
Names, Bindings, Type Checking, and Scopes

처음 소개드린대로 3장과 4장은 컴파일러 과목과 중복된 내용이기 때문에 생략하고, 바로 5장으로 넘어갑니다. 5장은 변수와 관련된 개념들을 하나씩 소개합니다. 특히 제목대로 변수의 이름, 바인딩, 타입 검사, 유효 영역 등을 중점으로 짚도록 하겠습니다. 이번 장을 한 문장으로 요약하면 다음과 같습니다.
“변수는 속성이나 속성의 모음으로 특징지어질 수 있으며, 그 중 가장 중요한 것은 타입입니다. 프로그래밍 언어의 데이터 타입을 설계하려면 범위, 수명, 타입 검사 및 초기화 등 다양한 문제를 고려해야 합니다.”
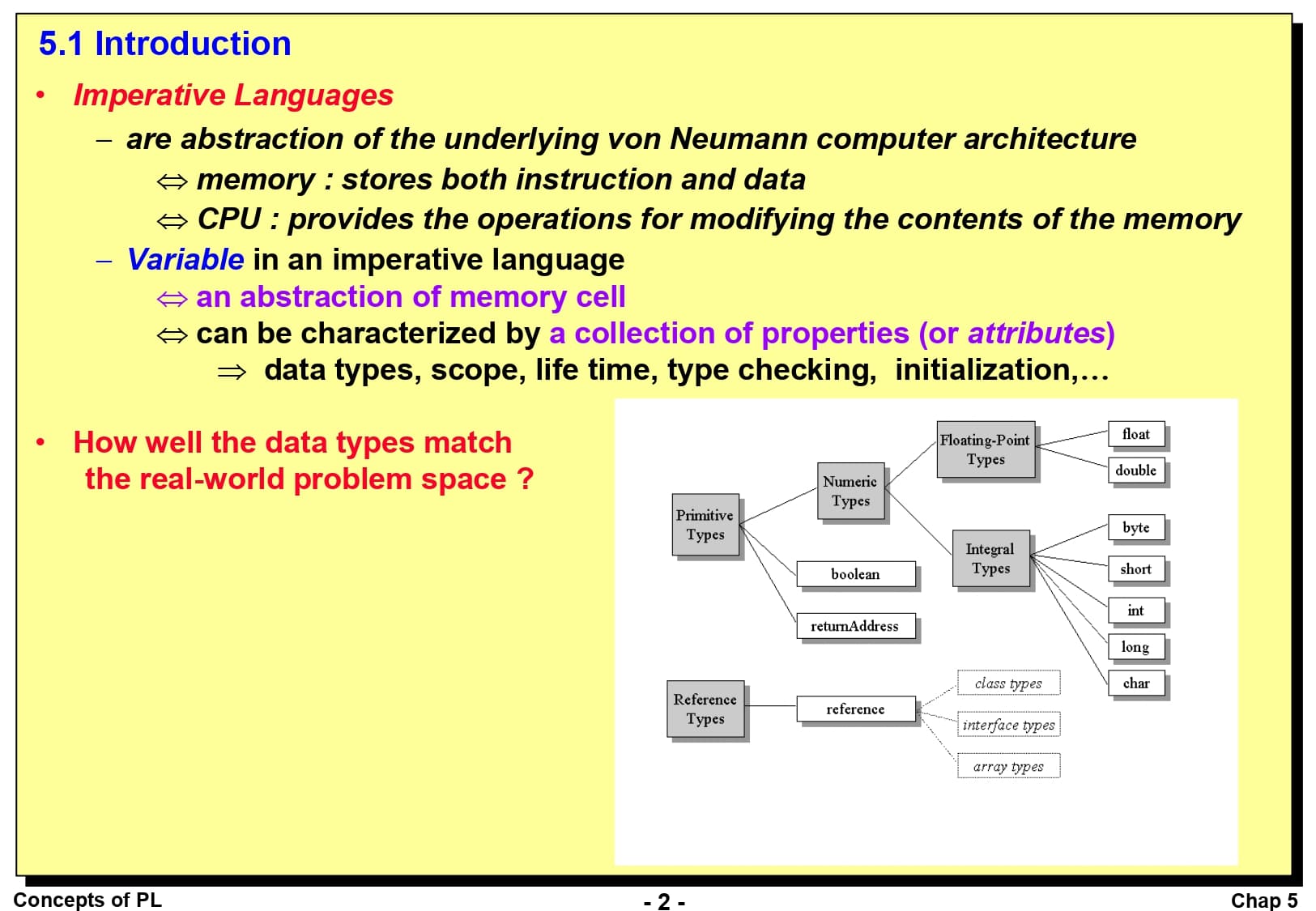
명령형 언어는 폰 노이만 구조를 기반으로 한 추상화입니다. 이 컴퓨터 구조의 가장 큰 특징은 명령어와 데이터를 저장하는 메모리와, 그 메모리의 내용을 수정하기 위한 연산을 제공하는 CPU로 구성되어 있다는 것입니다. 명령형 언어의 변수라는 것은 결국 메모리 셀에 대한 추상화입니다. 변수는 데이터 타입, 유효 영역, 수명, 타입 검사 등과 같은 속성(Attribute)들의 모음으로 특징지어질 수 있습니다.

