
Data Types

6장에서는 데이터 타입의 개념과 각 데이터 타입의 특성을 소개합니다. 이번 장을 한 문장으로 요약하면 다음과 같습니다.
“컴퓨터 프로그램은 데이터를 조작하여 결과를 생성합니다. 이 작업을 쉽게 수행할 수 있는지 판단하는 중요한 요소는 데이터 타입이 실제 문제와 얼마나 유사한가입니다.”

데이터 타입(Data Type)은 데이터 값들의 모임과 그 값들에 대해 미리 정의된 연산들의 집합으로 정의됩니다. 프로그램은 데이터를 토대로 여러 연산을 통해 결과를 도출하기 때문에, 사용하는 언어에서 제공하는 데이터 타입이 현실의 문제와 얼마나 잘 매칭되는가가 중요합니다.
몇 가지 사례를 소개하자면, Fortran 90 이전에는 기본적인 데이터 구조만을 지원했기 때문에, 연결 리스트나 트리가 모두 배열로 구현되었습니다. COBOL은 십진수의 데이터 값과 레코드를 위한 데이터 타입을 지원했습니다. PL/I는 다양한 분야에 사용하는 것을 목적으로 만들어졌기 때문에 많은 데이터 타입을 지원하였습니다. ALGOL 68은 기본적인 데이터 타입을 지원하되, 필요한 경우 사용자가 직접 만들 수 있는 데이터 타입을 지원하였습니다. Ada 언어에 이르러서는 추상 데이터 타입을 지원하기 시작했습니다. 추상 데이터 타입은 직접적으로 구현 방법을 명시하지는 않고 데이터와 데이터에 대한 연산을 나타내는 것입니다.

원시 데이터 타입(Primitive Data Type)은 다른 타입의 관점에서 정의되지 않은 데이터 타입을 말합니다. 즉, 언어에서 기본적으로 제공하는 데이터 타입이라고 생각하시면 됩니다. 이러한 데이터 타입은 표현과 연산이 하드웨어에서 지원하는데, 구조화된 타입을 제공하기 위해서는 원시 데이터 타입과 함께 한 개 이상의 타입 생성자가 함께 사용됩니다.
원시 데이터 타입 중 수치 타입(Numeric Type)에 대해 알아보겠습니다. 수치 타입 중 가장 대표적인 타입이 바로 정수(Integer)입니다. 정수형 타입은 컴퓨터에 따라 다른 크기가 지원되는데, 예를 들어 byte, word, long word, quadword 등이 있습니다. C, C++, C# 등과 같은 언어에서는 부호가 없는 정수(Unsigned Int) 타입을 지원하는데, 이것은 주로 이진 데이터에 대해 사용합니다.
Word가 실제로 메모리에 차지하는 비트의 수는 컴퓨터의 CPU에 따라 달라집니다. (16비트 컴퓨터, 32비트 컴퓨터 등)
정수 자료형을 구현할 때는 비트 문자열로 표기하며, 일반적으로 가장 왼쪽에 있는 비트는 부호를 나타냈습니다. 그러나 최근에는 덧셈과 뺄셈 연산이 편리한 2의 보수(2’s Compliment) 표기법을 많이 사용합니다.

실수를 모델링하기 위해서는 일반적으로 부동 소수점(Floating Point)을 사용합니다. 그러나 부동 소수점은 대부분 실수 값을 근사할 뿐입니다. 많이 사용되는 실수인 $\pi$나 $e$ 조차 정확하게 표기가 불가능합니다. 예를 들어 십진수 0.1을 부동 소수점으로 표기한다면, 이진수 0.0001100110011…로 정확하게 표현되지 않습니다.
부동 소수점 데이터 타입은 대부분의 언어에 포함되어 있지만, 많은 소형 컴퓨터에서는 하드웨어에서 지원하지 않는 경우가 많습니다. 이런 경우 고정 소수점 방식을 사용하거나, 아니면 근사치를 나타낸 표를 저장하여 처리하기도 합니다. 그러나 이런 경우까지 고려하실 필요는 없고, 과학적인 프로그래밍을 지원하는 언어에서는 일반적으로 float와 double이라는 두 가지 타입을 제공합니다.
부동 소수점은 IEEE 754 규격을 이용하여 구현하는데, 이것은 부호 비트, 지수부, 소수부로 구성되어 있습니다. double 타입은 일반적으로 더 정밀한 소수를 표현하기 위해서 사용하므로, float 타입에 비해 두 배 이상의 소수부를 갖고 있는 것을 볼 수 있습니다.

비즈니스 업무에 사용하는 것이 상정된 컴퓨터들은 하드웨어에서 십진수(Decimal) 데이터 타입을 지원합니다. 십진수 타입은 부동 소수점과 다르게 제한된 범위 내에서 소수 값을 정확하게 저장할 수 있는 장점이 있습니다. 대표적인 십진수 데이터 타입은 BCD(Binary Coded Decimal)로, 이진수 코드를 사용하여 문자열과 비슷하게 저장하는 방식입니다. BCD에는 packed 방식과 unpacked 방식이 있습니다. unpacked 방식은 자리수 하나당 1개의 바이트를 이용해서 표현하는 방식이고 (4개는 의미 없음), packed 방식은 2개의 자리를 1개의 바이트로 압축하여 표현하는 방식입니다. unpacked 방식의 경우 남는 4개의 비트를 1로 채우지만, 마지막 글자의 경우 숫자가 양수인지 음수인지에 따라 다릅니다. 양수의 경우 1100, 음수의 경우에는 1101로 표현합니다.

불리안 타입(Boolean Type)은 참과 거짓만 나타낼 수 있는 가장 간단한 데이터 타입입니다. ALGOL 60에서 처음 도입되었으며, 스위치나 플래그를 표현하기 위해서 사용합니다. 불리안 타입은 한 개의 비트로 표현이 가능하지만, 컴퓨터에서 한 개의 비트를 효율적으로 접근할 수 없기 때문에 일반적으로 1개의 바이트로 구현됩니다.
문자 타입(Character Type)은 일반적으로 수치 값으로 컴퓨터에 저장됩니다. 가장 많이 사용하는 기법은 ASCII(American Standard Code for Information Interchange)로써 0부터 127까지의 값을 사용합니다. 그러나 세계화가 이루어짐에 따라 128개의 글자가 부족해졌고, 결국 1991년 Unicode라는 새로운 규격이 만들어졌습니다. C 언어와 C++ 언어는 계속 ASCII 코드를 사용하지만, Java, Python과 같이 그 뒤에 나온 언어들은 Unicode를 사용하여 문자를 저장합니다.

문자열 타입(Character String Type)은 문자들로 구성되는 타입입니다. 문자열은 문자 조작을 하는 모든 프로그램에서 필수적인 데이터 타입입니다. 문자열 타입을 설계할 때 중요한 두 가지 고려사항이 있습니다.
- 스트링이 원시 타입인가, 아니면 단순히 문자 배열의 특수한 종류인가?
- 스트링이 정적의 길이를 갖는가, 아니면 동적인 길이를 갖는가?
먼저 첫 번째 고려사항부터 살펴보겠습니다. 문자열을 단순히 문자의 배열로 취급하는 대표적인 언어가 바로 C 언어입니다. 이러한 언어들에서는 표준 라이브러리를 통해 문자열 연산 기능을 제공하며(string.h), 널 문자(\0)를 이용하여 문자의 끝을 나타냅니다.
반대로 문자열을 원시 타입으로 제공하는 언어들도 있습니다. Java나 Python이 채택한 방법인데, 이러한 방법은 언어의 작성력이 증가하며 그에 따른 비용도 크지 않다는 장점이 있습니다. 원시 타입으로 문자열 타입을 제공할 경우, 할당, 관계 연산자, 연결 및 하위 문자열 참조와 같은 기능을 기본 연산으로 제공합니다.

다음으로는 문자열 길이에 관한 고려사항입니다. 생성될 때 길이가 같이 정해지는 문자열을 정적 길이 스트링(Static Length String)이라고 합니다. Fortran 77과 90, COBOL, Ada 언어에서 기본적으로 제공하는 문자열이 바로 이런 방식입니다.
다른 방법으로는 문자열 변수를 선언할 때 길이가 같이 선언되지만, 고정된 최대 길이까지 가변적인 길이를 갖는 것을 허용하는 제한된 동적 길이 스트링(Limited Dynamic Length String)이 있습니다. C 언어에서의 문자열이 바로 이런 구조입니다. 왜냐하면 문자열의 길이를 나타낼 때, 배열의 길이 자체가 변하는 것이 아니라 널 문자가 어디에 있는지에 따라 문자열의 끝이 달라지기 때문입니다.
마지막 방법은 문자열이 최대 길이의 제한 없이 가변 길이를 갖는 것을 허용하는 동적 길이 스트링(Dynamic Length String) 방식입니다. JavaScript나 C++ 언어가 이러한 방식을 채택하고 있는데, 동적 기억공간 할당과 회수에 따른 부담이 늘어나지만 유연성을 갖는다는 장점이 있습니다.
특이하게 Ada 95 이후의 Ada 언어는 이 세 가지 방법을 모두 지원합니다.

