
Linear Model II

9장은 3장에 이어서 선형 모델을 배우게 됩니다. 교재에서는 3장과 9장의 내용이 하나의 장으로 구성되어 있지만, 인터넷 강의에서는 이론적인 내용을 연속해서 다루기보다 중간에 구체적인 예시를 추가하기 위하여 두 장으로 나누었다고 합니다. 따라서 이번 장을 공부하기 전에 3장을 다시 한번 복습하시는 것을 추천합니다.
Outline

3장에서 다루었던 것과 이번 장에서 다룰 것을 정리해봅시다. 3장에서 선형 분류(Linear Classification), 선형 회귀(Linear Regression)가 무엇인지 배웠고, 어떤 알고리즘을 사용해 학습하는지까지 간단히 소개하였습니다. (물론 3장에서 배운 학습 알고리즘이 전부는 아닙니다.)
또한 3장 마지막에는 비선형 문제를 해결하는 방법인 Transform을 소개하였습니다. 다만 그 당시에는 간단하게 넘어갔기 때문에 이번 장에서 Nonlinear Transform을 먼저 더 공부하고, 이전에 다루지 않았던 Logistic Regression에 대해 본격적으로 공부하게 됩니다.
Nonlinear transforms

3장에서 배운 비선형 문제를 푸는 방법을 다시 한번 복습하고 넘어갑시다. 주어진 Input Data $\mathbf{x}$는 $d$차원의 벡터입니다. ($x_0$은 Threshold 역할을 하기 때문에 $d$에 포함시키지 않았습니다.) 그러나 $\mathbf{x}$의 분포가 선형 분리가 되지 않는 경우, 이를 선형 분리가 가능한 데이터로 만들어주기 위해 새로운 함수 $\Phi$를 정의하여 $\mathbf{z}$로 바꾸어 주었습니다. 이 때, $\mathbf{x}$와 차원이 달라질 수 있기 때문에 $\mathbf{z}$는 $\tilde{d}$차원을 갖게 됩니다.
여기서 주의할 점은, 변환을 하기 전과 변환을 하고 난 데이터의 Output은 동일하기 때문에, 굳이 변환한 학습 결과를 원래 차원으로 되돌릴 필요가 없다는 것입니다. 즉, 최종 가설 $g$는 선형 분류 문제의 경우 $\text{sign}(\tilde{\mathbf{w}}\Phi(\mathbf{x}))$, 선형 회귀 문제의 경우에는 $\tilde{\mathbf{w}}\Phi(\mathbf{x})$가 됩니다.
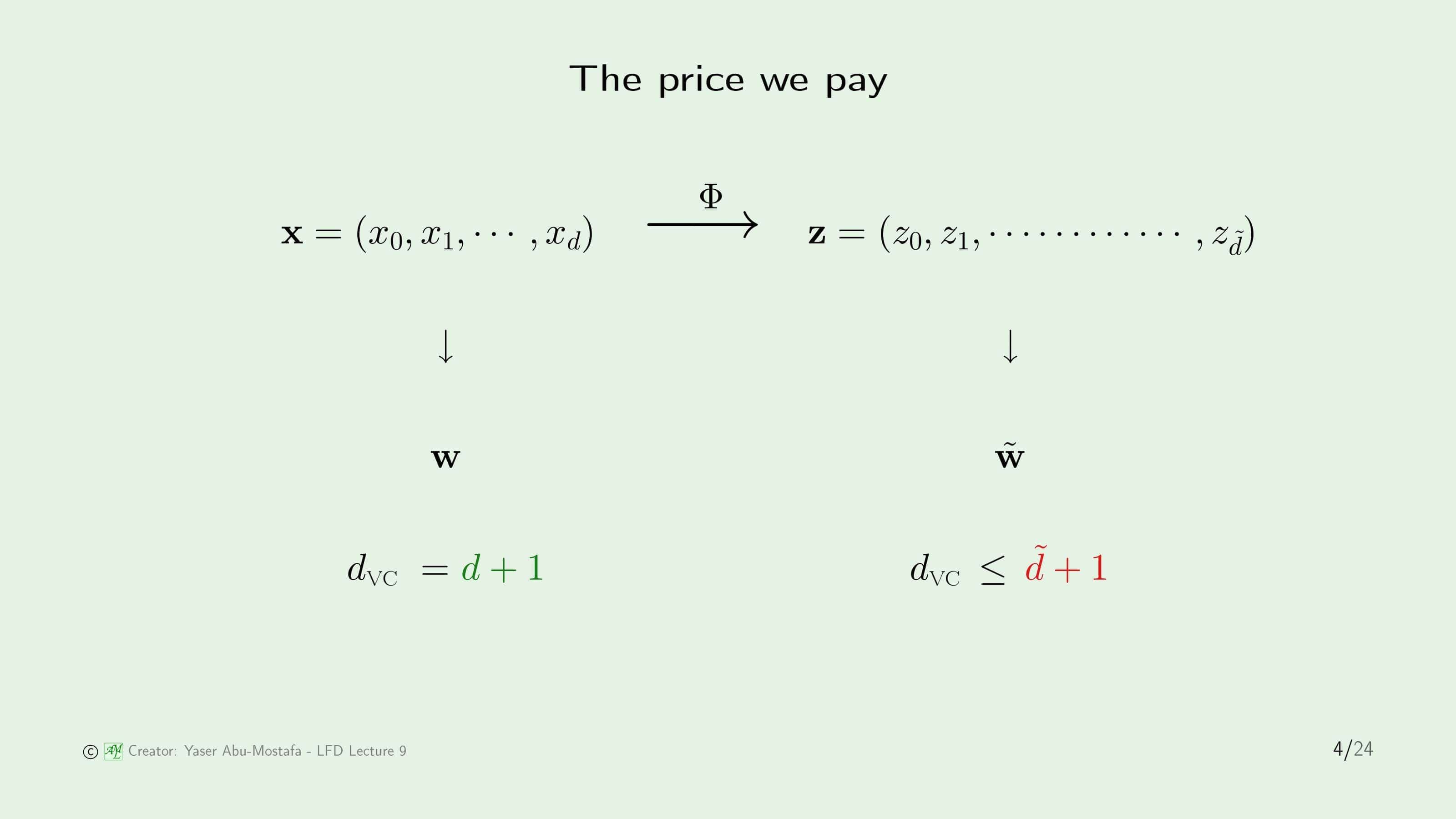
하지만 비선형 문제를 Transform을 통해 문제를 해결하게 되면 새로운 문제가 생기게 됩니다. 3장에서 이것을 처음 배울 때는 단순히 $\Phi$함수를 찾기가 쉽지 않다는 단점만을 생각할 수 있었지만, VC Dimension을 배우고 나니 Transform을 하게 되면 VC Dimension 또한 바뀌게 된다는 사실도 알게 되었습니다. 일반적으로 선형 데이터로 만들기 위해 Transform을 하는 것은 차원이 늘어날 수밖에 없기 때문에 VC Dimension 또한 늘어나게 됩니다. VC Dimension이 늘어난다는 것은 그만큼 일반화하기 힘들다는 말과 같습니다.
원래의 데이터 $\mathbf{x}$의 VC Dimension은 Threshold를 포함하여 $d+1$인데, $\mathbf{z}$의 VC Dimension은 최대 $\tilde{d}+1$이 됩니다. 왜 정확히 $\tilde{d}+1$이 아니라 최대 $\tilde{d}+1$이 되냐면 $\mathbf{z}$는 $\mathbf{x}$를 통해 만들게 되기 때문입니다. 이전 슬라이드의 Example 처럼 $\mathbf{z}$ 벡터의 각 원소는 $\mathbf{x}$의 원소를 사용해 만들기 때문에, 각 원소가 독립적이지 않는 경우가 존재하기 때문입니다.

