스템을 상정하고 만드는 프로그램은 쓰레드를 사용하지 않는 것이 좋습니다.
반대로 여러 개의 코어가 있는 CPU라면 두 개의 쓰레드가 각각 다른 코어에서 실행되므로 멀티쓰레드 프로그램의 목적대로 동시에 두 작업을 실행할 수 있습니다. 따라서 이 경우에는 단일 쓰레드 작업보다 확실히 소요시간이 줄어듭니다. (물론 정확하게 절반으로 줄어드는 것은 아닙니다)

이렇게 보면 멀티 쓰레드 프로그램은 그다지 큰 메리트가 없는 것처럼 보입니다. 하지만 이번에는 또 다른 예제를 통해 멀티 쓰레드 프로그램을 왜 사용하는지 알아보겠습니다. 이번에 보여드릴 예제는 사용자로부터 입력을 받고, 10초를 기다리는 간단한 프로그램입니다. 먼저 단일 쓰레드로 구현한 프로그램입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import javax.swing.JOptionPane;
public class Main {
public static void main(String[] args) throws Exception {
String input = JOptionPane.showInputDialog("Enter any string.");
System.out.println("You have entered: " + input);
for(int i=10; i>0; i--) {
System.out.println(i);
try {
Thread.sleep(1000);
} catch(Exception e) { /* do nothing */ }
}
}
}
이번에는 같은 프로그램을 2개의 쓰레드로 나눈 프로그램입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import javax.swing.JOptionPane;
public class Main {
public static void main(String[] args) throws Exception {
ThreadExample th1 = new ThreadExample();
th1.start();
String input = JOptionPane.showInputDialog("Enter any string.");
System.out.println("You have entered: " + input);
}
}
class ThreadExample extends Thread {
public void run() {
for(int i=10; i>0; i--) {
System.out.println(i);
try {
sleep(1000);
} catch(Exception e) { }
}
}
}
두 프로그램을 각각 실행해봅시다. 차이점이 느껴지시나요?
단일 쓰레드 프로그램은 입력이 끝난 후에 10초를 기다리는 부분이 시작되지만, 2개의 쓰레드를 사용할 때는 사용자의 입력을 기다리는 동안 10초를 기다리는 부분이 동시에 진행됩니다.
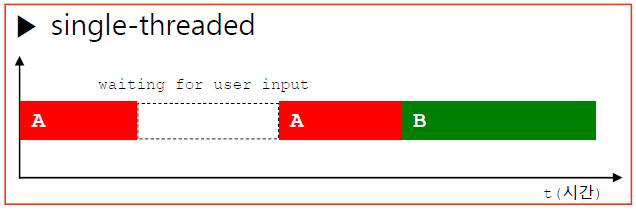
위의 그림처럼 단일 쓰레드 프로그램에서는 사용자의 입력을 기다리는 동안 시간이 낭비되는 문제가 있습니다. 여러 쓰레드를 사용하게 되면 기다리는 동안 다른 작업을 수행할 수 있기 때문에 이러한 시간 낭비 문제를 해결할 수 있습니다.
이걸로 멀티쓰레딩 프로그램의 첫 번째 포스트가 끝났습니다. 드디어 Java 포스트도 한 개만 남았습니다. 꼭 올해가 끝나기 전에 끝내도록 하겠습니다. 읽어주셔서 감사합니다!
Leave a comment