문자열 타입은 언어의 작성력에 중요한 요소입니다. 문자열을 배열로 다루는 것은 원시 타입으로 다루는 것보다 더 복잡해질 수 있습니다. 예를 들어, C 언어에서 strcpy를 사용하지 않고 구현한다고 하면 반복문이 반드시 필요합니다. 프로그래밍 언어에서 문자열을 원시 타입으로 추가하는 것은 비용도 거의 들지 않는 일이기 때문에 굉장히 비효율적인 일입니다. 따라서 현대 프로그래밍 언어에서는 대부분 문자열을 원시 타입으로써 제공합니다. 패턴 매칭이나 접합과 같은 연산은 대부분의 프로그램에서 필수적이기 때문입니다.
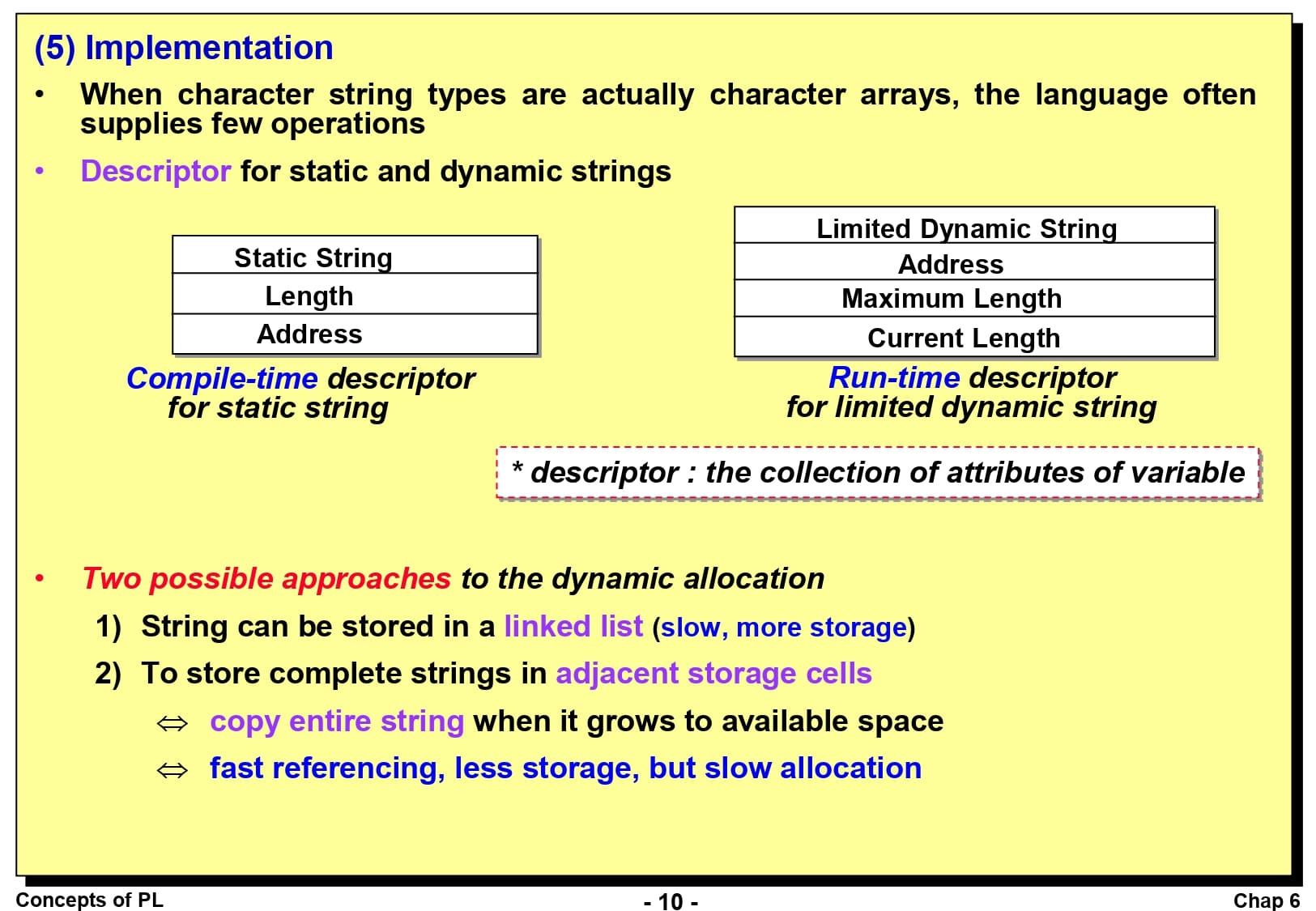
문자열 타입은 하드웨어에서 직접 지원될 수도 있지만, 대부분의 경우에는 소프트웨어로써 구현됩니다. 만약 문자열 타입이 문자 배열로 표현되는 경우에는 언어 자체에서 문자열 관련 연산을 거의 제공하지 않습니다.
정적 길이 스트링에서 변수의 속성 모음(Descriptor)은 컴파일 과정에서만 요구되며, 변수 이름, 길이, 첫 번째 문자가 저장된 주소입니다. 제한된 동적 길이 스트링에서는 변수 이름, 첫 번째 문자가 저장된 주소, 최대 길이, 현재 길이가 저장되며 실행 시간 속성 모음이 필요합니다. 이 두 방법에서는 동적 기억공간 할당이 필요하지 않습니다. 제한된 동적 길이 스트링도 변수가 기억공간에 바인딩될 때 최대 길이까지 저장할 수 있는 크기만큼 할당되기 때문입니다.
그러나 동적 길이 스트링의 구현은 다소 복잡합니다. 첫 번째 방법은 연결 리스트에 문자열을 저장하는 것입니다. 만약 문자열의 길이가 늘어난다면 새로 필요한 기억공간은 힙의 무작위 위치에서 생성됩니다. 이 방법은 보다 많은 공간이 필요하고 접근도 느리다는 단점이 있습니다. 두 번째 방법은 문자열 전체를 인접한 기억공간에 저장하는 것입니다. 문제는 동적 길이 스트링은 문자열이 얼마나 늘어날지 예측할 수 없다는 것입니다. 따라서 이 방법에서 문자열의 길이가 늘어난다면, 문자열 전체를 저장할 수 있는 새로운 영역으로 이동합니다. 이 방법은 첫 번째 방법에 비해 접근이 빠르고 저장공간을 비교적 적게 차지하지만, 할당 시간이 느리다는 단점이 있습니다.

순서 타입(Ordinal Type)은 가능한 값의 범위가 양의 정수의 집합과 관련이 있는 타입입니다. Pascal이나 Java에서 제공하는 기본 순서 타입은 Integer, char, boolean 등이 있습니다. 일반적으로 프로그래밍 언어에서 지원하는 사용자 정의 순서 타입은 열거(Enumeration) 타입과 부분범위(Subrange) 타입입니다.
열거 타입은 기호 상수(Symbolic Constant)인 모든 가능한 값들이 열거되는 타입입니다. 대표적으로 슬라이드에 나온 Ada 언어에서 요일을 저장한 타입이 있습니다. 이러한 열거 타입은 전형적으로 0, 1, … 등의 정수가 할당되지만, 정의에 따라 임의의 정수가 할당될 수도 있습니다. 열거 타입을 설계할 때 고려할 것들은 다음과 같습니다.
- 열거 상수가 한 개 이상의 타입 정의에 나타나는 것이 허용되는가?
- 그렇다면, 프로그램에서 이러한 상수 참조시 그 타입이 어떻게 검사되는가?
이러한 고려 사항들은 타입 검사와 관련이 있습니다. 만약 열거 변수가 수치 타입으로 강제 변환되면, 연산들의 범위나 값들에 대한 제어가 없습니다. 따라서 이제부터 각각 언어에서 열거 타입을 어떻게 구현하였는지 자세히 살펴보겠습니다.

Pascal, C, C++ 언어 같은 경우에 열거 상수는 주어진 참조 환경에서 둘 이상의 열거 타입에 사용될 수 없습니다. 또한 열거형 변수는 배열 첨자, 반복문의 변수, Case 문의 선택기로도 사용할 수 있습니다. 또한 관계 연산자와도 비교할 수 있습니다. 이러한 것들이 가능한 이유는, 열거 변수가 정수 문맥에서 사용될 때 정수형 변수로 강제 변환되기 때문입니다. 그러나 반대로 다른 타입의 값이 열거 타입으로 강제 변환되지는 않습니다.
Ada 언어 같은 경우에는 동일 환경에서 열거 상수가 두 개 이상의 선언에서 정의될 수 있습니다. 이것을 중복 리터럴(Overloaded Literal)이라고 부릅니다. Ada에서는 타입 검사를 위해 열거 변수가 정수형 변수로 강제 변환되지 않습니다. 이는 컴파일 시간에서 문맥 오류를 탐지하는 것을 가능하게 합니다.
열거 타입을 사용하는 이유는 매우 직접적인 방식으로 가독성을 증가시키기 때문입니다. 이름을 통해 정의된 값은 쉽게 인식되지만, 숫자로 코드화할 경우 쉽게 인식하기 어렵기 때문입니다. 숫자형 데이터 타입과 비교했을 때, 산술 연선이 불가능하고 범위 오류를 쉽게 감지할 수 있다는 장점이 있습니다. 열거형 변수에는 정의된 범위 밖의 값을 할당할 수 없기 때문입니다.

부분 범위 타입은 순서 타입의 연속된 부분 순서열입니다. 예를 들면, Pascal 언어에서 index를 1부터 100까지의 범위를 갖는 변수로 설정했습니다. 이것은 정수의 연속된 부분 순서열이라고 볼 수 있습니다. 부분 범위 타입을 사용하는 이유는 가독성과 안정성이 증가하기 때문입니다. 간단한 타입이기 때문에, 설계할 때 고려사항은 딱히 없습니다. 다만 왜인지 Ada 95 이후로는 대부분의 언어에서 부분 범위 타입을 지원하지 않습니다. (왜 그런지 교재 제작자도 이상하게 생각하더라구요)
앞서 소개한 대로, 이러한 사용자 정의 순서 타입의 구현은 보통 (음이 아닌) 정수로 구현됩니다. 부분 범위 타입은 범위 검사가 포함되어야 한다는 점만 제외하면 상위 유형(정수형 타입)과 동일한 방식으로 구현됩니다.

배열(Array)은 동질적인 데이터 원소들의 묶음으로, 개개의 원소는 배열의 첫 번째 원소와 상대적인 위치에서 식별됩니다. 배열의 원소들은 모두 동일한 데이터 타입을 갖고, 배열 원소에 대한 참조는 대괄호와 같은 첨자 식을 이용하여 나타냅니다. 이 때, 참조되고 있는 메모리 위치의 주소를 결정하기 위해 실행 시간 계산이 추가로 필요합니다.
배열 타입을 설계할 때 고려해야할 사항은 다음과 같습니다.
- 아래 첨자에는 어떤 유형이 적합한가? (정수형, 순서형 등)
- 아래 첨자의 범위는 언제 바인딩되는가? (실행 시간 vs 컴파일 시간)
- 배열 할당은 언제 발생하는가? (실행 시간 vs 컴파일 시간)
- 아래 첨자는 몇 개나 허용되는가? (가능한 차원의 수)
- 공간이 할당될 때 배열이 초기화되는가?
- 어떤 종류의 슬라이스가 존재하는가?
다음 페이지부터 이러한 고려 사항을 하나씩 따져보겠습니다.

