
Expressions and the Assignment Statement

7장의 주제는 식과 배정문입니다. 이번 장을 한 문장으로 요약하면 다음과 같습니다.
“식의 연산자 수행 순서는 언어의 결합성과 우선순위 규칙에 따라 결정됩니다. 폰 노이만 구조 환경에서 배정문은 가장 기본적인 문장입니다.”

가장 먼저 산술식(Arithmetic Expression)에 대해 알아보겠습니다. 프로그래밍 언어에서 수학의 산술식과 동일하게 표현하는 것은 고급 언어의 주요 목표 중 하나였습니다. 따라서 프로그래밍 언어에서의 산술식은 수학에서의 관례를 그대로 가져온 경우가 많습니다.
따라서 연산자의 수행 순서는 수학에서의 그것과 거의 동일합니다.
-
식 하나에 서로 다른 우선순위 수준의 연산자가 수행되는 순서는 우선순위의 계층 구조로 평가합니다. 예를 들어, a + b * c에서 * 연산은 + 연산보다 높은 계층에 있기 때문에 먼저 계산합니다.
-
단항 + 연산자를 항등 연산자(Identity Operator)라고 부릅니다. 왜냐하면 피연산자에 대해 아무런 효과를 미치지 않기 때문입니다. A로 표시하나 +A로 표시하나 의미는 동일합니다. 단항 - 연산자는 피연산자의 부호를 변경합니다. 일반적으로 단항 연산자는 다른 연산자와 인접하는 것을 피하기 위해 소괄호를 사용합니다.
-
명령형 언어의 연산자 우선순위 규칙은 거의 모두 동일합니다.

식에서 동일한 우선순위를 갖는 연산자가 여러 개 존재할 경우, 어떤 연산자가 먼저 수행될 것인지는 프로그래밍 언어의 결합 법칙(Associativity Rule)에 따릅니다. 프로그래밍 언어의 결합 법칙은 일반적으로 왼쪽에서 오른쪽 순서입니다. 예를 들어, A - B + C - D 식에서는 A - B가 가장 먼저 계산됩니다. 그러나 예외적인 경우도 있는데, C 언어에서 ++, –, 단항 연산자 +과 -인 경우에는 오른쪽부터 계산됩니다. APL은 특이하게도, 연산자 우선순위가 존재하지 않고 무조건 오른쪽부터 왼쪽으로 수행합니다. 예를 들어, A * B + C 라는 연산이 있다면, APC은 B + C를 먼저 수행합니다.
만약 컴파일러가 연산자 수행 순서를 변경할 수 있는 경우, 식의 수행을 위한 코드를 더 빨리 생성할 수 있습니다. 무슨 말이냐 하면, 예를 들어 A + B + C + D라는 식이 있다고 가정해봅시다. 기본적으로 정수의 덧셈은 우선순위가 동일하기 때문에 왼쪽부터 수행하게 됩니다. 만약 A와 B가 매우 큰 양수이고, C와 D가 절대값이 매우 큰 음수라면, 순서대로 덧셈을 진행했을 때 A + B는 오버플로를 야기하게 됩니다. 이것은 수학의 문제가 아니라 컴퓨터 산술의 한계로 인해 발생하는 것이기 때문에, 컴퓨터에서는 이것이 동일한 연산이 아닐 수도 있다는 뜻이 됩니다. 따라서 컴파일러가 이러한 덧셈 연산의 순서를 재조정하면 오버플로 문제를 회피할 수 있습니다.
또한 프로그래머는 식에 괄호를 포함하여 우선순위 규칙이나 결합 법칙을 변경할 수 있습니다. 예를 들어, (A + B) * C 와 같이 괄호를 포함하여 우선순위가 낮은 덧셈 연산을 곱셈 연산보다 먼저 처리하게 만들 수 있습니다.