먼저 이름(Name)은 프로그램에서 변수, 레이블, 부프로그램 및 매개변수와 같은 요소들을 식별하는데 사용되는 문자열입니다. 이름을 설계할 때는 다음과 같은 것들을 고려해야 합니다.
- 이름의 최대 길이는 무엇인가?
- 이름에 밑줄과 같은 연결 문자를 사용할 수 있는가?
- 이름이 대소문자를 구분하는가?
- 특수어가 예약어인가, 키워드인가?
이것들에 대해 하나씩 고려해보도록 하겠습니다. 먼저 이름의 길이는 언어가 발전되면서 점점 늘어났습니다. 초기 프로그래밍 언어에서는 오로지 단 한 문자만 허용되었으나, FORTRAN I은 6글자, COBOL은 30문자, C와 C++, Java와 같은 경우는 제한 없는 길이가 가능해졌습니다.
또한 대부분 프로그래밍 언어에서 밑줄 문자를 띄어쓰기와 비슷한 용도로 사용합니다. 이러한 문화는 1970년 ~ 1980년대에 널리 사용되었지만, 최근에는 점점 배제하는 경향을 보입니다. C 언어 이후 등장한 언어들에서는 Camel Notation이라는 표기법이 정립되어, 대소문자를 통해 단어를 구분했습니다. 예를 들어서 myStack과 같이 말입니다. 그러나 이러한 밑줄 문자나 대소문자 혼용 사용은 언어 설계의 고려 사항이 아니라 프로그래밍에서의 고려 사항입니다.
그렇다면 언어에서 대소문자를 구별하는 것이 좋은 선택일까요? 예를 들어 C++에서는 대소문자가 완벽하게 다른 글자로 구분되므로 ROSE, rose, Rose 이 3개의 이름은 모두 다른 이름으로 취급됩니다. 이것은 가독성 측면에서 굉장히 좋지 않다고 볼 수 있습니다. 왜냐하면 이 3개의 이름은 서로 유사하게 보이지만, 실제로는 아무런 관련이 없기 때문입니다. 물론 이것은 프로그래밍에서의 문제이기 때문에 대부분의 사람들은 대소문자가 구별되는 것을 싫어하지 않지만, 사전 정의된 이름들에서 대소문자가 구별되는 경우 문제가 생길 수 있습니다. 예를 들어, Java에서 문자열을 정수 값으로 변환하는 메소드는 parseInt인데, ParseInt나 parseint로 입력하면 인식하지 못합니다. 이것은 대소문자를 구분하는 것이 작성력 측면에서도 좋지 않음을 알 수 있습니다.

특수어(Special Words)는 수행될 행동들을 명칭화하여 프로그램의 가독성을 높이는데 사용됩니다. 대부분의 프로그래밍 언어에서 특수어는 키워드(Keyword), 또는 예약어(Reserved word)로 분류되어 있습니다.
-
키워드 : 프로그래밍 언어 내의 특수어를 재정의할 수 있는 경우 키워드라고 부릅니다. 현재 사용되고 있는 언어 중에서 특수어가 키워드인 언어는 Fortran 뿐입니다. Fortran의 특수어 중 하나인 REAL은 REAL APPLE로 선언하는 경우에는 APPLE이 실수형 변수로 정의가 되지만, REAL = 3.4로 선언할 경우 REAL 이란 변수에 3.4를 대입하는 식이 됩니다.
-
예약어 : 프로그래밍 언어 내의 특수어를 재정의할 수 없는 경우 예약어라고 부릅니다. 프로그래밍 언어 설계 관점에서 보면, 예약어가 키워드보다 낫다는 것이 일반적인 의견입니다. 그러나 예약어에서도 문제가 하나 있는데, 언어가 갖고있는 예약어가 너무 많을 경우 프로그래머가 불편함을 느낄 수 있다는 것입니다. 특히 COBOL 언어는 300여개의 예약어를 가지고 있는데, 그 중에는 일반적으로 많이 사용하는 이름인 COUNT, LENGTH와 같은 것들도 포함하고 있습니다. 이 경우 프로그래머가 변수 이름을 짓는데 상당한 애로사항이 생길 수 있습니다.

변수(Variable)는 1페이지에서도 설명드렸듯이 메모리 셀에 대한 추상화입니다. 변수는 이름(Name), 주소(Address), 타입(Type), 값(Value), 수명(Lifetime), 유효 범위(Scope) 6개의 튜플로 구성되어 있습니다.
-
이름 : 변수의 이름은 프로그램에서 가장 일반적으로 볼 수 있는 이름입니다. 변수의 이름은 식별자(Identifiers)라고도 불립니다.
-
주소 : 변수의 주소는 그 변수와 연관된 실제 메모리의 주소입니다. 많은 언어들에서는 동일한 변수가 프로그램의 위치에 따라 다른 주소와 연관되는 것이 가능합니다. C 언어와 비슷한 언어에서는 지역 변수(Local Variable)라는 개념을 생각하시면 됩니다. 또한 같은 주소를 가리키는 여러 개의 변수를 가질 수도 있습니다. 이것을 별칭(Alias)이라고 하는데, 이것은 가독성을 떨어트리므로 권장되지 않습니다. 예를 들어, total이 sum의 별칭이라면, total 값을 변경시켰을 때 sum 값도 변경되고, 그 반대도 가능해집니다. 따라서 프로그램을 읽는 프로그래머는 total과 sum이 같은 공간을 가리키는 것을 반드시 기억해둬야 하는 불편함이 있습니다. 결국 프로그램 내의 별칭이 많을 수록 검증이 더욱 어려워집니다. C 언어의 포인터가 대표적인 별칭의 예시입니다. 또한 부프로그램의 매개변수를 통해서 생성될 수도 있는데, 이것은 9장에서 부프로그램에 대해서 다룰 때 더 자세하게 논의하겠습니다.