배열의 원소들은 두 단계의 구문 메커니즘에 의해 참조됩니다. 첫 번째는 배열의 이름이고, 두 번째는 첨자나 색인입니다. 예를 들어, a[100]과 같이 참조할 때, a가 배열의 이름이고, 100이 첨자입니다. 선택 연산은 배열 이름과 첨자로부터 하나의 원소로 매핑하는 것으로 볼 수 있습니다.
배열에서 첨자를 표시할 때 소괄호를 이용하는 경우도 있고 대괄호를 이용하는 경우도 있습니다. Fortran과 PL/I이 개발되었을 당시에는 첨자를 나타낼 적절한 문자가 없었기 때문에 소괄호를 선택하였습니다. 그러나 소괄호를 사용하는 경우에는 함수에서 인자를 호출하는 것과 혼동될 여지가 있었기 때문에, 90년대 이후로는 대괄호를 이용하여 첨자를 표시하게 됩니다.
배열의 첨자 타입은 일반적으로 정적으로 바인딩됩니다. 먼저 첨자 범위의 하한은 C 계열 언어에서 0으로 정의되며, Fortran 1, 2, 4에서는 1로 고정됩니다. Fortran 77과 90에서도 기본적으로 1로 설정되어 있지만, 임의의 정수로 설정할 수 있습니다. 이 범위가 프로그래머로부터 명시적으로 선언되어야 하는 언어도 있습니다.


배열 첨자의 범위에 대한 바인딩과 저장공간에 대한 바인딩을 토대로 다음과 같이 네 가지 종류로 나눌 수 있습니다.
-
정적 배열(Static Array) : 첨자의 범위와 기억공간 할당이 모두 정적으로 바인딩되는 배열입니다. 따라서 실행 시간 전에 바인딩이 끝나며, 동적 할당이나 회수가 이루어지지 않기 때문에 매우 효율적이라는 장점이 있습니다. Fortran 77의 배열이 이 방법을 채택하고 있습니다.
-
고정 스택 동적 배열(Fixed Stack Dynamic Array) : 첨자의 범위는 정적으로 바인딩되지만, 기억공간 할당이 실행 시간 중에 발생하는 배열입니다. 두 개의 부프로그램이 있고, 각각 고정 스택 동적 배열을 갖고 있다면 동시에 실행되지 않는 한 그 배열들은 기억공간을 공유하기 때문에 기억공간을 효율적으로 사용할 수 있다는 장점이 있습니다. 대신 할당과 회수 시간이 별도로 소모되는 단점도 있습니다. Pascal의 지역 배열이 이 방법을 사용합니다.
-
스택 동적 배열(Stack Dynamic Array) : 첨자의 범위와 기억공간의 바인딩이 모두 실행 시간 중에 동적으로 바인딩되는 배열입니다. 그러나 일단 첨자 범위가 바인딩되고 기억공간이 할당되면 변수의 수명 동안 고정됩니다. 이 방법은 배열이 사용되기 전까지 미리 선언할 필요가 없기 때문에 유연성이 높다는 장점이 있습니다. C 언어가 대표적으로 이 방법을 사용하고 있습니다.
-
힙 동적 배열(Heap Dynamic Array) : 첨자의 범위와 기억공간의 바인딩이 모두 동적이며, 배열의 수명 동안 변경이 가능한 배열입니다. 스택 동적 배열보다 더 유연하다는 장점이 있습니다만, 힙으로부터 할당과 해제가 일어나기 때문에 더 느리다는 단점이 있습니다.
여담으로 다양한 데이터 타입을 저장할 수 있는 배열도 있습니다. 이러한 배열을 이기종 배열(Heterogeneous Array)이라고 부르는데, 배열의 원소가 동일한 데이터 타입일 필요가 없는 배열입니다. Perl, Python, JavaScript, Ruby 등에서 지원되며, 이 배열은 그 특성상 힙 동적 배열로 정의됩니다.

다음으로 다룰 내용은 배열의 첨자 수에 관한 설계입니다. 프로그래밍 언어의 역사에서 다루었듯이, Fortran I의 경우에는 첨자를 3개까지만 허용했습니다. 즉, 3차원 배열까지만 생성이 가능했다는 것입니다. 이후 Fortran 77과 90에서는 최대 7개를 지원했고, 그 이후 등장한 언어들에서는 무제한 차원의 배열이 가능했습니다.
의외로 C 언어는 1개의 첨자만 사용할 수 있습니다. 그러나 배열 자체가 배열의 원소가 될 수 있으므로, 다차원 배열의 생성이 가능한 것입니다. 이와 같은 방식을 직교 설계(Orthogonal design)이라고 부릅니다.

몇몇 언어는 배열이 기억공간에 할당되는 시점에 배열을 초기화하는 방법을 제공합니다. 예를 들어, Fortran 77에서는 모든 데이터가 정적으로 할당되므로 DATA 문을 사용한 로드 시간 초기화가 허용됩니다.
C 언어 또한 정적 배열을 이용한 초기화가 가능합니다. 그러나 동적 배열은 이런식으로 초기화가 불가능합니다.
Pascal이나 Modular-2와 같은 언어에서는 프로그램 선언에서 배열 초기화를 허용하지 않습니다.
Ada 언어는 두 가지 방법으로 배열 초기화가 가능합니다. 값을 저장하는 순서대로 나열하는 방법과 => 연산자를 사용하여 값들을 색인 위치에 직접 할당하는 방법입니다.

배열 연산(Array Operations)은 배열 단위로 연산을 수행하는 것을 말합니다. 예를 들어, 배정, 접합, 비교, 슬라이스 등이 있습니다. 이 중 슬라이스는 다음 장에서 따로 논의하도록 하고, 여기에서는 나머지 케이스만을 다루겠습니다.
Fortran 90에서는 elemental 이라고 부르는 배열 연산을 제공합니다. 제공하는 연산들이 배열 원소들의 쌍(Pair) 연산이기 때문에 그렇게 이름이 붙었다고 합니다. 대표적으로 + 연산은 두 배열의 원소 쌍들의 합을 계산한 배열입니다. 이 외에도 할당, 산술, 관계 및 논리 연산자는 모든 크기의 배열에 대해 오버로딩되어 있습니다.
APL은 가장 강력한 배열 연산을 지원하는 언어입니다. +, -, *, / 4가지 기본 산술 연산은 물론, 벡터, 행렬, 스칼라 피연산자에 대해서도 정의되어 있습니다. 내적, 외적 연산까지 지원합니다.
C 언어는 기본적으로 배열 연산을 지원하지 않습니다. Java나 C++ 언어는 메소드를 통해 일부만 지원하며, Python은 배열 접합이나 비교, 원소 추가와 관련된 일부 연산을 지원합니다.
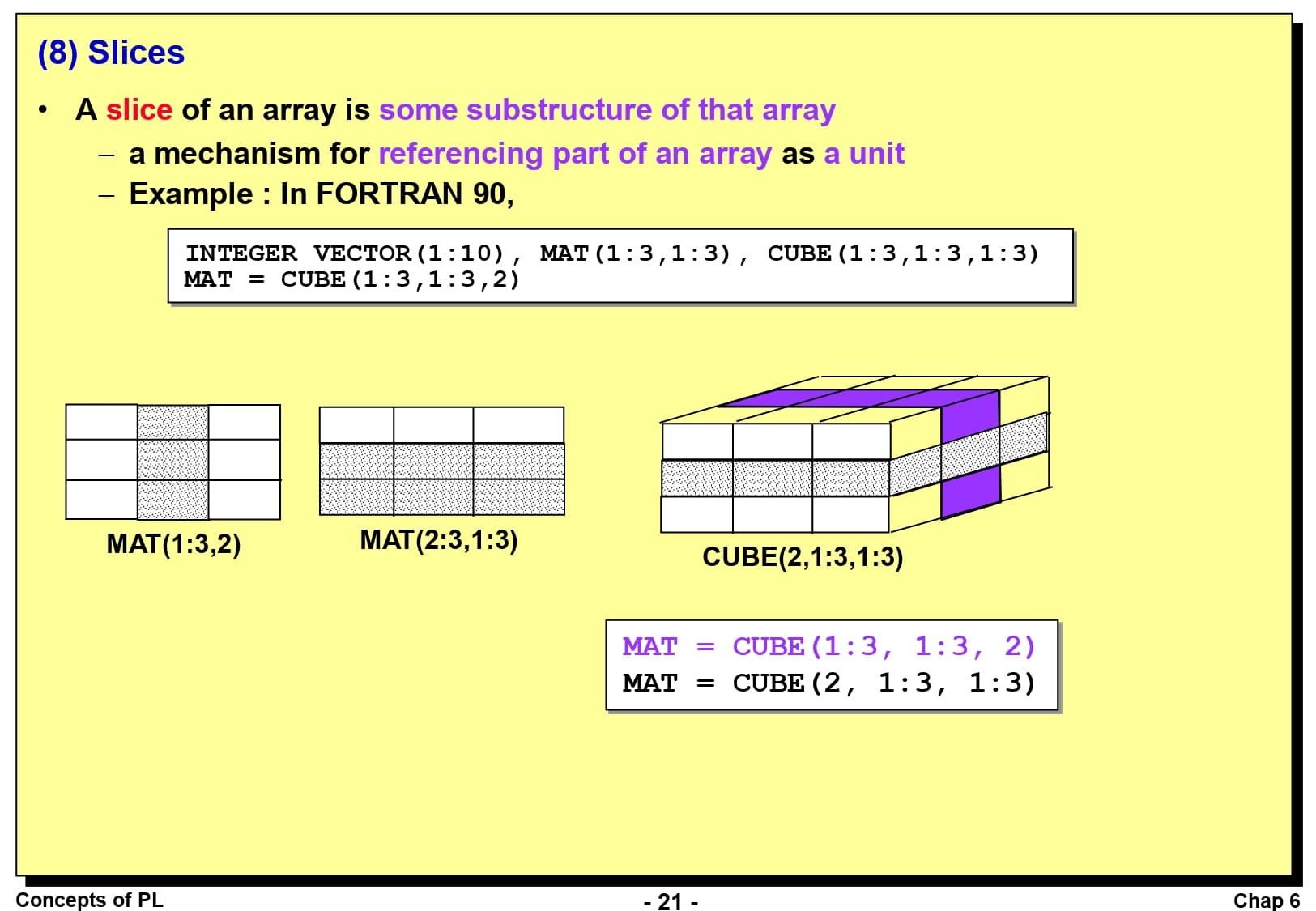
배열의 슬라이스(Slice)는 배열의 부분 구조입니다. 예를 들어, Fortran 90 언어에서 MAT(1:3, 2)는 1행부터 3행까지 2번째 열을 잘라서 만든 부분 배열이고, MAT(2:3, 1:3)은 2행부터 3행까지에서 1열부터 3열까지 자른 부분 배열입니다.
Python 언어는 더 복잡한 슬라이스를 지원합니다. 예를 들어, vector[0:7:2]는 배열의 0부터 7까지 슬라이스하는데, 2 단위로 원소들을 슬라이스하는 명령어입니다.