만약 연산자의 피연산자가 부작용(Side Effect)을 갖고있다면, 피연산자의 수행 순서가 중요합니다. 함수적 부작용이란, 함수가 매개변수나 전역 변수를 변경하는 것을 말합니다. 예를 들어, 위 슬라이드 중간에 있는 코드를 보겠습니다. sub1 프로시저에서 정수형 변수 a가 선언되어 있습니다. 그런데 하위 프로시저 sub2에서 a에 10을 할당하고, b에 a + fun(b)를 할당합니다. 문제는, 함수 fun()에서 a의 값을 변화시키는 명령어가 있다는 것입니다.
이런 경우 a + fun(b)에서 fun(b)의 실행 순서의 따라 15가 될지, 32가 될지 달라집니다. 이러한 문제를 해결하기 위한 두 가지 해결책이 있습니다. 첫 번째 방법은 처음부터 언어를 설계하는 컴퓨터과학자가 함수적 부작용을 허용하지 않게 만들어서 함수 결과가 식의 값에 영향을 미치는 것을 막는 것입니다. 그러나 명령형 언어에서 이것을 허용하지 않게 되면 프로그램의 유연성이 감소시키는 또 다른 문제가 발생합니다. 예를 들어, 함수적 부작용을 막는다면 함수에서 전역 변수에 접근할 수 없습니다. 두 번째 방법은 식에 포함된 피연산자들이 특정 순서로 수행된다고 정의하는 것입니다. 예를 들어, Java 언어는 피연산자들이 무조건 왼쪽부터 오른쪽으로 수행되는 것으로 정의되었기 때문에 예제 코드와 같은 상황에서 항상 15의 결과가 나옵니다.

또한 최근 대부분의 고급 언어에서는 if-then-else 문으로 조건 연산을 수행합니다. C 언어 같은 경우에는 더 간단하게 ? 연산자로 표기할 수 있습니다.
산술 연산자는 여러 가지 목적으로 사용될 수도 있습니다. 예를 들어, + 연산자는 일반적으로 정수나 실수의 덧셈 연산을 수행하는 연산자이지만, Java 언어에서는 문자열을 잇는데 사용할 수도 있습니다. 이것을 연산자 오버로딩(Operator Overloading)이라고 부릅니다. 연산자 오버로딩을 남용하면 가독성이나 신뢰성을 낮출 수 있기 때문에 사용에 주의해야 합니다.
예를 들어 Fortran 언어에서 + 연산은 정수 피연산자에 사용하면 정수 덧셈, 실수 피연산자에 사용하게 되면 실수 덧셈을 수행합니다. 이것은 수학적으로도 일반적인 표현이기 때문에 크게 문제가 되지 않지만, C 언어에서 & 연산자는 이것과 경우가 조금 다릅니다. & 연산자를 이항 연산으로 사용하면 논리 AND 연산을 수행하지만, 단항 연산자라면 변수의 주소를 불러옵니다. 이 경우 만약 C 언어에서 실수로 왼쪽의 피연산자를 누락한다면 컴파일러는 이 오류를 탐지하지 못합니다.
Pascal 언어는 연산자 오버로딩을 피하기 위해 실수 나눗셈에는 / 연산자를 사용하고, 정수 나눗셈에는 div 연산자를 사용합니다.
또한 프로그래밍 언어 중에서는 사용자 정의 연산자 오버로딩을 허용하는 경우도 있습니다. 예를 들어 Ada 언어는 오버로딩 된 연산자를 발견하면 피연산자의 타입에 따라 올바른 의미를 선택합니다.

다음으로 타입 변환(Type Conversion)에 대해 알아보겠습니다. 타입 변환에는 두 가지 종류가 있는데, 컴파일러에 의해 수행되는 묵시적 타입 변환(Coercion)과 프로그래머가 명시적으로 수행하는 타입 변환(Casting)이 있습니다.
타입 변환으로 데이터 타입은 축소될 수도 있고 확장될 수도 있습니다. Java 언어에서 double 데이터 타입을 float로 변환하는 것은 축소 변환(Narrowing Conversion)입니다. 반대로 float 데이터 타입을 double로 변환하는 것은 확장 변환(Widening Conversion)입니다. 확장 변환은 거의 항상 안전하지만, 축소 변환은 상황에 따라 값의 크기가 변경될 수 있으므로 위험합니다.
확장 변환은 대부분 안전하지만, 정확성을 낮추는 문제가 발생할 수도 있습니다. 예를 들어, int 데이터 타입을 float로 변환한다고 가정해봅시다. int는 일반적으로 32비트에 저장되는데, float도 마찬가지로 32비트에 저장됩니다. 따라서 int에서의 정수는 9자리 십진수까지 정확하게 저장할 수 있지만, float는 단지 7자리 십진수까지의 정확성만 보장됩니다. 따라서 정수 데이터 타입에서 부동 소수점 데이터 타입으로의 확장 변환은 정확성 손실이 발생할 수 있습니다.