-
타입 : 변수의 타입은 그 변수가 저장할 수 있는 값들의 범위와 정의될 수 있는 연산들의 집합을 결정합니다. 예를 들어, Fortran에서의 Integer 타입은 -32,768 ~ 32,767 사이의 값을 가질 수 있으며, 사칙연산이 가능합니다.
-
값 : 변수의 값은 그 변수에 저장된 메모리 셀의 내용입니다. 변수는 등호(=)를 기준으로 왼쪽에 있을 때는 l-value, 오른쪽에 있을 때는 r-value로 부릅니다. l-value는 변수의 주소, r-value는 변수의 값을 나타냅니다.

바인딩(Binding)은 연산과 기호 같은 하나의 속성과 하나의 개체 간의 연관성입니다. 바인딩이 일어나는 시기를 바인딩 시간(Binding Time)이라고 부릅니다. 바인딩 시간은 다음과 같이 다양한 경우로 분류할 수 있습니다.
- 언어 설계 시간 : ‘*’ 기호는 일반적으로 언어 설계 시 곱셈 연산으로 바인딩됩니다.
- 언어 구현 시간 : Integer와 같은 데이터 타입이 어떤 범위의 값을 가질지는 언어 구현 시간에 바인딩됩니다.
- 컴파일 시간 : Pascal로 구현된 프로그램에서 변수가 어떤 데이터 타입을 가질지는 컴파일 시간에 바인딩됩니다.
- 링크 시간 : 라이브러리 부프로그램에 대한 호출은 링크 시간에 부프로그램 코드에 바인딩됩니다.
- 로드 시간 : 프로그램이 메모리에 로드될 때 변수가 메모리 셀에 바인딩됩니다.
- 실행 시간 : 프로시저의 변수는 프로시저가 실제로 호출될 때 메모리 셀에 바인딩됩니다.
예를 들어 오른쪽 구석에 있는 간단한 프로그램을 확인해봅시다. 가장 첫 줄에서는 int count;를 통해 count 변수를 int형 변수로 선언하였습니다. 이것은 컴파일 시간에 바인딩됩니다. count = count * 5;에서 count가 가질 수 있는 값은 언어 구현 시간에 바인딩됩니다. 또한 ‘*’ 연산이 어떤 의미를 가질지는 피연산자의 타입이 결정되었을 때 바인딩되므로 컴파일 시간에 바인딩됩니다. 5라는 숫자 표현은 컴파일 설계 시간에 바인딩되며, count의 최종 값은 이 배정문의 실행 시간에 바인딩됩니다. sub1(count);에서 count 변수는 이 부프로그램의 매개변수로 들어있습니다. 그러나 count의 값은 이전 구문에서 실행 시간에 바인딩되었으므로 이 때는 실행 시간에 바인딩됩니다. 그러다 sub1(int aa)에서 변수 aa는 매개변수로 처음 선언되는 변수입니다. 따라서 변수 aa는 count와는 다르게 로드 시간에 바인딩됩니다.

만약 바인딩이 실행 시간 이전에 일어나고 프로그램 실행 전체에 걸쳐서 변하지 않는다면 정적 바인딩(Static Binding)이라고 부릅니다. 반대로 프로그램 실행 과정에서 변경될 수 있다면 동적 바인딩(Dynamic Binding)이라고 부릅니다. 하드웨어에서 발생하는 동적 바인딩의 대표적인 예시는 가상 메모리입니다. 가상 메모리는 상황에 따라 실제 물리적 메모리에 다르게 바인딩될 수 있지만, 여기서 이러한 종류의 동적 바인딩까지는 고려하지 않도록 하겠습니다.
먼저 타입 바인딩의 경우를 살펴보겠습니다. 변수는 프로그램 내에서 참조되기 전까지 어떤 데이터 타입인지 바인딩되어야만 합니다. 변수에서 타입은 두 가지 선언 방법이 있습니다. 변수 이름과 특정 타입을 직접 명세함으로써 타입을 바인딩하는 명시적 선언(Explicit Declaration)이 있습니다. 1960년 이후 설계된 대부분의 프로그래밍 언어들은 명시적 선언 방법을 채택하고 있습니다. 반대로 직접 선언하지 않고 규칙에 의해 변수에 타입을 바인딩하는 것을 묵시적 선언(Implicit Declaration)이라고 합니다. 대표적으로 Fortran, Basic, PL/I가 이 방법을 사용합니다. 공통점은 이 두 방법 모두 정적 바인딩으로 분류된다는 것입니다.