배열을 구현하는 것은 원시 타입을 구현하는 것보다 훨씬 더 많은 노력이 필요합니다. 왜냐하면 효율적인 실행 시간 접근을 위해서는 배열에 대한 접근 방법이 컴파일 시간에 만들어져야 하기 때문입니다.
예를 들어, list[k]의 주소를 계산한다고 가정해봅시다. 1차원 배열은 각각의 원소가 인접한 메모리로 바인딩되기 때문에 (배열 list의 시작 첨자가 1이라면) list[k]의 주소 = list[1]의 주소 + (k - 1) * 원소의 크기 로 계산할 수 있을 것입니다. 원소의 타입이 정적으로 바인딩되고, 배열이 기억공간에 정적으로 바인딩되면 이 식은 실행 시간 전에 계산할 수 있습니다.
이 식을 컴파일 시간 내에 계산하기 위해서는 1차원 배열에 대한 속성이 그림과 같은 구조로 설정되어야 합니다. 만약 이러한 항목들이 동적으로 바인딩된다면, 배열의 주소는 실행 시간에 계산할 수밖에 없습니다.
다차원 배열은 1차원 배열보다 구현하기 복잡합니다. 하드웨어 메모리는 일반적으로 선형으로 구성되어 있기 때문에, 다차원 배열을 1차원 배열로 매핑해야만 합니다. 이 때, 1차원 배열로 매핑하는 방법은 행 우선 순서(Row Major Order)와 열 우선 순서(Column Major Order)로 나눌 수 있습니다. 행 우선 순서는 1행의 내용을 저장 - 2행의 내용을 저장 - 3행의 내용을 저장 - … 순서대로 저장하는 방식이고, 열 우선 순서는 1열의 내용을 저장 - 2열의 내용을 저장 - 3열의 내용을 저장 - … 순서대로 저장하는 방식입니다. 대부분의 명령형 언어에서는 행 우선 순서대로 저장을 하며, Fortran과 같은 일부 언어에서만 열 우선 저장을 사용합니다.

다차원 배열에서 접근 함수(Access Function)는 기반 주소와 참조 값들의 집합을 메모리 주소로 매핑하는 함수입니다. 예를 들어, 행 우선 순서로 2차원 배열에 대한 접근 함수를 구해보겠습니다. 시작 주소가 a[1,1]로 주어진 상황에서, 임의의 배열 원소인 a[i,j]의 주소를 계산한다면 a[1,1]의 주소 + ((i-1)*n +(j-1)) * 원소의 크기로 계산할 수 있습니다. 이 식에서 i와 j 부분은 그 값에 따라 달리지기 때문에, 상수와 변수 부분을 구분해서 정리하면 a[1,1]의 주소 - (n+1) * 원소의 크기 + (i * n + j) * 원소의 크기로 바꿔쓸 수 있습니다. 이를 반영하여, 다차원 배열에서 컴파일 시간에 계산할 수 있는 속성은 위 슬라이드의 마지막 그림과 같습니다.
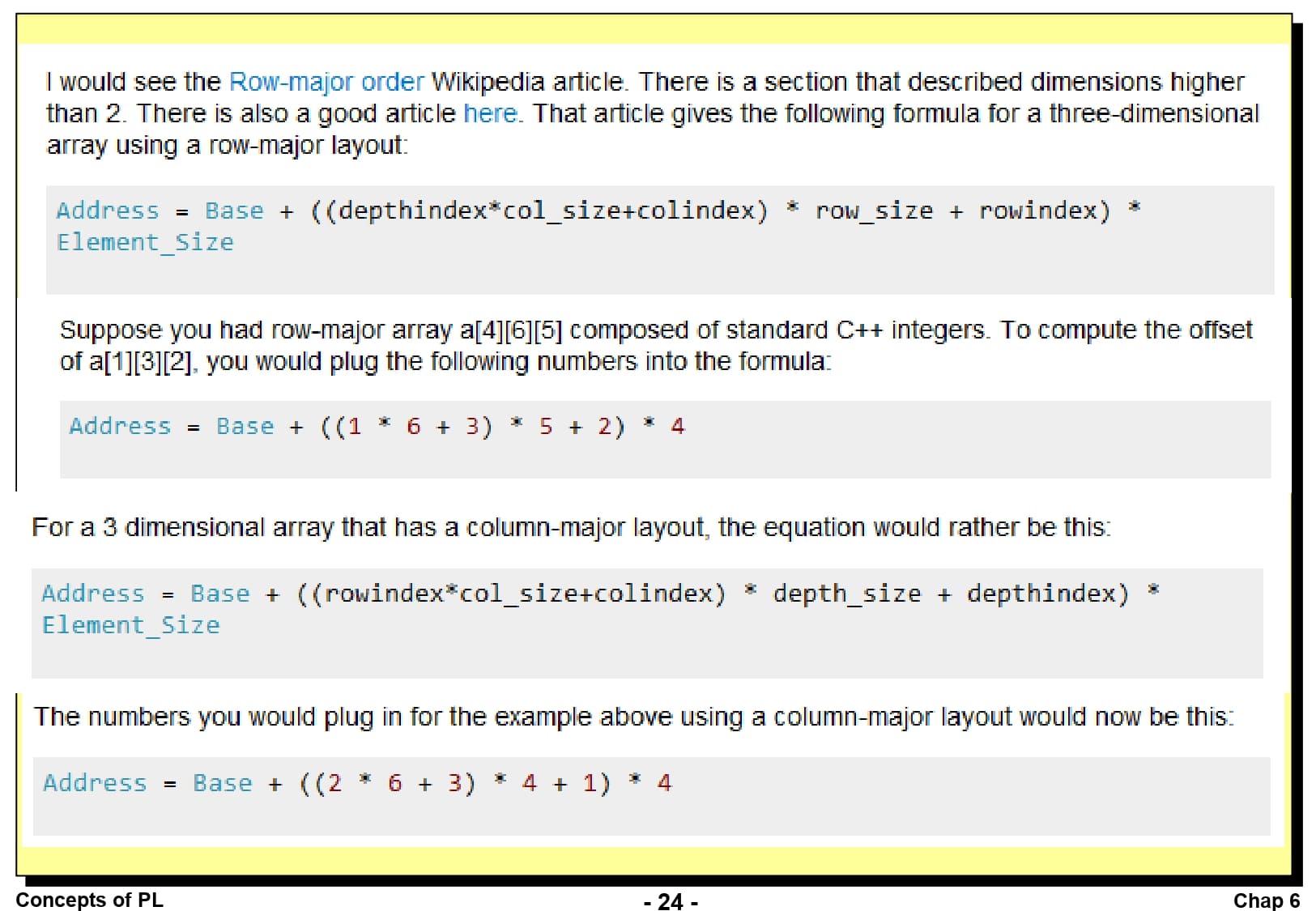
이 슬라이드는 3차원 배열에서 특정 배열 원소의 주소를 행 우선 순서/열 우선 순서로 계산하는 것을 나타낸 슬라이드입니다. 계산 방법은 쉽게 설명되어 있으니 한번 읽고 넘어가시면 될 것 같습니다.

연상 배열(Associative Array)은 키(Key)라고 불리는 원소의 개수와 동일한 개수의 값들로 참조되는 정렬되지 않은 배열을 말합니다. 일반적인 배열에서 색인 값은 전혀 정의할 필요가 없지만, 연상 배열에서는 색인 값도 키와 함께 정의되어야 합니다. 따라서 연상 배열의 실제 원소는 키와 값의 쌍으로 이루어져 있습니다. Perl, Python, Ruby 등의 언어에서는 연상 배열을 기본적으로 지원하며, Java나 C++ 언어에서는 표준 클래스 라이브러리로써 지원합니다. (ex. HashMap)
Perl 언어에서 연상 배열은 해쉬(Hash)라는 이름으로 지원됩니다. 모든 해쉬 변수는 % 기호로 시작해야 하며, => 연산자 를 이용해 키와 값을 배정합니다. Python 언어에서는 사전(Dictionary) 자료형을 통해 연상 배열을 지원합니다.
해쉬의 장점은 원소에 접근할 때 일반적인 배열보다 매우 효율적이라는 것입니다. 왜냐하면 원소에 접근할 때 사용하는 해쉬 연산이 배열보다 효율적이기 때문입니다. 따라서 만약 취급할 데이터가 이름과 급료와 같이 쌍으로 구성되어 있다면 해쉬를 사용하는 것이 좋습니다. 그러나 리스트의 모든 원소를 처리해야하는 경우에는 배열을 사용하는것이 더 낫습니다.