이 문제를 해결하기 위해 비선형 예제 2개를 살펴보겠습니다. 첫번째 예제는 왼쪽 그림처럼 거의 선형이지만 선형으로 나눌 경우 약간의 에러가 발생하는 경우이고, 두번째 예제는 오른쪽 그림처럼 데이터들이 처음부터 비선형이라 선형으로는 절때 나눌 수 없는 경우입니다.
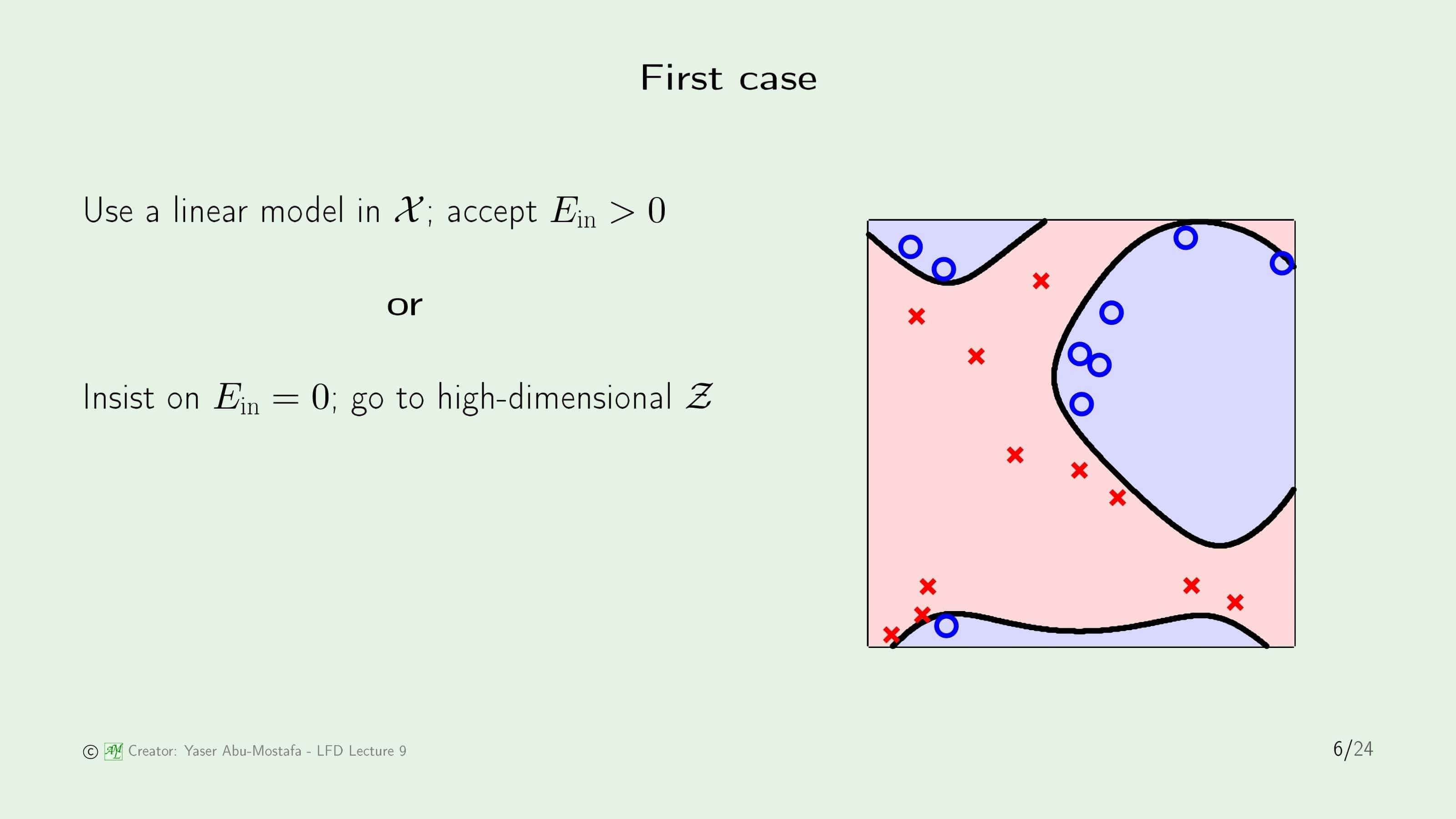
첫 번째 예제는 두 가지 선택을 할 수 있습니다. 약간의 In Sample Error를 감수하고 선형으로 나눌 것인지, 그 Error조차 용납하지 못하고 높은 차원으로 Transform을 시켜 In Sample Error를 0으로 만들게 할 수도 있습니다. 말할 필요도 없이 어떤 방법이 더 좋은지 우리는 이미 알고 있습니다. 굳이 VC Dimension을 따져보지 않더라도 Transform을 시켜서 푸는 방법이 일반화가 더 어렵기 때문에 더 좋지 않은 해결방법이라는 직관적인 판단을 하셨다면, 훌륭합니다.