동적 타입 바인딩에서는 변수의 타입이 선언문이나 이름 그 자체로 정해지지 않습니다. 대신 변수에 어떤 값이 할당되는 순간 그 변수에 타입이 바인딩됩니다. 오른쪽 그림과 같이 변수 count는 1을 넣었을 때는 정수형, 3.0을 넣었을 때는 실수형, [1, 2, 3]을 넣었을 때는 배열로 바인딩됩니다. 대표적으로 Python이 이러한 동적 타입 바인딩 방식을 사용하고 있습니다.
동적 타입 바인딩의 장점은 프로그래밍 시의 유연성을 제공한다는 것입니다. 특히 Generic Program을 작성할 때 빛을 발휘할 수 있습니다. 그러나 프로그램의 신뢰성을 낮추는 단점이 있습니다. 동적 타입 바인딩을 가진 언어는 컴파일 시간에 오류를 탐지하기 더 어렵기 때문입니다. 따라서 타입 검사를 실행 시간에 수행해야만 하는데, 그로 인해 추가적인 비용이 드는 것이 문제입니다. 그렇기 때문에 동적 타입 바인딩을 갖는 언어는 컴파일러보다는 인터프리터를 사용해서 구현하는 경우가 많습니다. 왜냐면 어차피 인터프리터는 컴파일러에 비해 10배 이상 느리기 때문에 동적 타입 바인딩에서 발생하는 검사 시간이 인터프리터의 번역 시간에 묻히기 때문입니다.
묵시적 선언에서 타입 선언을 하는 것을 타입 추론(Type Inference)라고 부르기도 합니다. ML이라는 언어에서 부프로그램은 fun circum(r) = 3.14 * r * r;과 같이 선언할 수 있습니다. ML 언어는 함수의 내부 구조를 통해 함수의 결과값이 어떤 타입인지 확인하는데, 이 경우 3.14라는 실수 값이 함수의 결과값에 영향을 주기 때문에 결과 값은 실수 타입으로 자동으로 추론됩니다.
Generic Programming은 데이터 타입에 의존하지 않고, 하나의 변수가 여러 다른 데이터 타입을 가질 수 있게 만드는 프로그래밍 스타일입니다. 이것은 코드의 재사용성을 크게 높일 수 있으며, 이러한 접근 방식은 1973년 ML이라는 언어에서 처음 제안되었습니다.

변수의 수명(Lifetime)은 변수가 특정 메모리에 바인딩되어 있는 기간으로 정의됩니다. 즉, 변수가 특정 메모리 공간에 바인딩 될 때 시작되며 그 공간에서 해제될 때 종료됩니다.
-
정적 변수(Static Variable)는 프로그램이 실행되기 전에 메모리 공간에 바인딩되고, 프로그램 실행이 종료되면 해제됩니다. 대표적인 정적 변수는 전역 변수(Global Variable)가 있고, 부프로그램에서 기록에 민감한 변수의 경우에도 정적 변수로 선언됩니다. 정적 변수는 할당이나 해제를 위한 시간이 필요하지 않기 때문에 효율성을 높일 수 있다는 장점이 있지만, 유연성을 감소시킨다는 문제점이 있습니다. 특히 정적 변수만을 갖는 언어로는 재귀적 부프로그램을 만들 수 없습니다.
-
스택 동적 변수(Stack Dynamic Variable)는 선언문에 의해 지시될 때 기억공간 바인딩이 생성되지만, 타입은 정적으로 바인딩되는 변수를 말합니다. 따라서 바인딩 자체는 실행 시간에 일어나게 됩니다. 대표적인 스택 동적 변수의 예시는 프로시저에서의 지역 변수가 있습니다. 예를 들어, C나 Java와 같은 언어에서 함수에 선언된 변수는 그 함수가 호출될 때 기억공간에 바인딩됩니다.
스택 동적 변수의 장점은 재귀적 부프로그램을 가능하게 만들고, 서로 다른 프로시저에서 동일한 메모리 공간을 차지하게 만들 수 있습니다. 단점으로는 실행 시간에서 지역 변수의 메모리 할당 및 할당 해제를 위한 추가적인 비용이 필요하다는 것입니다. 또한 스택 동적 변수는 간접적인 주소지정을 필요로 하기 때문에 접근 속도가 더 느리다는 단점도 있습니다.

스택 동적 변수의 예로 위와 같은 하나의 프로그램을 보겠습니다. 먼저 변수 a2와 변수 p는 sub()라는 부프로그램 안에서 선언되었기 때문에 스택 동적 변수입니다. 따라서 이 변수들은 sub() 종료시 메모리에서 자동으로 회수됩니다. 변수 a3은 부프로그램 안에서 선언되었지만, static으로 선언되었기 때문에 정적 변수이므로 sub()가 종료되더라도 자동으로 회수되지 않습니다. 변수 a3은 프로그램이 종료될 때 회수됩니다. 또한 변수 p는 a2와 다르게 포인터로 선언되어 있습니다. 그렇기 때문에 이것도 일단 실행 시간에서 기억공간에 할당되고 회수되지만, a2와는 다르게 힙(Heap)에 저장된다는 차이점이 있습니다.
묵시적 힙 동적 변수(Implicit Heap Dynamic Variable)은 값이 배정될 때 힙 기억장소에 바인딩 되는 변수입니다. 다음과 같은 APL 언어의 LIST 변수는 이전에 어떤 용도로 사용되었는지에 상관 없이 list 형으로 값이 배정된다면 list 형으로 기억장소에 바인딩되고, 마찬가지로 정수형으로 배정된다면 기억장소에 정수형으로 바인딩됩니다. 장점으로는 높은 유연성을 갖는다는 것이지만, 타입 바인딩 때와 마찬가지로 실행 시간에서의 부담이 늘어나고 컴파일 시간에 오류를 탐지하는 것이 어려워진다는 것입니다.