레코드(Record)는 각각의 원소들이 이름으로 식별되고 다양한 데이터 타입을 가질 수 있는 자료형입니다. 이러한 자료형은 1960년대 초 COBOL에서 처음 도입된 이후 가장 인기있었던 프로그래밍 언어의 요소였습니다. 배열과 비교해보자면, 배열은 색인을 통해 원소에 접근하고 모든 원소가 동일한 데이터 타입을 갖지만, 레코드는 식별자로 원소에 접근하고 원소가 다양한 데이터 타입을 가질 수 있다는 차이점이 있습니다. 예를 들면, 학생의 정보를 저장할 때 이름은 문자열, 학번은 정수, 학점은 실수로 저장해 만드는 자료형이라고 보시면 됩니다.
레코드의 구조는 언어마다 조금씩 다르게 지원합니다. 최초로 레코드를 지원했던 COBOL을 예로 들면, EMPLOYEE-RECORD 레코드는 EMPLOYEE-NAME과 HOURLY-RATE로 구성되어 있습니다. 앞의 01, 02, 05는 수준 번호로써 레코드의 계층 구조를 나타내며, PICTURE는 기억공간 형식을 나타냅니다. X(20)은 최대 20개의 글자로 이루어진 자료형을 나타내며, 99V99는 중간에 소수점을 갖는 4개의 십진수 숫자라는 의미입니다.

Ada 언어는 COBOL과는 다르게 계층 번호를 사용하지 않고 레코드 내부에 레코드를 또 선언함으로써 나타냅니다. 그리고 모든 Ada의 레코드 타입은 이름을 갖는 타입이어야만 합니다.
Fortran과 C 언어에서 중첩 레코드를 사용할 경우, 중첩된 레코드를 먼저 선언하고 상위 레코드에서 하위 레코드를 참조하는 형식으로 정의합니다.

레코드 필드를 참조하는 방법도 여러 가지가 있습니다. 먼저 COBOL 언어는 OF 라는 명령어를 사용하여 참조합니다. 예를 들어, 이전 슬라이드에 나와있던 COBOL 레코드에서 MIDDLE 이라는 필드를 참조하려면, MIDDLE OF EMPLOYEE-NAME OF EMPLOYEE-RECORD 와 같이 작성하면 됩니다. 이 외의 다른 언어들에서는 대부분 EMPLOYEE_RECORD.EMPLOYEE_NAME.MIDDLE과 같이 .(마침표)를 이용해서 표현합니다. 이렇게 마침표를 이용해 표시하는 방법을 도트 표기법(Dot Notation)이라고 부릅니다.
레코드 필드를 참조할 때 두 가지 형식이 있는데, 레코드 필드까지 모든 중간 레코드의 이름이 포함되어야 하는 완전 자격 참조(Fully Qualified Reference)와, 참조 환경이 명확하다면 레코드 이름의 일부나 전체를 생략할 수 있는 생략 참조(Elliptical Reference) 형식이 있습니다. COBOL의 레코드는 생략 참조를 허용함으로써 프로그래머의 편리성을 고려하였지만, 생략 참조는 가독성에 문제가 생길 수 있기 때문에 일반적으로 완전 자격 참조 방식을 사용합니다.

Pascal이나 Modular-2 언어 같은 경우에는 레코드를 할당하는 것이 가능합니다. Ada 언어 또한 레코드의 할당과 동일성의 비교를 지원합니다. COBOL 언어 같은 경우에는 MOVE CORRESPONDING 명령어를 통해 대상 레코드에 동일한 이름이 필드가 있을 경우 원본 레코드의 필드를 복사하는 기능을 제공합니다.

레코드 필드도 배열과 마찬가지로 인접한 메모리에 저장됩니다. 그러나 배열과는 다르게 필드의 크기가 반드시 같지는 않기 때문에 배열과는 다른 접근 방식을 사용합니다. 이러한 문제는 레코드의 시작 주소에 상대적인 오프셋 주소를 필드에 포함시킴으로써 해결합니다. 아래 그림은 컴파일 시간 속성의 형식을 나타내고 있습니다.
또한 레코드의 경우 필드별 크기가 상이하기 때문에 컴퓨터 메모리의 효율적인 접근을 위한 워드 정렬(Word Alignment)이라는 기법을 사용합니다. 예를 들어 오른쪽과 같은 구조체 코드가 있습니다. 이 경우 문자형 변수 c는 1바이트, 정수형 변수 i는 4바이트를 차지합니다. 원래라면 구조체 aa는 이 둘을 합친 5바이트를 차지해야하지만, 32비트 컴퓨터의 경우 4바이트(=32비트) 단위로 명령어를 처리하기 때문에 5바이트씩 처리하게 되면 비효율적인 접근이 발생합니다. 따라서 이 경우에는 컴퓨터가 한번에 가져올 수 있는 데이터의 크기에 맞추기 위해, 일부러 쓰지않는 3바이트를 더 배정해서 8바이트로 만드는 것이 접근에 유리합니다. 이런 용도로 추가하는 비트를 패딩(Padding)이라고 부릅니다.

공용체(Union)는 변수가 프로그램 실행 중에 다른 시간이라면 다른 타입의 값을 저장할 수 있는 타입을 말합니다. 예를 들면, 컴파일러를 위한 상수들의 테이블이 있습니다. 이 테이블은 컴파일 중인 프로그램에서 발견된 상수들을 저장하는데 사용되는데, 프로그램에 사용되는 상수들은 데이터 타입이 다양합니다. 그런데 이 테이블에 저장된 값은 동일한 테이블 필드에 저장되므로, 발견되는 데이터 타입 중 가장 큰 타입을 기준으로 기억공간이 할당됩니다. 즉, 데이터 타입의 합집합(Union)이라고 볼 수 있으므로 이러한 이름이 붙었습니다.
공용체의 주요한 설계 고려 사항은 다음과 같습니다.
- 타입 검사가 요구되어야 하는가? (만약 타입 검사가 요구된다면 반드시 동적으로 구현되어야 한다)
- 공용체가 레코드에 포함되어야 하는가?
이러한 설계 고려 사항을 참고하여 공용체가 구현된 언어를 간략하게 살펴보겠습니다.
먼저 Fortran 언어는 EQUIVALENCE라는 구문으로 공용체를 선언합니다. Fortran에서는 공용체의 타입 검사를 실시하지 않습니다. ALGOL 68 언어는 Fortran과 다르게 타입 검사를 요구합니다. 이 때, 공용체가 현재 갖고 있는 타입을 나타내기 위해 태그(Tag) 나 판별자(Discriminant)를 표기하는데, 이러한 것을 포함하는 공용체를 판별 공용체(Discriminated Union)라고 부릅니다. 판별 공용체는 실행 시간에서 타입을 검사합니다.
ALGOL 68은 판별 공용체를 적합성 문장(Conformity Clause)으로 구현하였습니다. 이것은 실행 시간에 변수가 어떤 타입을 갖고 있는지 테스트하여 각 경우의 수 별로 다르게 처리하는 방법입니다. 오른쪽의 코드를 보시면 ir1은 정수형, 실수형 변수가 저장될 수 있는 공용체로 정의되어 있습니다. 아래의 case 문에서는 ir1이 정수일 때와 실수일 때로 나누어서 문구를 처리합니다. 이러한 방식으로 공용체의 타입을 관리하는 것이 적합성 문장입니다.
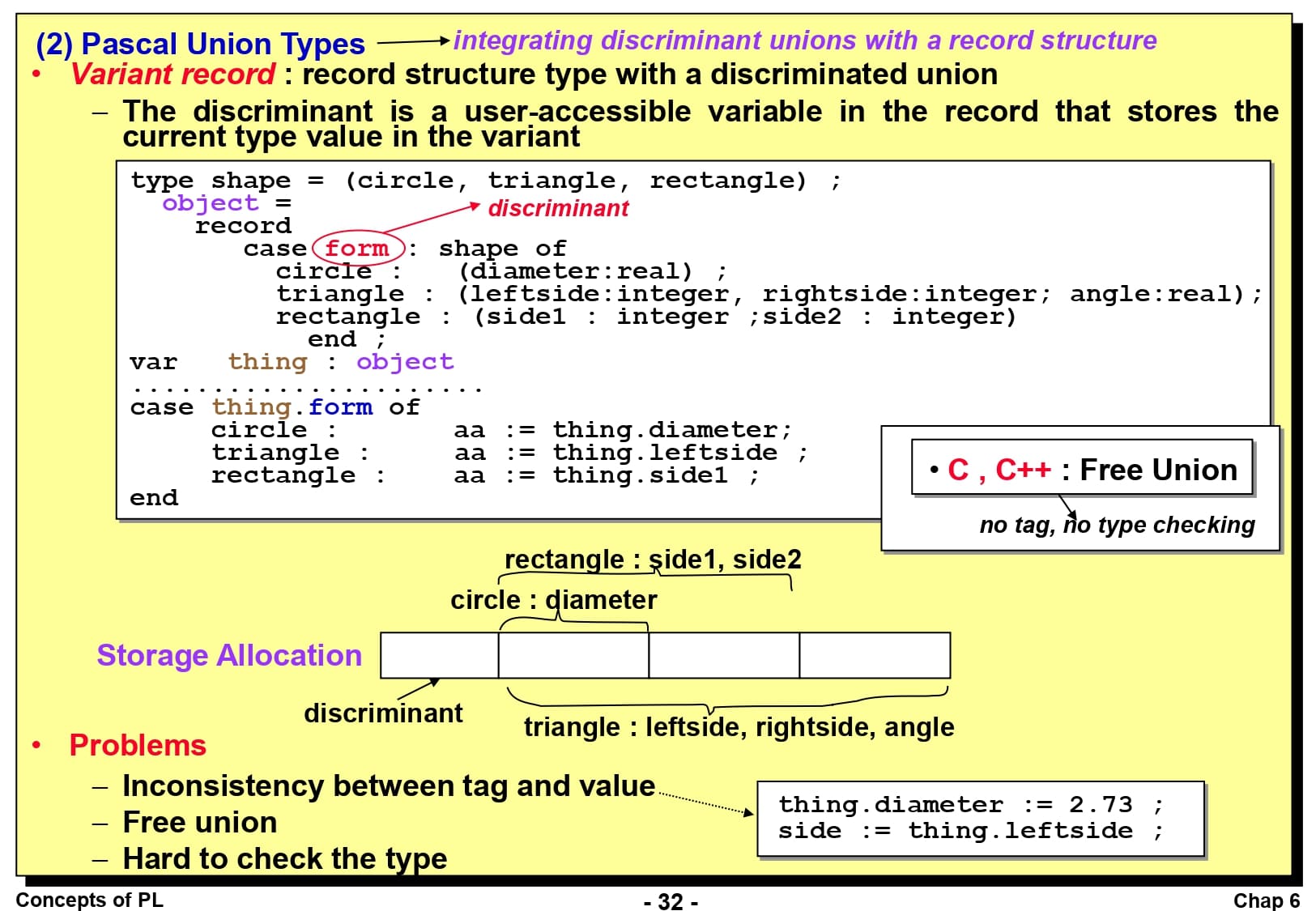
Pascal 언어는 판별 공용체와 레코드 구조를 결합하여 변종 레코드(Variant Record)로 구현하였습니다. 이것은 판별 공용체를 갖고 있는 레코드 구조 타입입니다. Pascal 언어의 판별자는 현재 타입의 값이 저장된 레코드에서 사용자가 접근할 수 있는 변수입니다. 코드 예시를 보면 case 문에 form이라는 이름이 있는데, 이것이 바로 판별자입니다. 레코드에 circle, triangle, rectangle 이 저장될 수 있는데, 이 중 하나를 선택하는 의미입니다.
공용체는 결국 프로그램의 신뢰성을 떨어트리기 때문에 최근에는 지향하지 않는 타입입니다. 기본적으로 메모리를 공유하기 때문에, 공용체 내의 변수의 값을 변경하면 다른 변수의 값도 변형됩니다. 또한 C, C++ 언어와 같이 타입 검사를 하지 않는 자유 공용체를 사용하는 경우 강 타입 언어로부터 멀어지게 됩니다. 타입 검사를 하더라도 그것이 매우 어렵기 때문에 Java나 C#과 같은 최근 언어에서는 공용체를 지원하지 않습니다.