묵시적 타입 변환의 설계 방법에 대해 자세히 알아보겠습니다. Fortran 77의 경우 모든 숫자형 데이터 타입은 확장 변환으로만 묵시적 타입 변환이 수행됩니다. 고전 C 언어의 경우에는 거의 항상 확장 변환이 수행됩니다. 예를 들어, float나 short int와 같은 데이터 타입으로도 수행 가능한 연산이라고 할지라도, 식이나 매개변수로써 사용될 때 항상 double이나 int로 강제 변환됩니다.

만약 하나의 식 안에 여러 데이터 타입이 혼재할 때도 타입 변환이 일어날 수 있습니다. 이것은 타입 검사와도 연관된 내용입니다.
예를 들어 Fortran 77에서, A, B, C는 정수형 변수로, D는 실수형 변수로 정의가 되어 있습니다. 그리고 C = FUN(A + D) 식을 수행하는데, FUN() 함수는 매개변수로 정수형 변수가 들어가야 합니다. 이 경우 A + D가 정수 + 실수이기 때문에 엄밀한 타입 검사를 수행할 경우 오류가 발생해야하지만, Fortran 77은 이것을 오류로 탐지하지 않고 A를 실수 타입으로 강제로 변환합니다. 이와 달리 Ada 언어와 Modula-2 언어는 식에서 정수와 부동 소수점 실수의 연산을 허용하지 않습니다.
명시작 타입 변환은 Ada 언어와 Modula-2 언어에서 함수 호출로 수행합니다. 예를 들어, FLOAT(SUM)과 같이 함수의 매개변수로 변수를 넣어서 그 반환값을 원하는 데이터 타입으로 받은 구조입니다. C 언어에서는 소괄호를 이용하여 (int) SUM과 같이 표기합니다.
이러한 타입 변환은 식의 오류를 발생시킬 수도 있습니다. 이런 오류는 주로 컴퓨터의 산술 연산의 한계로 인해 발생합니다. 계산 결과가 너무 작으면 언더플로(Underflow)나 너무 크면 오버플로(Overflow) 문제가 발생할 수 있습니다. 또한 강제 변환으로 인해 값이 0으로 변환되어 나눗셈에서 오류가 발생할 수도 있습니다. 이러한 오류를 예외(Exception)라고 부릅니다.

다음으로 관계식(Relational Expression)에 대해 알아보겠습니다. 관계식은 2개의 피연산자와 1개의 관계 연산자(Relational Operator)로 이루어진 식입니다. 관계식의 결과값은 Boolean 타입(True/False)입니다. 관계 연산자는 일반적으로 다양한 데이터 타입에 대해 오버로딩 될 수 있습니다. 관계식의 참이나 거짓을 결정하는 연산은 피연산자의 타입에 따라 달라집니다. 피연산자가 정수인 경우에는 단순하지만, 문자열인 경우에는 다소 복잡할 수도 있습니다. 관계 연산자는 항상 산술 연산자보다 우선순위가 낮다는 특징이 있습니다.

불리안 식(Boolean Expression)은 불리안 변수, 불리안 상수(True or False), 관계식, 불리안 연산자로만 구성된 식을 말합니다. 불리안 연산자는 AND, OR, NOT을 말합니다. 이러한 식에서도 연산자간의 우선순위가 존재합니다. (C99 이전의) C 언어 같은 경우에는 Boolean 타입이 없기 때문에 Boolean 값도 없습니다. 대신 0은 false, 그 외의 값은 모두 true로 취급합니다. 따라서 a > b > c와 같은 연산이 가능하지만, 실제 이 식에서 b > c 연산은 수행되지 않습니다. C 언어는 이러한 특성으로 인해 불리안 식에서 오류를 감지하기 어렵습니다.