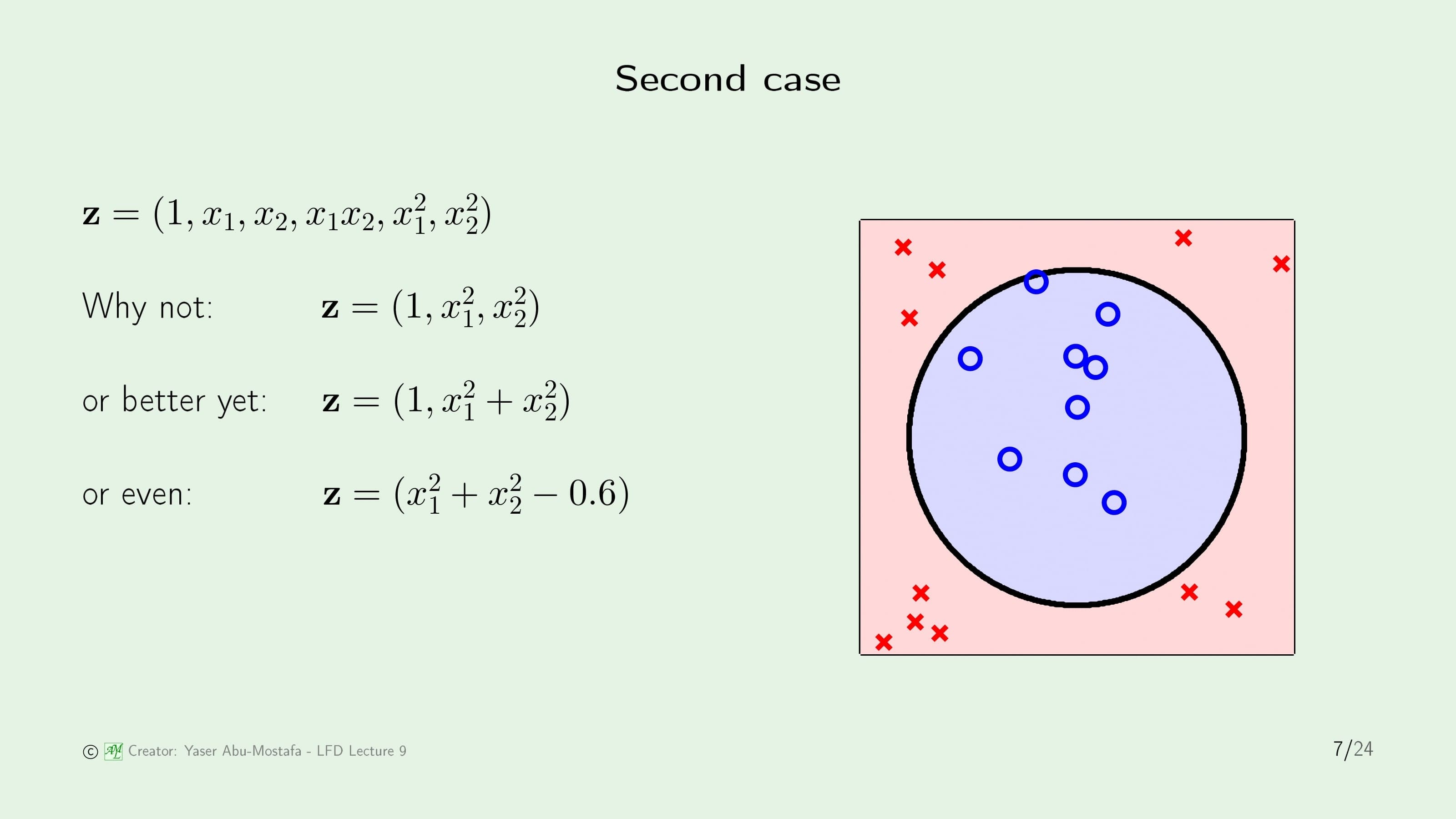
두 번째 예제는 Transform을 해야만 문제를 풀 수 있기 때문에 Transform을 한다고 가정합시다. 원래의 데이터는 $x_1, x_2$로 이루어진 2+1차원의 데이터였으나, 차수를 늘려 5+1차원의 데이터로 바뀌게 되었습니다. 그렇게 Transform을 하고 학습을 성공적으로 마쳤을 때의 상황이 바로 오른쪽 그림입니다. 가만히 생각해보면, 나눈 결과를 보아하니 원 모양인데, 원의 방정식에 필요한 2차항만 남겨서 차수를 줄일 수 있지 않을까하는 느낌이 들 수도 있습니다. $x_1^2, x_2^2$만 남기고 2+1차원을 데이터로 바꿀 수도 있고, 혹은 그보다 줄이는 방법도 생각해 볼 수 있습니다. 물론 초기 상태인 5+1차원과 동일한 결과가 나옵니다. 하지만 이 방법은 뭔가 이상하다는 직관적인 느낌이 듭니다.