명시적 힙 동적 변수(Explicit Heap Dynamic Variable)은 프로그래머가 명시적으로 공간을 할당하고 회수되는 변수입니다. 명시적 힙 동적 변수는 포인터나 참조 변수에 의해서만 참조될 수 있으며 실행 시간에서 메모리 공간 바인딩과 해제가 모두 일어납니다. 명시적 힙 동적 변수의 타입은 컴파일 시간에 바운딩되지만, 기억장소에 바인딩 되는 것은 실행 시간입니다.
명시적 힙 동적 변수를 이해하기 위해, 가운데에 있는 C++ 코드 예제를 보겠습니다. 이 예제에서 명시적 힙 동적 변수는 new int를 통해서 생성됩니다. 그리고 이 변수는 포인터인 intnode를 통해 참조될 수 있습니다. 그리고 delete 명령어를 통해 기억공간에서 해제됩니다. C++는 쓰레기 수집(Garbage collection)과 같은 묵시적 기억공간 회수 방법을 사용하지 않기 때문에 명시적 연산자인 delete가 반드시 필요합니다. 반대로 Java는 명시적 힙-동적 변수를 사용하지만 쓰레기 수집을 지원하기 때문에 명시적으로 회수할 필요가 없습니다.
명시적 힙 동적 변수의 장점은 실행 시간 도중 크기가 커지거나 줄어들 수 있는 연결 리스트나 트리와 같은 동적인 구조체를 구현하는데 유용합니다. 그러나 참조 변수를 올바르게 사용하기가 어렵고, 참조 비용, 기억공간 관리를 구현하는게 어렵다는 단점이 있습니다.

다음으로 확인해볼 사항은 타입 검사(Type Checking)입니다. 사실 10판 이후로 이 부분은 6장으로 넘어갔지만, 강의자료에서는 그것이 반영되지 않아 여전히 5장의 내용으로 나와있네요. 어쨌든 강의자료를 기반으로 설명드리는 것이기 때문에 타입 검사는 여기에서 짚고 넘어가겠습니다.
타입 검사는 연산자와 피연산자가 호환 가능한 타입(Compatible Type)인지 확인하는 검사입니다. 호환 가능한 타입이란 연산자에 대해 적합하거나, 컴파일러에 의해 적합한 타입으로 변환되는 것이 허용되는 타입입니다. 이렇게 컴파일러에 의해 자동으로 변환되는 것을 타입 강제 변환(Coercion)이라고 합니다.
타입 검사에는 정적 타입 검사(Static Type Checking)와 동적 타입 검사(Dynamic Type Checking) 2가지 종류가 있습니다. 정적 타입 검사는 모든 변수의 타입 바인딩이 정적인 경우 수행되는 타입 검사이며, 동적 타입 검사는 실행 시간에 검사하는 타입 검사입니다. 예를 들어, JavaScript나 PHP 같은 언어는 동적 타입 바인딩으로 인해 동적 타입 검사만을 지원합니다.
타입 검사도 컴파일 시간에 수행하는 것이 실행 시간에 수행하는 것보다 효율적입니다. 정적 검사는 컴파일 시간에 타입 검사를 실행함으로써 효율적인 검사가 가능하지만, 프로그래밍의 유연성이 낮다는 단점이 있습니다. 그러나 최근에는 이러한 유연성이 오히려 가독성에 악영향을 끼친다고 인식되고 있기 때문에 큰 문제는 아닙니다. 동적 타입 검사는 반대로 프로그래밍의 유연성이 증가하지만, 그만큼 타입 검사가 어려워진다는 문제가 있습니다. 특히, 실행 중에 서로 다른 유형의 값을 서로 다른 시점에 저장할 수 있도록 허용되는 경우 타입 검사가 매우 복잡해집니다. 오른쪽의 Pascal 언어의 예시와 마찬가지로, C언어의 공용체(Union)가 바로 이러한 경우입니다.

1970년대 중요하게 여겨졌던 언어 설계의 아이디어 중 하나는 강 타입(Strong Typing)입니다. 프로그램 내에 모든 타입이 정적으로 바인딩되어 타입 오류가 항상 탐지되는 언어를 강 타입 언어(Strongly Typed Language)라고 부릅니다. 이것은 꼭 하나의 변수가 하나의 타입만 가져야할 것처럼 보이지만, 실제로 그렇지는 않습니다. 두 개 이상의 타입이 저장되는 변수의 경우에는 실행 시간에 탐지하는 것도 허용됩니다.
대표적으로 Ada 언어가 강 타입 언어에 가장 가까운 언어이고, C 언어와 C++ 언어는 강 타입 언어가 아닌 대표적인 언어입니다. Java는 C++의 파생 언어이지만 강 타입 언어에 매우 가깝습니다. Fortran 77 언어는 실제 매개변수와 형식 매개변수 간의 관계가 타입 검사되지 않기 때문에 강 타입 언어가 아니며, Pascal 언어는 강 타입 언어에 가깝지만 레코드 설계 측면에서는 강 타입 언어가 아닙니다.