단락 평가(Short-circuit Evaluation)는 모든 피연산자와 연산자를 수행하지 않고 결과가 결정되는 것을 말합니다. 예를 들어, (13 * A) * (B / 13 - 1) 이란 식은 A가 0이라면 나머지 식을 계산할 필요도 없이 0이 나옵니다. 그러나 컴퓨터는 실행 중에 이러한 산술식을 쉽게 발견하기 어렵기 때문에 일반적으로 고려되지 않습니다.
그러나 불리안 식의 경우는 조금 다릅니다. 예를 들어, (A >= 0) and (B < 10)라는 식은 A < 0이면 (B < 10)의 결과는 볼 필요도 없습니다. 산술식과는 달리, 컴퓨터는 이러한 단락을 쉽게 발견할 수 있습니다.
Pascal 언어에서는 단락 평가를 사용하지 않으므로 때때로 실행 시간 오류를 발생시킵니다. 예제의 코드를 보면, 단락 평가를 사용하지 않을 때는 항상 while 문 내의 두 개의 식을 모두 수행합니다. 이 식에서 마지막 루프에서 index의 값은 11이 되는데, 만약 단락 평가를 사용한다면 (index <= listlen)이 False이기 때문에 바로 while문을 빠져나옵니다. 그러나 단락 평가를 사용하지 않는다면 (list[index] <> key) 식까지 수행해야 하는데, 이 때 list[11]은 배열의 범위 밖이기 때문에 실행 시간 오류가 발생합니다.
Fortran 언어에서는 결과를 결정하는 데 필요한 것보다 더 많은 식을 수행하지 않도록 선택할 수 있습니다. 그런데 이 경우에도 문제가 발생할 수 있습니다. 만약 수행하지 않는 식에 부작용이 있는 경우인데요, (a > b) || (b++ / 3)에서 (a > b)가 True이면 뒤의 연산은 수행할 필요가 없습니다. 그런데 이 식에는 ++ 라는 증감 연산자가 포함되어 있습니다. 프로그래머는 항상 이 식이 수행될 때마다 b의 값을 증가시키고 싶었겠지만, 그것이 수행되지 않는다면 의도대로 동작하지 않는다는 문제가 발생합니다.

Ada 언어에서는 프로그래머가 and then과 or else의 연산자를 사용하여 불리안 연산자 and와 or가 단락 평가를 할 수 있도록 허용합니다. 슬라이드에 나온 코드는 이전 슬라이드의 Pascal 언어와 동일한 역할을 수행하지만, 범위를 벗어난 실행 시간 오류를 발생시키지 않습니다.
C 언어와 Modula-2에서는 AND와 OR 연산 모두 기본적으로 단락 평가를 수행합니다.

단락 평가의 여부는 Ada 언어와 같이 프로그래머에게 선택권을 주는게 가장 좋은 설계입니다. Ada의 and then과 or else는 불리안 식의 일부를 조건부로 평가하는데 사용됩니다. 단락 평가의 올바른 사용은 이전 슬라이드의 코드처럼 예외를 발생시키는 식의 수행을 방지하는 것입니다.
단락 평가의 여부를 프로그래머에게 맡겼기 때문에 프로그래머는 코드 설계를 정확하게 수행할 필요가 있습니다. 예를 들어, 중간에 있는 코드에서 G(Dog)는 Dog가 null이 아닌 경우에만 수행됩니다. and then이 없으면 항상 G(Dog)가 수행되어 Dog가 null 일 때 예외가 발생합니다.
Ada에서 and then과 or else는 오버로딩 될 수 없으므로, 엄밀히 말하면 연산자가 아닙니다.