방금 전의 두 번째 예제에서 차원을 줄이는 과정을 다시 한번 복기해봅시다. 먼저, 데이터를 Transform 시키고 학습이 끝난 다음 결과를 확인하였습니다. 그런데, 학습 결과를 보고 원과 비슷한 모양인 것을 확인한 후, 의도적으로 Transform 시킨 데이터의 차원을 줄였습니다. 이 부분에서 잘못된 판단을 한 것입니다. 데이터를 눈으로 먼저 보고 모델을 고르는 것을 Data Snooping이라고 하는데, 이렇게 모델을 정할 경우 학습 결과가 일반화와는 거리가 멀어지기 때문에 Out of Sample Error에 큰 악영향을 주게 됩니다. 방금 전에 “원”의 모양을 눈으로 보고 그 모양이 나오도록 학습 결과를 의도적으로 수정했기 때문에 In Sample Error에는 영향이 없을 수도 있지만, 실제 Out of Sample Data가 어떻게 분포되어 있을지 모르는 상황이기 때문에 대부분의 경우에는 Out of Sample Error를 높게 만듭니다. 기계학습에서 가장 많이 행하게 되는 실수라고 하니 반드시 염두해 두도록 합시다.
Logistic regression

이제 본격적으로 이번 장의 핵심 주제인 Logistic Regression을 공부해봅시다. 모델, 오류 측정 방법, 학습 알고리즘 순서로 배우게 됩니다.

Linear Model은 기본적으로 입력을 받고 출력값을 계산한다는 의미입니다. 이전에 배운 Linear Classification과 Linear Regression 모두 입력 $\mathbf{x}$와 가중치 $\mathbf{w}$를 받아 출력값을 계산하였습니다. 단순히 출력값을 그대로 내보내는가(Regression), +1/-1인지만 결정하는가(Classification)의 차이만 있었습니다. Logistic Regression도 이와 마찬가지로 입력 $\mathbf{x}$와 가중치 $\mathbf{w}$를 받아 출력값을 계산하는데, 그 출력값이 $\theta$ 함수를 거쳐 나오게 됩니다.
$\theta$ 함수는 다음 슬라이드에서 설명하도록 하고, 함수의 모양을 먼저 보면 S자를 눕힌 듯한 그래프를 가짐을 알 수 있습니다. 정확하게는, 최댓값은 1, 최소값은 0이 되고 그 사이를 부드럽게 올라가는 곡선입니다. Linear Classification은 Threshold를 기준으로 +1/-1로만 출력값이 나오지만, Logistic Regression은 0과 1 사이의 모든 실수가 출력값이 될 수 있습니다.

로지스틱 함수 $\theta$의 명확한 정의는 ${e^s}/{(1+e^s)}$입니다. $s$가 크면 클수록 1에 가까워지게 되고, 작으면 작을수록 0에 가까워지게 됩니다. 특수한 경우로, $s$가 0이면 정확하게 0.5가 됩니다. 이 함수는 부드럽게 0과 1 사이를 움직이기 때문에 Soft Threshold로 부르기도 하지만, 일반적으로는 Sigmoid Function으로 불립니다. Sigmoid는 “S자 모양의” 라는 뜻입니다.

0과 1사이의 값을 갖는다는 것에서 눈치채신 분들도 계실텐데, 로지스틱 회귀는 바로 확률에 관한 문제를 다룰 때 쓰이게 됩니다. 이해를 돕기 위해 구체적인 예시로 심장 마비를 예측하는 문제가 있다고 가정해봅시다. 심장 마비에 영향을 줄 수 있는 요소인 콜레스트롤 수치, 나이, 몸무게 등은 입력 데이터로 들어가게 됩니다. 만약 Linear Classification으로 이 문제를 접근한다면 심장마비가 발생하지 않는다/발생한다 라는 결과만 출력할 수 있습니다. 그런데 정말 좋지 않은 신체적 상황이라고 해도 심장마비가 무조건 발생하지는 않습니다. 하지만 심장마비의 발생은 입력 데이터에 영향이 분명히 있기 때문에 이러한 상황에서는 확률적으로 접근해야 한다는 것입니다. 따라서 이 문제를 로지스틱 회귀로 풀게 된다면, $\theta$ 함수는 입력 $s$에 대해 심장 마비가 발생할 확률을 의미하게 됩니다. 이 때 입력 $s$는 이전의 선형 분류나 회귀와 마찬가지로 선형이고, 높으면 높을수록 심장 마비를 발생할 확률을 높게 만들기 때문에 “Risk Score”로 부를 수 있습니다.