다음으로는 타입 동등(Type Equivalence)에 대해 살펴보겠습니다. 먼저 서로 다른 두 변수가 서로 가지고 있는 값을 다른 변수에게 할당할 수 있는 경우에는 타입 호환(Type Compatible)이 가능하다고 정의됩니다. 스칼라 타입 변수의 경우에는 대부분 단순하고 엄격한 조건을 가지고 있지만, 배열이나 레코드와 같은 구조화된 타입에서는 규칙이 더 복잡해집니다.
이러한 강제 변환(Coercion) 없이, 어떤 타입의 피연산자가 다른 타입의 피연산자로 대체될 수 있을 때 타입 동등이라고 부릅니다. 타입 동등은 타입 호환성보다 엄격한 조건임을 알 수 있습니다. 타입 동등은 다음과 같은 2개의 종류로 구분됩니다.
-
이름 타입 동등(Name Type Equivalence) : 두 변수가 동일한 선언, 또는 동일한 타입 이름을 사용하는 선언으로 정의된 경우 타입 동등으로 정의됩니다. 구현하기는 쉽지만, 매우 제한적이라는 특징이 있습니다. 예를 들어, 정수의 부분 범위를 갖는 변수는 정수 타입 변수와 동등하지 않게 정의됩니다.
-
구조 타입 동등(Structure Type Equivalence) : 두 변수의 타입이 동일한 구조를 갖는 경우 타입 동등으로 정의됩니다. 구조 타입 동등은 이름 타입 동등보다 유연하지만 구현하기가 더 어렵습니다.