공용체는 포함된 모든 가능한 변수를 같은 주소에 배정하는 것으로 간단하게 구현할 수 있습니다. 당연히 공용체에서 가장 큰 크기를 차지하는 변수만큼 기억공간이 할당됩니다. 예제로 나온 Ada 코드와 같이 공용체가 주어진 경우, 컴파일 시간 내에 이것을 저장하기 위한 배치는 다음과 같을 것입니다.
- 공용체의 시작 주소
- 판별체(=TAG)
- 필드 접근을 위한 오프셋(=상대 주소)
- TRUE - COUNT (INTEGER), FALSE - SUM (CHARACTER)

집합(Set) 타입은 기본 타입의 고유한 값을 정렬되지 않은 모음으로 저장할 수 있는 타입입니다. 집합 타입의 설계 고려 사항은 최대 원소의 개수를 몇 개로 정할 것이냐입니다.
Pascal 언어를 예로 들면, 집합의 최대 원소 수는 구현에 따라 다르지만, 일반적으로 100개 이하입니다. 집합과 그 원소에 대한 연산은 단일 Word 크기에 맞는 비트 문자열로 표현함으로써 가장 효율적으로 구현할 수 있습니다. 예를 들어, {red, blue, green} 집합의 부분 집합인 {red, green}을 2진수 101로 표현하는 것입니다.
Pascal 언어에서 집합 연산은 다음과 같습니다.
- ’:=’ : 집합 타입의 적절한 배정
- ’+’ : 합집합
- ‘*‘ : 교집합
- ’-‘ : 차집합
- ’=’ : 동일한 집합인가 판단
집합을 배열과 비교해보면, 집합의 연산은 배열의 연산보다 효율적이라는 장점이 있습니다.
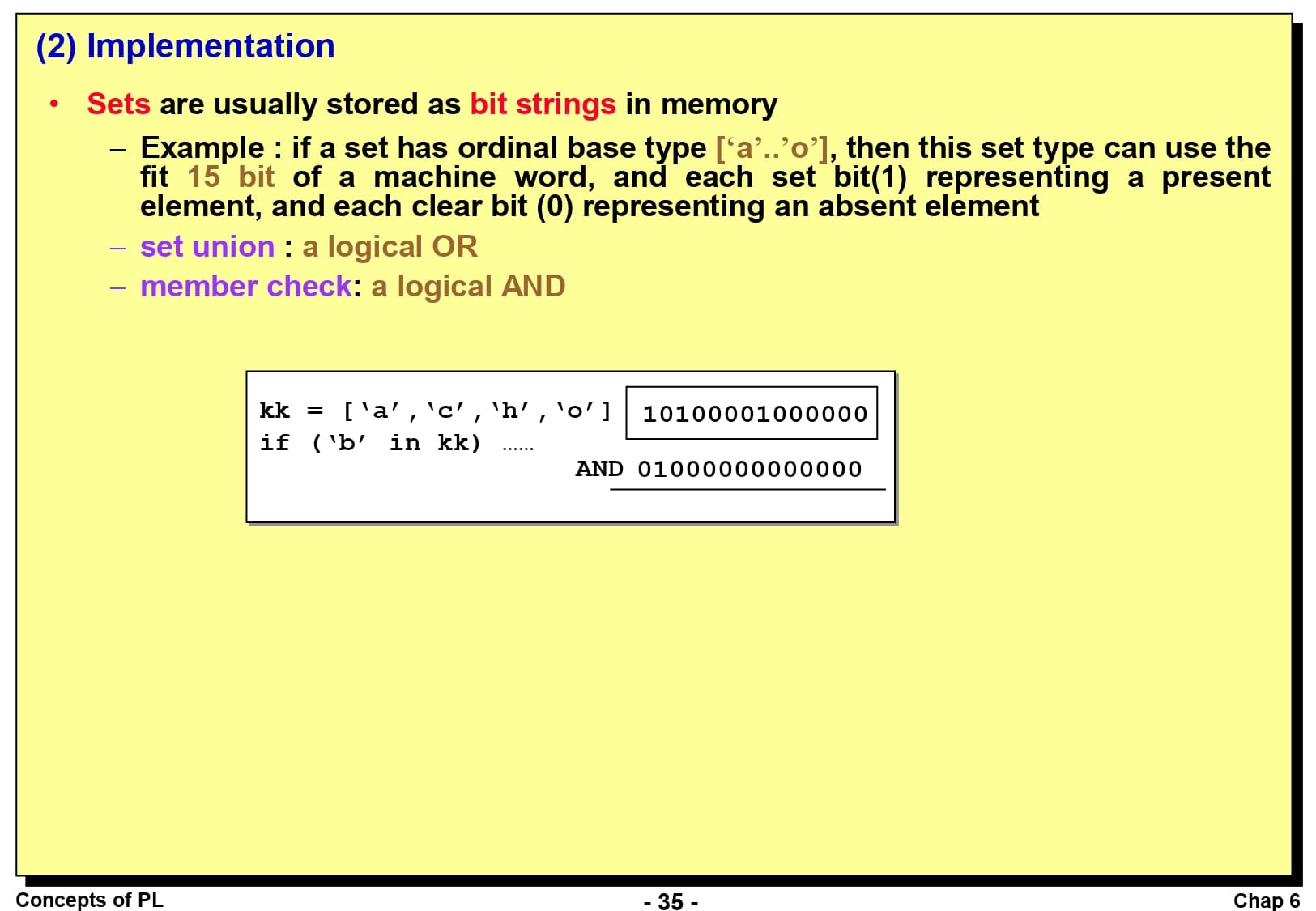
이전 슬라이드에서 말씀드렸듯이 집합은 일반적으로 비트 스트링 형태로 메모리에 저장합니다. 따라서 집합의 연산의 대부분은 간단한 논리 연산으로 해결이 가능하므로 효율적입니다. 예를 들어, 합집합 연산은 논리 OR, 원소의 포함 여부는 논리 AND 연산으로 간단하게 계산할 수 있습니다.

포인터(Pointer) 타입은 변수가 메모리 주소와 특수 값 nil로 구성되는 값들의 범위를 갖습니다. nil은 유효한 주소가 아니며, 포인터가 메모리 셀을 현재 참조할 수 없음을 나타냅니다. 포인터는 간접 주소 지정과 동적 할당 관리 용도로 주로 사용됩니다. 포인터는 일반적으로 타입 연산자(C언어에서의 *)를 사용하여 정의됩니다. 그러나 배열이나 레코드와는 다르게 실제 데이터를 저장하기 위해서 사용하기보다는, 다른 변수를 참조하기 위해서 사용합니다. 이렇게 다른 변수를 참조하기 위해서 사용하는 변수를 참조 타입(Reference Type)이라고도 부릅니다. 반대로 실제 데이터를 저장하는 변수는 값 타입(Value Type)이라고도 부릅니다.
포인터의 설계 고려 사항은 다음과 같습니다.
- 포인터 변수의 영역(Scope)과 수명(Lifetime)은 어떻게 되는가?
- 포인터가 참조하는 동적 변수의 수명은 어떻게 되는가?
- 포인터가 가리킬 수 있는 값의 타입이 제한되는가?
포인터는 기본적으로 배정과 역참조 두 가지 연산을 제공합니다. 배정은 포인터 변수의 값을 다른 주소로 설정하는 것이고, 역참조는 포인터 변수에 바인딩된 메모리 셀이 가리키는 값에 대한 참조를 말합니다. 예를 들어, 예제 코드에서 aa는 포인터 타입으로 정의되어 있습니다. 다음 줄에 aa = &bb는 aa에 bb의 주소를 배정함으로써 포인터 변수 aa가 bb의 메모리 셀을 가리키게 만드는 연산입니다. 그리고 cc = *aa를 통해 변수 cc에 aa가 가리키는 메모리 셀의 값, 즉 55를 저장하게 만드는 역참조 연산입니다.