로지스틱 회귀에서 특이한 점은 학습 데이터입니다. 선형 분류나 회귀와 마찬가지로 지도학습으로 이루어지는데, 선형 분류에서는 데이터의 Output $y$가 +1/-1로, 선형 회귀에서는 실수 $\mathbb{R}$로 주어졌습니다. 그렇기에 로지스틱 회귀에서는 Output $y$가 0과 1 사이의 값으로 주어질 것이라고 생각할 수 있는데 그렇지 않는 것이 문제입니다. 로지스틱 회귀의 학습 데이터는 선형 분류와 마찬가지로 +1/-1로 주어집니다. 물론, 노이즈가 반영되기 때문에 같은 입력값에 대해 다른 Output을 갖고 있는 데이터가 포함됩니다.
이전 슬라이드의 심장 마비 예측 문제를 생각하면, 완전히 동일한 신체조건을 가지고 있는 서로 다른 10명의 환자 데이터가 있다고 했을 때, 이 중 3명이 심장 마비가 발생하고 7명이 발생하지 않았다면 해당 신체조건(=$s$)에서 심장 마비가 발생할 확률이 0.3이다라고 예측하는 방식입니다. 물론 학습 알고리즘에 따라 0.3보다 작을수도, 클수도 있습니다.

이제 로지스틱 회귀에서 Error Measure를 어떻게 하는지 배워봅시다. 선형 분류는 Output이 다른 것의 갯수를, 선형 회귀는 Squared Error를 사용했는데 로지스틱 회귀에서 Error Measure는 직관적으로 어떻게 해야 할지 떠오르지 않습니다.
로지스틱 회귀에서는 Likelihood (가능도)를 Error Measure에 사용합니다. 가능도는 우도라고도 불리는데, 통계학에서 확률 분포가 확률 변수의 특정 값에 얼마나 일관적인지 그 정도를 나타내는 값입니다. 즉, 만약 가설 $h$와 Target Function $f$와 같다면, 가설 $h$에 의해 입력 데이터 $x$가 주어졌을 때 Output으로 $y$를 얻을 확률이 어느 정도인가? 를 의미합니다.

개념을 이해했으니 구체적인 수식을 통해 계산하는 법을 알아봅시다. 먼저 가설 $h$는 로지스틱 회귀이므로 $\theta$ 함수와 같습니다. $\theta$ 함수의 특이한 점은 입력 $s$의 부호를 반대로 넣으면 $1-\theta(s)$와 같습니다. 직접 계산할 필요 없이 오른쪽의 함수 그림을 보시면 점선인 1에서 파란색 선을 빼 보시면 쉽게 알 수 있습니다. 이 성질을 이용하여 가능도 함수를 $P(y \mid \mathbf{x})=\theta(y\mathbf{w}^{\sf T}\mathbf{x})$로 간단하게 표현할 수 있습니다. 이를 이용하여 $N$개의 데이터가 주어져 있다고 가정할 때, 각 데이터에 대해 가능도 함수 $P$를 계산하여 곱하면 됩니다. 가능도 함수는 방금 구한 $\theta$ 함수와 같으니 $\theta$ 함수로 바꿔도 무방합니다.

가능도는 인과관계를 의미하기 때문에 기존의 다른 Error Measure와 다르게 높을 수록 좋은 수치입니다. 그렇기에 다른 방법과의 통일성을 위해, 이전 슬라이드에서 도출한 식의 부호를 반대로 하고, 그 값을 최소화하는 방향으로 최적화를 진행할 것입니다. 식을 간단하게 정리하기 위해 마이너스 기호를 로그 안에 넣고, 파이를 로그 밖으로 빼어 시그마로 바꿉니다. 수식을 $N$으로 나눈 이유는 모든 주어진 데이터에 대해 평균적인 Error를 구하기 위함입니다.
최적화를 수행하기 전에, $N$, $y$, $\mathbf{x}$는 모두 고정된 값이기 때문에 임의로 바꿀 수 없음에 유의하시기 바랍니다. 우리는 이 식에서 오로지 $\mathbf{w}$만 수정해야 합니다.
먼저 $\theta$ 함수를 풀어서 표현합니다. 이전에 나온 $\theta$ 식과 조금 달라보이는데, 분모와 분자를 모두 $e^s$로 나눈 것 외에는 동일합니다. 식을 마지막까지 정리하게 되면 깔끔한 식이 나오게 되는데, 이 중 로그 부분을 따로 떼어 $e(h(\mathbf{x}_n, y_n)$으로 정의합니다. 이런식의 Error Measure를 Cross-Entropy Error라고 부릅니다.

다음 순서로는 로지스틱 회귀에서 어떤 학습 알고리즘을 사용할 것인지 배우게 됩니다.