변수의 영역(Scope)은 변수를 볼 수 있는 범위를 일컫습니다. 만약 변수를 해당 문장에서 참조할 수 있는 경우, 볼 수 있다(Visible)고 표현합니다. 변수가 프로그램이나 블록 내에 정의되면 지역 변수(Local Variable)이라고 합니다. 반대로 비지역 변수(Nonlocal Variable)은 해당 프로그램이나 블록 내에서 볼 수 있지만, 그곳에서 선언되지 않은 경우를 말합니다. 전역 변수(Global Variable)은 비지역 변수 중 하나라고 볼 수 있습니다. 비지역 변수는 그 규칙에 따라 정적 영역과 동적 영역으로 구분할 수 있습니다.
정적 영역(Static Scoping)은 ALGOL 60에서 처음 도입되었으며, 실행 전에 변수의 영역이 정적으로 정해지는 것을 말합니다. 정적 영역은 주로 중첩된 부프로그램에서 생성됩니다. 예를 들어 아래와 같은 경우, 변수 x는 big이라는 프로시저에서 선언되었습니다. 그런데 sub1이라는 프로시저에서 변수 x에 대한 참조가 발생합니다. sub1 내에서 변수 x를 선언하지 않았다고 하면, sub1의 상위 프로시저를 탐색하여 변수 x에 대한 선언을 찾습니다. 프로시저의 호출 순서가 big -> sub2 -> sub1이라서 sub1의 상위 프로시저가 sub2라고 착각할 수도 있지만, sub1의 프로시저는 big 프로시저 안에서 정의되어있기 때문에 (정적 영역 하에서는) 무조건 big의 변수 x를 참조함에 유의하시기 바랍니다.
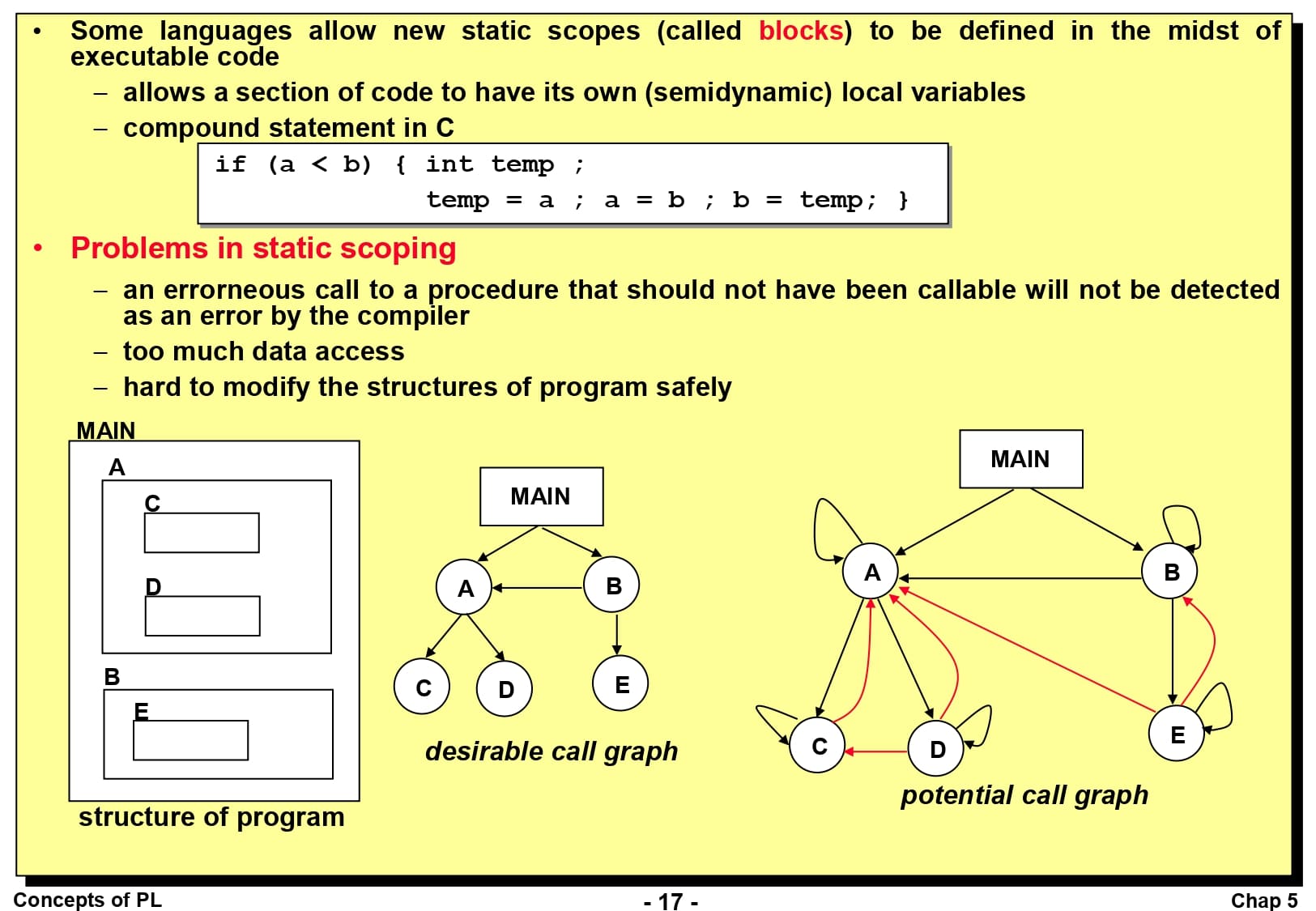
몇몇 언어는 블록(Block)이라는 개념을 도입하여 새로운 정적 영역이 코드 중간에 정의되는 것을 허용하고 있습니다. 블록이라는 코드의 일부분에서만 사용할 수 있는 지역 변수를 선언할 수 있으며, 스택 동적으로 선언되기 때문에 블록 내에 진입할 때 기억공간에 할당되고 블록을 빠져나올 때 기억공간에서 해제됩니다. 이것은 C 언어에서 다음과 같이 temp라는 변수처럼 사용됩니다.
정적 영역은 많은 상황에서 잘 작동하지만, 여러가지 문제점을 내포하고 있습니다. 첫째로, 호출할 수 없어야 하는 프로시저에 대한 오류는 컴파일러에서 오류로 감지되지 않는다는 문제가 있습니다. (영역 구멍) 둘째로, 변수와 부프로그램에 대한 접근을 너무 많이 허용한다는 것입니다. 또한 프로그램을 업데이트할 때 문제가 발생할 소지가 많은데, 이러한 접근 방식을 제대로 이해하지 못하고 코드를 추가할 경우 필요 이상으로 전역 변수를 사용하거나 접근 방식이 꼬일 가능성이 높습니다.
동적 영역(Dynamic Scope)은 부프로그램들의 상호간의 공간 배치가 아닌, 부 프로그램의 호출 시퀀스에 기반한 영역 방식입니다. 따라서 동적 영역은 실행 시간에 결정됩니다. APL, SNOBOL4, LISP의 몇몇 분파 언어들에서 사용되는 방식이며, 프로그램 단위 간 편리하게 매개변수를 전달할 수 있다는 장점이 있습니다. 정적 영역에서 보았던 big, sub1, sub2 프로시저를 다시 보시면 호출 순서가 big -> sub2 -> sub1 이었습니다. 따라서 동적 영역이라고 가정하면 sub1에서 참조하는 x는 sub2에서 선언한 x가 됩니다.
동적 영역 또한 문제가 발생할 수 있습니다. 첫째로, 부프로그램의 지역 변수는 실행 중인 다른 부프로그램에서 모두 볼 수 있습니다. 그들간의 코드상 거리와는 상관이 없기 때문에, 지역 변수를 보호할 수 있는 방법이 없고 결과적으로 정적 영역보다 덜 신뢰적인 프로그램이 만들어지게 됩니다. 둘째로, 비지역 변수를 참조할 때 정적으로 타입 검사할 수 없습니다. 마지막으로, 변수에 대한 참조가 항상 동일한 변수에 대해 일어나는 것이 아니기 때문에 가독성이 떨어지는 문제도 있습니다.