포인터라는 개념을 처음 도입한 언어는 PL/I이었습니다. 포인터의 개념이 도입되고 나서 프로그램의 유연성이 매우 높아졌지만, 덩달아 여러 가지 유형의 프로그래밍 오류가 초래되었습니다. 따라서 Java와 같은 최근의 언어에서는 포인터를 사용하지 않고 참조 타입으로 대체하였습니다. 여기서는 포인터로 발생할 수 있는 여러 가지 문제를 짚고 넘어가보겠습니다.
먼저 포인터 변수에 대한 타입 검사(Type Checking) 문제입니다. 포인터가 가리킬 수 있는 개체 유형을 도메인 타입이라고 합니다. PL/I의 포인터는 단일 도메인 타입으로 제한되지 않았기 때문에 포인터에 대한 타입 검사가 어려웠습니다. C/C++ 언어에서는 정수 변수를 가리키는 포인터 변수는 정수 포인터, 실수 변수를 가리키는 포인터 변수는 실수 포인터와 같이 가리키는 데이터 타입에 따라 포인터 변수의 타입이 고정되어 있기 때문에 이 문제를 약간이나마 해결했습니다.
다음으로는 허상 포인터(Dangling Pointer) 문제입니다. 이 문제는 C 언어를 배울 때도 다루는 문제입니다. 허상 포인터는 이미 회수된 변수의 주소를 가리키는 포인터를 말합니다. 허상 포인터의 문제는 가리키고 있는 기억장소의 위치에 다른 변수가 할당될 수도 있기 때문에 위험합니다.
마지막으로 분실된 객체(Lost Object) 문제입니다. 이것은 허상 포인터와 반대로, 기억공간에는 여전히 데이터가 저장되어 있지만, 사용자 프로그램에서 더이상 접근할 수 없게된 객체입니다. 이러한 변수를 흔히 쓰레기(Garbage)라고도 부릅니다. 왜냐면 더 이상 원래의 목적대로 사용할 수도 없고, 그렇다고 다른 용도로 재사용할 수도 없기 때문입니다.
위 슬라이드의 마지막 부분에서는 허상 포인터와 분실된 객체가 발생할 수 있는 코드 예시를 나타내고 있습니다. 왼쪽의 예제에서는 포인터 전역 변수인 i가 정의되어 있습니다. 그런데 부프로그램 sub1()에서 지역변수인 j가 새로 선언되어있습니다. sub1()에서 포인터 변수 i가 j를 가리키게 배정되었습니다. 그런데 변수 j는 부프로그램 sub1()의 지역변수이기 때문에, sub1()이 종료되면 수명이 끝납니다. 따라서 sub1()이 호출된 이후 *i는 이미 회수된 변수의 주소를 가리키게 됩니다.
오른쪽 코드에서는 포인터 문자 변수 c가 정의되어 있습니다. 두 번째 줄에서 동적 할당을 통해 c에 새로운 기억공간이 할당됩니다. 그런데 이를 해제하지 않고, 나중에 또 c에 새로운 기억공간을 할당합니다. 이렇게 되면 첫 번째 할당한 기억공간은 프로그램 내에서 더이상 접근할 수 없습니다. 따라서 이 때 분실된 객체 문제가 발생하게 됩니다.

Pascal 언어에서 포인터는 동적으로 할당된 변수에 접근하는데만 사용됩니다. 동적 할당에는 new 명령어를 사용하고, 해제할때는 dispoose 명령어를 사용합니다. dispose 명령어는 허상 포인터 문제가 거의 항상 발생했기 때문에, dispose 명령어가 나오면 이걸 무시하는 경우도 많았습니다. 이것은 허상 포인터 문제를 발생하지 않게 하지만, 프로그램이 더 이상 필요로 하지 않는 힙의 재사용을 불가능하게 만드는 단점이 있습니다. 이것은 초기 Pascal 언어가 산업용 보다는 교육용 언어로 설계되었기 때문에 발생하는 문제입니다.
포인터는 어쩌면 goto문과 비슷한데, goto문이 문장의 제어 범위를 확대시키는 것처럼 포인터는 변수가 참조할 수 있는 메모리 셀의 범위를 확대시킵니다. goto문이 프로그래밍 언어 설계자들에게 비난을 받는 것처럼 포인터도 이와 같은 비난을 받는데요, 오른쪽에 포인터에 대한 악담이 실려있는데, 이 내용이 재미있습니다.
“고급 언어에서 포인터의 도입은 우리가 결코 회복할 수 없는 후퇴였습니다”
마치 우한 폐렴 때 질병관리청에서 그 전으로는 절 때 돌아갈 수 없다고 말한 것과 비슷한 느낌이네요.
C 언어에서 포인터는 어셈블리 언어에서 주소를 사용하는 것처럼 사용할 수 있는데요, 이러한 설계는 허상 포인터나 분실된 객체 문제에 대해 어떤 해결책도 없다는 단점이 있습니다. 그러나 그 대신 C 언어에서는 포인터의 산술 연산이 가능하다는 특징이 있습니다. 기본적으로 ‘*’ 연산은 포인터의 역참조 연산, ‘&’ 연산은 변수의 주소를 생성합니다. 이 외에도 포인터 변수와 일반 변수의 산술 연산이 가능한데, 예를 들어 ptr + index 라는 연산이 있습니다. 이 것은 ptr에 index 값을 단순히 더하는 것이 아니라, 먼저 ptr이 가리키고 있는 메모리 셀의 크기 단위로 index의 값이 조절됩니다. 만약 ptr의 크기가 4인 메모리 셀을 가리키면, index에 먼저 4를 곱한 다음 ptr에 더하는 방식입니다. 이렇게 설정된 목적은 포인터 연산으로 배열을 표현하기 위해서입니다. 예를 들어, 포인터 변수 ptr에 1차원 배열이 할당되었다고 하면, *(ptr + 1)은 ptr[1]과 동일한 의미입니다.

참조 타입(Reference Type)은 포인터와 유사하지만, 포인터가 메모리의 주소를 참조하는 것과 달리 참조 타입은 메모리의 객체나 값을 참조합니다. 따라서 포인터는 주소값을 다루기 때문에 산술 연산이 가능하지만, 참조 타입은 그렇지 않다는 차이가 있습니다.
대표적인 참조 타입은 C++ 언어에서 구현되어 있습니다. C++ 언어의 참조 타입은 항상 암시적으로 역참조되는 상수 포인터로 구현되어 있는데, 상수이기 때문에 정의할 때 어떤 변수에 주소값으로 초기화되어야 합니다. 물론 초기화된 후에는 다른 변수를 참조하도록 설정할 수 없습니다. 일반적으로 C++ 언어에서 참조 타입은 함수에서 호출 함수와 피호출 함수간의 양방향 통신에 사용됩니다. 이러한 예제는 다음을 참고해주시기 바랍니다.
void sub1(int& num){
num = 10;
}
int n = 0;
sub1(n);
이와 같이 함수 매개변수를 참조 타입으로 설정하면, n을 포인터로 넘기지 않아도 n의 값을 0에서 10으로 변경할 수 있습니다.

대부분의 대형 컴퓨터에서 포인터는 2바이트 또는 4바이트 메모리 셀(워드 크기)에 저장된 단일 값으로 저장됩니다. 그런데 포인터를 구현할 때는 포인터를 저장하는 것 자체보다는 포인터로 인해 발생하는 허상 포인터 문제를 고려하는 것이 더 중요합니다.
첫 번째 방법은 비석 접근 방법(Tombstone Approach)입니다. 이것은 모든 동적 변수에 비석이라는 특수한 셀을 포함시키는 것입니다. 실제 사용하는 포인터 변수는 이 비석을 가리키게 하고, 비석이 동적 변수를 가리키게 만드는 구조입니다. 만약 동적 변수가 기억장소에서 해제된다면, 비석은 그대로 남지만 nil을 가리키도록 설정됩니다. 즉, 비석을 통해 포인터가 회수된 기억공간을 계속 가리키는 것을 방지하는 방법입니다.
아이디어만 들어도 이 방법의 문제점이 자연스럽게 떠오릅니다. 먼저, 동적 변수가 해제될 때도 비석은 해제되지 않기 때문에 그 만큼의 기억공간이 낭비됩니다. 게다가, 포인터 변수가 기억공간을 직접 가리키지 않고 비석을 통해 간접적으로 가리키기 때문에 그만큼의 접근 시간이 추가로 소모됩니다. 일반적으로는 이 정도의 시간적/공간적 비용을 감당하면서까지 신뢰성을 확보할 필요가 없기 때문에, 이 방법을 사용하는 언어는 거의 없습니다. 버전 9 이하의 매킨토시나 C++ 언어의 일부 라이브러리(std::weak_ptr)만 이 방법을 사용했습니다.