이제 In Sample Error를 계산하는 식을 구했으니, 이를 최소화 시키는 방법을 알아야 합니다. 이전에 배운 선형 회귀의 경우 Pseudo-Inverse를 이용하여 여러 단계를 거치지 않고 한번에 최적의 가중치 $\mathbf{w}$를 계산하였습니다. 그러나 로지스틱 회귀에서는 불행하게도 로그 함수의 존재로 인해 한번에 쉽게 구하는 방법이 없습니다. 따라서 반복적인(Iterative) 방법으로 계산해야만 합니다.
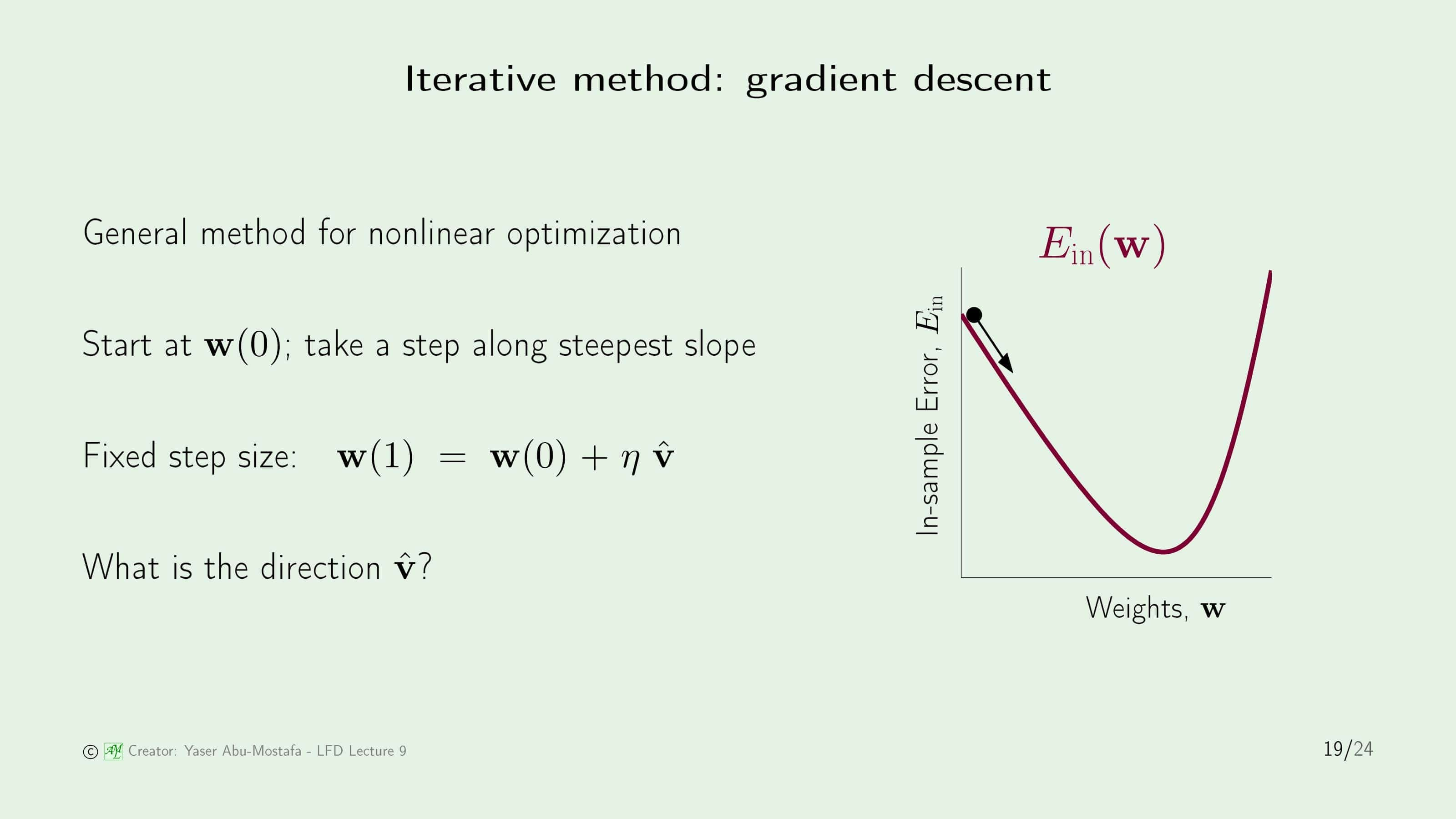
반복적인 방법 중 대표적인 것이 바로 Gradient Descent (경사하강법)입니다. 여기서 Gradient는 미적분학에서 배우는 기울기입니다. 위 슬라이드의 오른쪽 그림을 보시면 최종 목적지는 In Sample Error가 가장 낮게 나오는 점입니다. 이 점을 한번에 구할 수 없기 때문에 초기에는 무작위로 $\mathbf{w}$를 정합니다. 이 곳이 최종 목적지라면 좋겠지만 일반적인 경우에는 그렇지 않으니 이 점에서 다른 점으로 움직여야 합니다. 그 움직이는 방향을 가리키는 것이 단위벡터 $\widehat{\mathbf{v}}$입니다. 단위벡터 앞에 붙은 상수 $\eta$(에타)는 얼마나 움직일 것인지 그 크기를 나타냅니다. 그렇게 움직인 결과가 바로 새로운 $\mathbf{w}$가 되는 것입니다.
방법을 알았으니 이제 방향을 결정하는 단위벡터 $\widehat{\mathbf{v}}$만 구하는 방법을 알면 됩니다. 이름에서 눈치채신 분들도 있지만, 이걸 구할때 바로 기울기(Gradient)를 이용합니다.