배정문(Assignment Statement)은 명령형 언어의 핵심 구성 요소 중 하나로써, 프로그래머가 변수에 대한 값의 바인딩을 동적으로 변경할 수 있는 메커니즘입니다.
가장 간단한 배정문은 대상 변수, 배정 연산자, 식으로 구성되어 있습니다. 배정 연산자(Assignment Operator)는 최근 대부분의 언어에서 ‘=’를 사용합니다만, 과거에는 동등 연산자과 구분하기 위해 ‘:=’를 사용했습니다. 현재 동등 연산자는 ‘==’를 사용하기 때문에 배정 연산자와 구분이 가능합니다.
프로그래밍 언어에 따라 대상이 여러 변수인 경우에도 배정이 가능한 경우가 있습니다. 예를 들어, PL/I의 경우에는 SUM, TOTAL = 0을 사용하면 SUM과 TOTAL 변수에 모두 0이 배정됩니다. C 언어의 경우에는 SUM = TOTAL = 0을 이용하서 같은 배정을 수행할 수 있습니다.
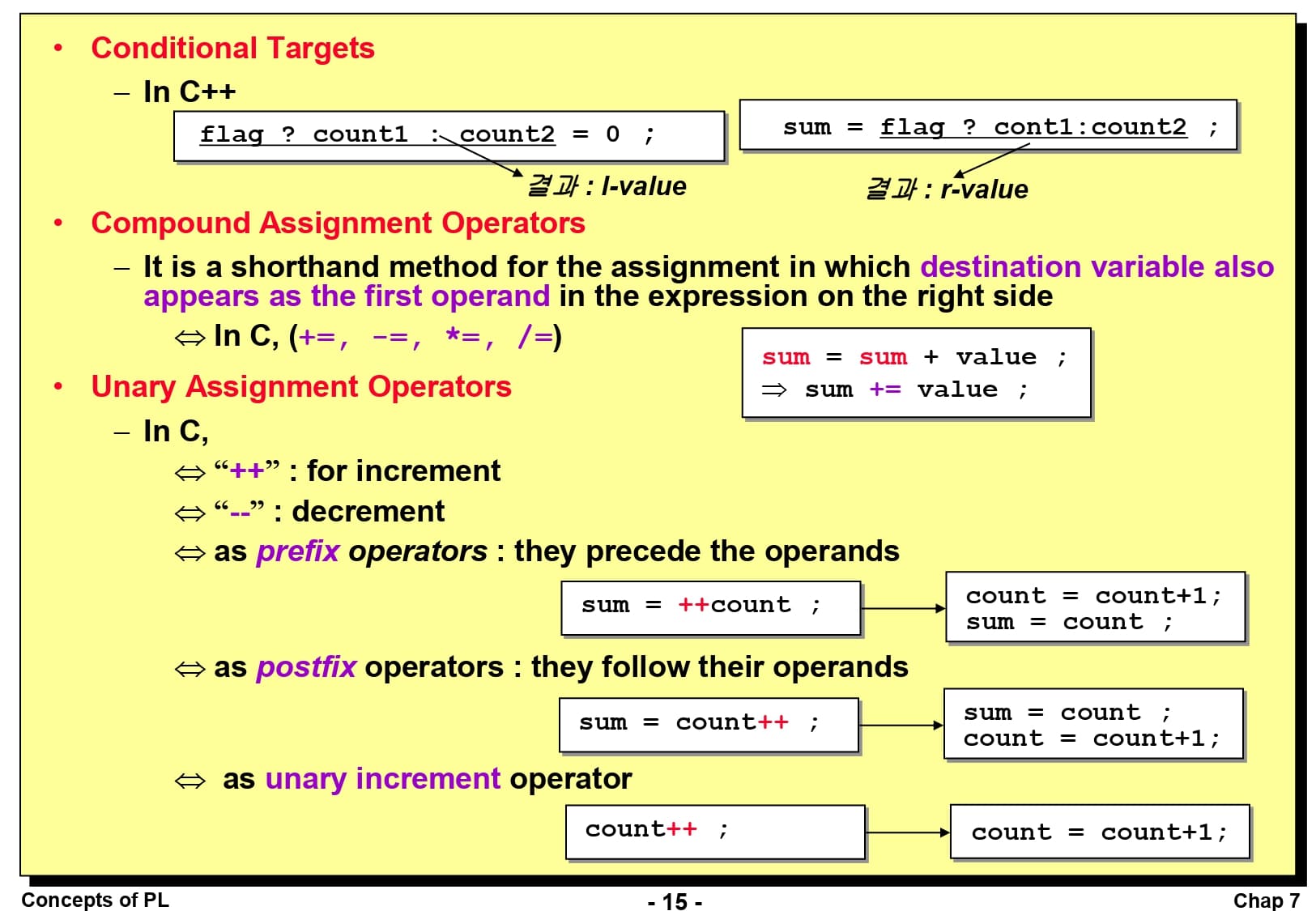
배정문에 조건을 넣어 값을 배정하는 것도 가능합니다. 예를 들어, C++ 언어에서 flag ? count1 : count 2 = 0; 라는 표현은 다음 코드와 동일한 의미를 갖습니다.
if (flag){
count1 = 0;
} else {
count2 = 0;
}
복합 배정 연산자(Compound Assignment Operator)는 배정문의 좌변과 우변에서 공통적으로 사용되는 피연산자를 축약하는 방법입니다. 예를 들어, C 언어에서는 sum = sum + value; 와 같이 좌변과 우변에서 동일한 변수가 사용될 경우 sum += value;로 표현하는 것을 허용합니다.
단항 배정 연산자(Unary Assignment Operator)는 증가 연산이나 감소 연산을 배정문으로 축약하여 단일 연산자로 사용하는 방법입니다. 예를 들어, C 언어에서는 count = count + 1;을 count++;로 축약하여 표현할 수 있습니다. 단항 배정 연산자를 지원하지 않는 언어는 대표적으로 Python 언어가 있습니다.