따라서 동적 영역은 정적 영역에 비해 널리 사용되지 않고 있습니다. 일반적으로 정적 영역 언어가 가독성이 좋고, 더 신뢰적이고, 더 빠르게 실행되는 것이 정설입니다.
다음으로는 변수의 영역과 수명에 대해 알아보겠습니다. 변수의 영역과 수명은 얼핏 보면 동일하거나, 거의 관련이 있는 것처럼 보입니다. 그러나 상황에 따라 완전히 달라질 수 있습니다. 먼저 변수의 영역과 수명에 대한 정의부터 다시 해보겠습니다.
- 영역(Scope) : 변수의 선언부터 프로시저의 마지막 예약어까지의 범위
- 수명(Lifetime) : 프로시저에 진입한 시점부터 프로시저의 실행이 종료된 시점까지의 기간
예를 들어 오른쪽 코드에서 변수 sum의 영역과 수명을 각각 계산해보겠습니다. 먼저 변수 sum의 영역은 compute 프로시저에 완전히 포함됩니다. printheader 프로시저가 compute 프로시저 안에서 실행되지만, sum의 영역은 printheader 함수의 내부까지 포함하지는 않습니다. 그러나 sum의 수명은 printheader가 실행되는 시간도 포함되며, printheader 호출 전에 기억공간에 바인딩 된 sum은 printheader의 실행 동안과 그 이후에도 지속됩니다.
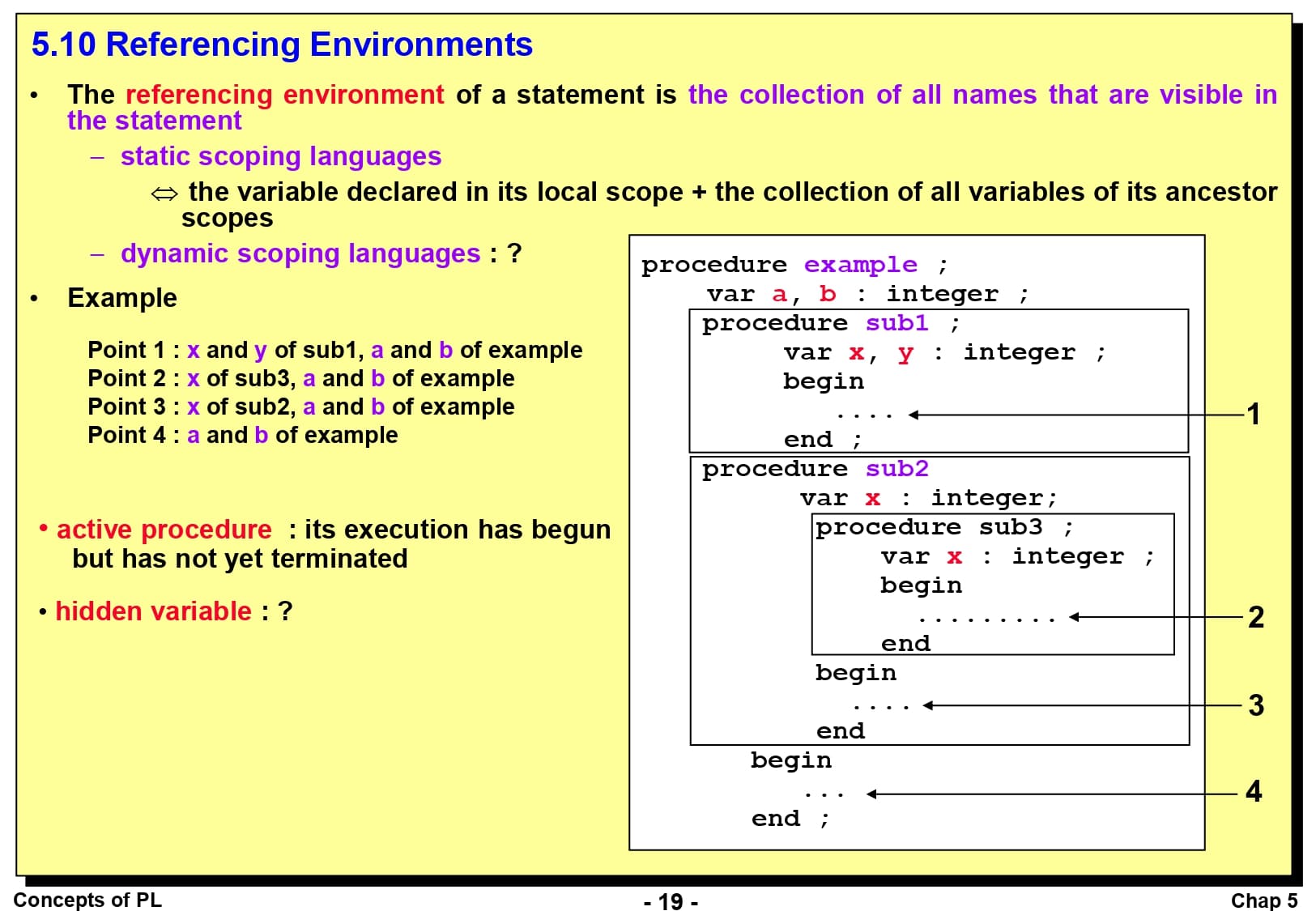
코드에 있는 어떤 문장의 참조 환경(Referencing Environment)은 그 문장에서 볼 수 있는 모든 이름의 모음입니다. 정적 영역 언어라면 어떤 문장의 참조 환경은 그 지역에서 선언된 변수와 그 조상 영역에서 선언된 변수의 모음이 됩니다. 동적 영역 언어라면 지역 변수와 함께 현재 활성화 되어있는 다른 모든 부프로그램(Active Procedure)에서 선언된 변수로 구성됩니다.
참조 환경을 더 쉽게 이해하기 위해서 오른쪽의 코드를 보겠습니다. 1번 위치에서 참조 환경은 sub1 프로시저에서 선언된 x, y와 그 상위 프로시저인 example에서 선언된 a, b입니다. 2번 위치에서 참조 환경은 sub3에서 선언된 x와 example에서 선언된 a, b가 됩니다. sub2에서 선언된 x는 당연히 무시되는데, 이것을 숨겨진 변수(Hidden Variable)라고 합니다. 3번 위치에서 참조 환경은 sub2에서 선언된 x와 example에서 선언된 a, b입니다. 4번 위치에서 참조 환경은 example에서 선언된 a, b가 되는 것입니다.

이름 상수(Name Constant)는 단지 한 번만 값에 바인딩되는 변수입니다. 예를 들어 원주율 3.14159265… 의 값을 PI로 할당해놓으면 가독성이 상승하는 효과가 있습니다. Java의 final 키워드가 대표적인 예시입니다.
마지막으로 변수가 기억 공간에 바인딩되는 시점에 값을 바인딩 하는 것을 초기화(Initialization)라고 부릅니다. 만약 변수가 기억공간에 정적으로 바인딩되면 바인딩과 초기화는 실행 시간 이전에 일어납니다. 만약 기억공간 바인딩이 동적이라면 초기화도 동적입니다. 대표적으로 C 언어에서 int sum = 0; 과 같은 문장이 초기화입니다.
5장의 내용은 여기까지입니다. 읽어주셔서 감사합니다!
Leave a comment