먼저, 이전 슬라이드에서 구한 $\mathbf{w}(1)$과 초기값 $\mathbf{w}(0)$을 비교해봅시다. $\mathbf{w}(1)$을 넣어서 In Sample Error를 계산하고, $\mathbf{w}(0)$을 넣어서 In Sample Error를 계산한 후, $\mathbf{w}(1)$로 계산한 In Sample Error에서 $\mathbf{w}(0)$로 계산한 In Sample Error를 빼면 In Sample Error의 차이($\Delta E_{in}$)를 계산할 수 있습니다. 우리가 원하는 것은 반복적인 과정을 거칠 때마다 In Sample Error가 줄어드는 것을 원하므로 이 변화가 음수가 나와야 합니다.
이 차이를 계산하기 위하여 테일러 급수를 사용해야 합니다. 테일러 급수에서 맨 앞 항만 사용하고 나머지 부분은 $O(\eta^2)$로 묶었습니다. 사실 중요한 것은 맨 앞부분에 있는 $\widehat{\mathbf{v}}$ 이기 때문에 식을 간략화한 후 정규화(Normalization)를 시키면, $\mathbf{w}(0)$에서의 기울기 단위 벡터를 얻을 수 있습니다. 왜 $\widehat{\mathbf{v}}$에 마이너스(-) 가 붙는 지 궁금하실 수도 있는데, 쉽게 이해하기 위해서는 이전 슬라이드의 그림을 떠올리시면 됩니다. 그림처럼 점이 최소값의 왼쪽에 있을 때는 오른쪽으로 점을 움직여야 하는데, 현재의 기울기가 음수이므로, 양의 방향으로 움직여야 하기 때문입니다. 즉, 움직여야 하는 방향은 현재 기울기의 반대 방향임을 알 수 있습니다.
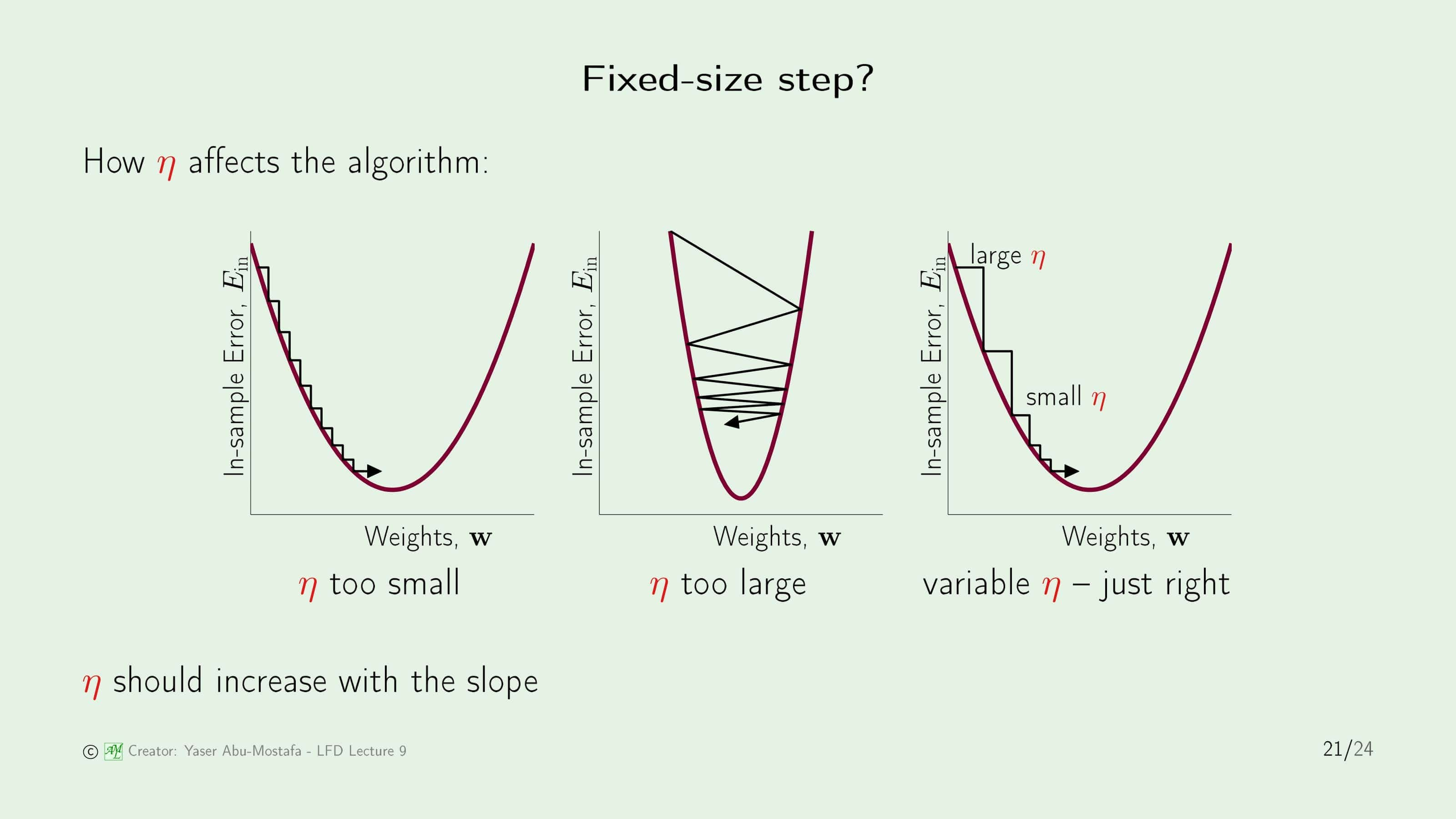
그 다음으로 논의할 것은 $\eta$입니다. 처음에는 $\eta$를 고정된 값을 사용한다고 했는데, 만약에 이 $\eta$가 너무 작으면 최종 목적지에 도달하는데 너무 많은 단계를 거쳐야 하는 문제가 생길 수 있습니다. 그렇다고 이 값을 크게 만들다가 너무 커지게 되면, 최종 목적지를 지나칠 수도 있고, 그 주변에서 왔다갔다 하느라 목적지에 도달하지 못할 수도 있습니다. 따라서 이런 단점들을 해결하기 위해, $\eta$를 유동적인 값을 사용하는 것이 좋습니다. 초기에는 큰 값을 부여해 목적지에 빠르게 가깝게 다가가고, 나중에는 작은 값을 부여해 목적지를 지나치지 않고 쉽게 다가갈 수 있도록 만드는 것입니다.

그럼 유동적인 $\eta$를 어떻게 구현해야 할지 구체적으로 계산해봅시다. 이 강의에서는 $\Delta\mathbf{w}$의 식을 응용하여 $\eta$를 정의하였습니다. 바로 기존의 $\eta$값을 $\lVert \triangledown E_{in}(\mathbf{w}(0)) \rVert$에 비례하게 만들어 $\widehat{\mathbf{v}}$의 분모를 약분할 수 있게 만든 다음, 새로운 고정된 값인 $\eta$로 정의하는 것입니다. $\eta$ 기준에서 보면 초기에는 기울기가 가파르기 때문에 높은 값을 가지지만 목적지에 도달할수록 기울기가 완만해지기 때문에 낮은 값을 갖게 됩니다. 굉장히 기발한 아이디어라고 생각합니다.