C를 비롯한 C 기반 언어들에서 배정문은 배정되는 값과 동일한 결과를 생성합니다. 그래서 배정문 자체를 식의 피연산자로 쓸 수 있습니다. 예를 들어, 슬라이드의 반복문에서 ch = get() 이라는 배정문이 있습니다. 이때 ch에는 표준 입력으로 받은 문자가 들어가지만, ch = get()의 수행 결과도 동일하게 해당 문자가 들어갑니다. 이 때, 반드시 소괄호로 영역을 지정해줘야 합니다. 왜냐하면 배정 연산자는 관계 연산자보다 우선순위가 낮기 때문입니다. (그 경우 ch에는 0이나 1의 값이 들어갑니다)
이러한 표현을 허용하는 것은 가독성을 매우 낮추는 단점이 있습니다. 대신 이 방법을 통해 sum = count = 0;처럼 여러 대상에게 동시에 할당하는 것이 가능해집니다. 다만 이로 인해 관련 오류를 찾기 힘들어지는 단점이 있습니다. C 언어를 처음 배울 때 조건문에 x == y가 아니라 x = y를 입력하는 실수를 하신 분들이 많을겁니다. 만약 이것이 오류라면 컴파일러가 오류를 잡아주지만, C 언어에서는 이게 정상적인 식으로 인식되기 때문에 직접 눈으로 찾지 않는 이상 발견할 수 없다는 문제가 있습니다. 따라서 Java 언어는 이것을 불허하여 이 문제를 예방하고 있습니다.

혼합형 식과 마찬가지로 혼합형 배정문(Mixed-mode Assignment)도 존재할 수 있습니다. 혼합형 배정문을 설계할 때는 다음을 고려해야 합니다.
- 식의 타입이 할당되는 변수의 타입과 동일해야 하는가?
- 두 타입이 일치하지 않는 경우에는 타입 강제 변환을 사용해야 하는가?
Fortran 언어(그리고 C)에서는 혼합형 식에서 사용되는 것처럼 혼합형 배정문에 타입 강제 변환을 사용합니다.
Pascal 언어에서는 부동 소수점 변수에 할당할 수 있는 일부 강제 변환 정수가 포함되어 있습니다.
Ada 언어나 Modula-2 언어에서 할당할 때는 정수를 부동 소수점으로 강제 변환하는 것을 허용하지 않습니다.
7장의 내용은 여기까지입니다. 읽어주셔서 감사합니다!
Leave a comment