허상 포인터를 해결하는 두 번째 아이디어는 잠금과 키 접근 방법(Locks-and-key Approach)입니다. 이 방법은 동적 변수를 (변수, 잠금값)의 순서쌍으로 나타내고, 동적 변수를 가리키는 포인터는 (키, 주소)의 순서쌍으로 나타냅니다. 동적 변수가 할당되면 잠금값이 생성되어 포인터 변수의 키 값과 동적 변수의 잠금값에 이 값이 저장됩니다. 포인터가 역참조될 때는 포인터의 키 값과 동적 변수의 잠금값과 비교함으로써 그 접금이 일치하는지, 아닌지 확인합니다. 만약 포인터가 복사된다면 잠금값도 같이 복사되어야 하고, 해제될 때는 잠금값도 해제되어야 합니다.
사실 이러한 방법들 보다는 그냥 프로그래머 직접 매번 동적 변수를 해제해주는 것이 좋습니다. 프로그램 내에서 모든 동적 변수가 명시적으로 해제된다면 허상 포인터 문제는 발생하지 않기 때문입니다.
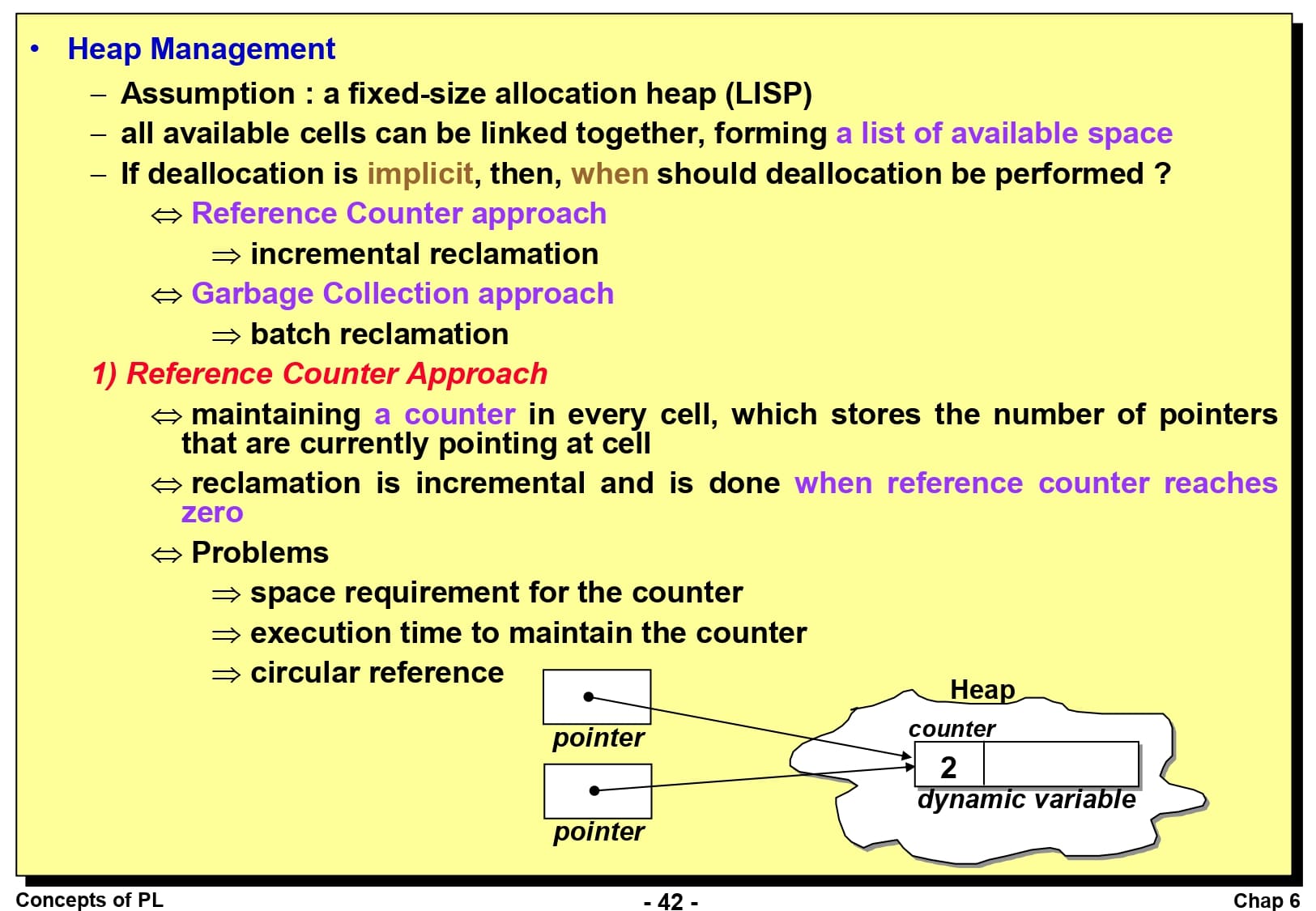
마지막으로 힙 메모리 관리에 대해 알아보도록 하겠습니다. 힙 메모리 관리는 매우 복잡한 실행 시간 프로세스로, 여기서는 모든 힙이 동일한 크기로 할당/회수되는 시나리오와 가변 크기로 할당/회수되는 시나리오, 두 가지 상황으로 나누어 고려해보겠습니다.
먼저 동일한 크기에 대해 회수에 대해 먼저 논의하자면, 기억공간 회수를 통해 사용가능한 셀을 묶어 가용 공간 리스트를 만들 수 있습니다. 할당은 필요할 때 이 리스트로부터 요구된 셀의 개수를 가져오는 것입니다. 할당보다 회수가 더 어려운 문제인데, 동적 변수는 2개 이상의 포인터로 가리켜질 수 있으므로 그 변수가 언제 프로그램에서 더 이상 사용되지 않는지 판단하는 것이 어렵기 때문입니다. 예를 들어, 동적 변수를 가리키던 포인터가 없어진다고 해서 그 동적 변수가 쓰이지 않는다고 보장할 수 없습니다. 다른 포인터가 그 동적 변수를 가리키고 있을 수도 있기 때문입니다.
LISP 언어에서는 회수하는 방법에 따라 두 가지 방법으로 나눌 수 있는데, 순차적으로 회수하는 참조 계수기 접근 방법(Reference Counter)과 쓰레기 수집 접근 방법(Grabage Collection Approach)이 있습니다.
먼저 참조 계수기 접근 방법부터 알아보겠습니다. 참조 계수기 방법은 접근할 수 없는 메모리 셀이 생성될 때마다 회수를 수거하는 방법입니다. 이것을 구현하기 위해, 항상 모든 메모리 셀에 대해 현재 자신을 가리키고 있는 포인터의 갯수를 저장하는 계수기를 사용합니다. 만약 어떤 셀의 계수기 값이 0이 된다면 이 메모리 셀을 가리키는 포인터가 없다는 뜻이므로 더 이상 쓰지 않는 메모리 셀로 판단하여 회수합니다.
참조 계수기 방법에는 세 가지 문제점이 존재합니다. 첫째는 기억공간의 셀 크기가 작다면, 그만큼 계수기가 차지는 공간이 부담이 될 수 있습니다. 둘째로 계수기의 값을 조절하기 위한 시간적 부담도 존재합니다. 특히나 LISP은 거의 모든 명령문마다 포인터의 값이 변경되므로, 프로그램 실행 시간에서 계수기가 차지하는 실행 시간이 매우 부담스럽습니다. 마지막으로 셀이 순환적으로 참조되어 있는 경우입니다. 이러한 순환 리스트에 속하는 셀은 적어도 1의 계수기 값을 갖게 되므로 영원히 회수되지 않는다는 문제점이 있습니다.
다만 참조 계수기 방법에 단점만 있는 것은 아닙니다. 참조 계수기 방법은 순차적으로 동작하는 방식이기 때문에 프로그램의 수행과 번갈아가며 발생합니다. 따라서 전체적으로 프로그램 실행에 지연을 초래하지 않는다는 장점이 있습니다.

다음으로 쓰레기 수집 접근 방법에 대해 알아보겠습니다. 실행 시간에서 저장공간이 요구될 때 기억공간의 메모리 셀을 할당하고, 필요할 때 포인터와 셀의 연결을 끊습니다. 이 때는 일단 기억공간 회수에 신경쓰지 않고, 사용가능한 모든 셀이 할당될 때까지 이루어집니다. 이 과정에서 발생하는 쓰레기를 수집하기 위해, 쓰레기 수집 프로세스가 시작됩니다. 쓰레기 수집을 위해, 모든 셀은 수집 과정에서 사용되는 여분의 비트나 필드를 갖습니다. 쓰레기 수집을 위한 간단한 알고리즘은 다음과 같이 나타낼 수 있습니다.
- 힙의 모든 셀은 쓰레기인지 나타내는 표시가 설정됩니다.
- 프로그램의 모든 포인터는 힙으로 추적되고, 도달 가능한 셀은 쓰레기가 아닌 것으로 표시합니다.
- 쓰레기가 아닌 것으로 표시되지 않은 힙의 모든 셀을 회수합니다.
이러한 쓰레기 수집 접근 방법의 가장 큰 단점은 가장 필요할 때 가장 최악으로 동작한다는 것입니다. 이게 무슨 말이냐 하면, 쓰레기 수집은 힙의 기억공간을 대부분 사용되었을 때만 사용됩니다. 그런데 이 방법은 대부분의 셀을 추적해서 현재 사용중인지 확인해야하기 때문에, 상당한 많은 시간이 소요됩니다.

만약 메모리 셀이 가변 크기인 경우에는 문제가 더 복잡해집니다. 우선 가변 크기 셀에서는 동일한 크기의 셀에서 발생하는 모든 어려움을 기본적으로 갖고 있고, 다음과 같은 추가적인 문제가 더 발생합니다.
- 힙에 있는 모든 셀이 쓰레기라는 것을 나타내기 위한 표시의 초기 설정이 어렵습니다. 왜냐하면 각각의 셀이 다른 크기이기 때문에, 셀의 영역이 어디서부터 어디까지인지 스캔하는 것이 어렵기 때문입니다. 이에 대한 대책으로는 셀의 첫 번째 필드로 그 셀의 크기를 표시하는 것입니다.
- 만약 포인터를 전혀 포함하지 않는 셀이라면 어떻게 표시를 할 것인지도 문제가 됩니다. 물론 이것은 내부 포인터를 추가하면 해결되는 문제이지만, 이것으로 인해 추가적인 공간적 부담과 시간적 부담이 발생합니다.
- 사용가능한 기억공간의 리스트를 관리하는 것도 문제입니다. 회수된 기억공간의 크기는 클 수도 있지만 작을 수도 있습니다. 만약 회수된 기억공간 중 하나가 필요한 기억공간의 크기에 맞지 않다면 충분한 크기를 가진 다른 기억공간을 찾아야합니다. 이에 대한 해결책으로는 기억공간의 크기가 작은 경우 인접한 블록을 합병하는 것이지만, 이 과정에서도 추가적인 시간적 부담이 발생합니다.
이러한 문제점 중, 1번과 2번의 문제는 참조 계수기 방법을 사용하면 어느 정도 해결이 가능합니다. 그러나 3번 문제는 참조 계수기로도 해결할 수 없습니다. 나쁜 소식은 대부분의 프로그래밍 언어에서는 이러한 가변 크기 셀의 관리가 반드시 필요하다는 것입니다.
6장의 내용은 여기까지입니다. 읽어주셔서 감사합니다!
Leave a comment