이제 필요한 것을 모두 배웠으니 이를 정리하여 하나의 알고리즘으로 통합해 봅시다. 먼저 무작위로 $\mathbf{w}(0)$을 정하고, 기울기를 계산하여 다음 단계의 $\mathbf{w}$를 계산합니다. 이 과정을 최종 목적지(In Sample Error가 가장 낮은 지점)에 도달할 때까지 반복하면 됩니다.
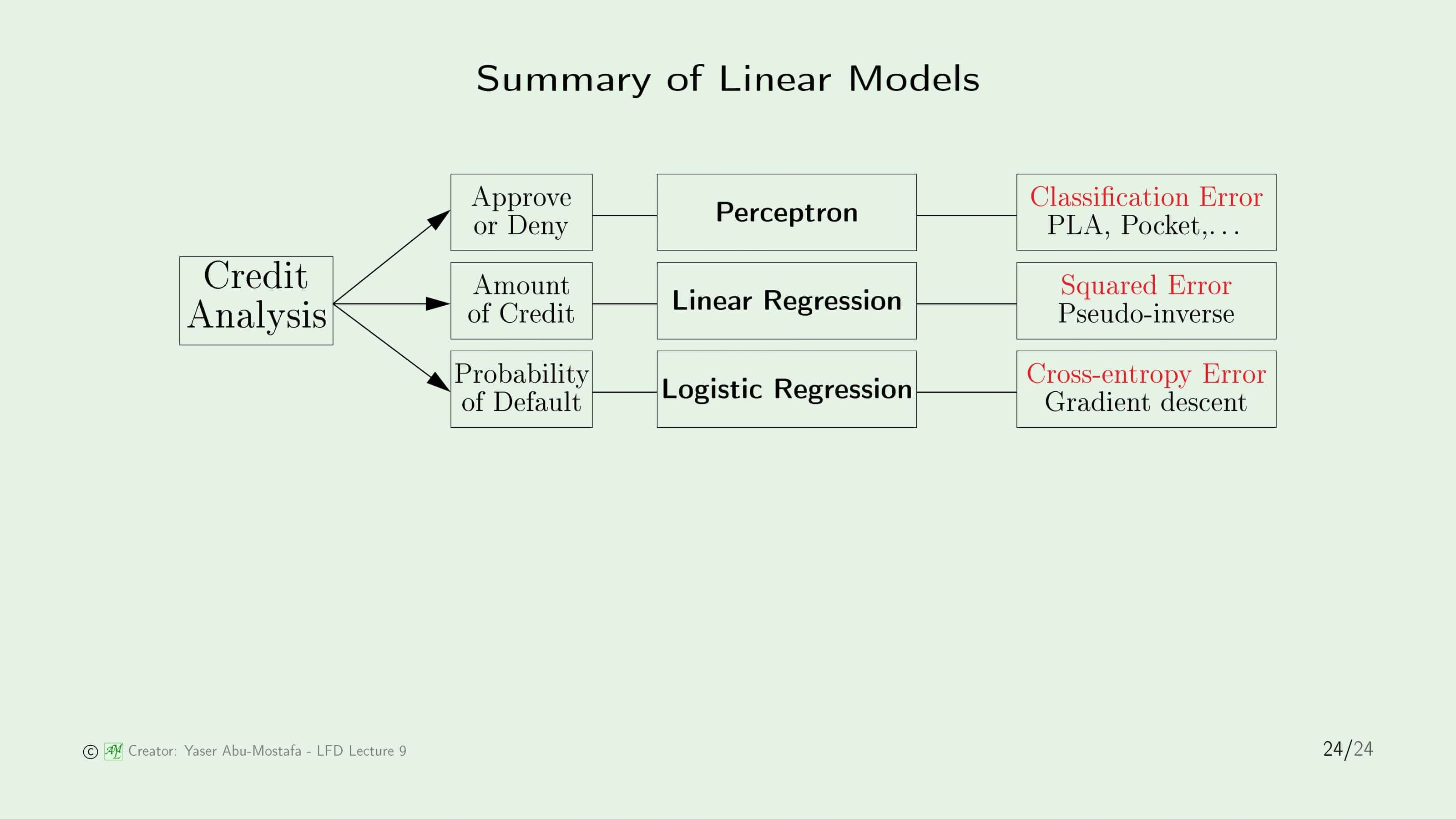
마지막으로, 지금까지 배운 선형 모델을 간단하게 정리해봅시다. 선형 모델에는 선형 분류, 선형 회귀, 로지스틱 회귀 3가지로 나뉩니다. 3장에서 배운 신용 카드 발급 문제를 예로 들면 선형 분류는 신용 카드를 발급할지/거부할지를 결정하는 모델이고, 선형 회귀는 신용 카드를 발급한다면 한도를 얼마로 정할 것인지를 결정하는 모델이며, 로지스틱 회귀는 이 사람이 파산할 확률(즉, 신용카드 대금을 갚지 못할 확률)을 계산하는 모델입니다. 세 모델의 목적이 모두 다르기 때문에 오류 측정 방법도 모두 다릅니다. 선형 분류는 얼마나 분류가 틀렸는지(Classification Error), 선형 회귀는 정답과 얼마나 멀리 떨어져 있는지(Squared Error), 마지막으로 로지스틱 회귀는 입력과 출력이 얼마나 관련이 있는지(Cross-Entropy Error)를 기준으로 삼게 됩니다.
이번 장은 여기까지입니다. 읽어주셔서 감사합니다.
Leave a comment