
Abstract Data Types and Encapsulation Constructs

11장의 주제는 추상 데이터 타입과 캡슐화 구조입니다. 프로그래밍을 어렵게 만드는 것은 데이터의 컴퓨터 표현이 부자연스럽기 때문입니다. 추상화는 프로그래밍의 복잡성에 맞서는 무기로, 추상화의 목적은 프로그래밍 프로세스를 단순화하는 것입니다. 프로그래머가 필수 속성에 집중하고, 하위 속성을 무시할 수 있도록 하기 때문에 효과적인 무기입니다.
데이터 추상화의 두 가지 주요 기능은 다음과 같습니다.
- 관련 작업으로 데이터 객체를 캡슐화하기
- (중요한) 정보를 숨기기

일반적으로 추상화(Abstraction)의 개념은 프로세스나 객체의 일부 범주가 해당 속성의 부분집합으로만 표현될 수 있다는 것입니다. 이것은 다른 모든 속성이 추상화되거나 숨겨져 있다는 카테고리의 필수 속성입니다. 쉽게 말하면, 추상화는 중요한 속성만을 포함하는 객체의 표현이라고 보시면 됩니다.
추상화는 프로그래밍의 복잡성에 맞서는 무기입니다. 추상화의 목적은 프로그래밍 과정을 단순화하는 것으로, 프로그래머가 필수적인 속성에만 집중하고, 나머지 속성은 무시할 수 있도록 하기 때문입니다.
추상화의 개념 자체는 간단하지만, 프로그래밍 언어가 이것을 지원하도록 설계되기 전까지는 추상화를 사용하는 것이 편리하지 않았습니다. 언어에서 추상화를 위해 지원하는 것 중 대표적인 것은 추상 데이터 타입(Abstract Data Type)이 있습니다.

현대 프로그래밍 언어에서 제공하는 추상화는 프로세스 추상화(Process Abstraction)와 데이터 추상화(Data Abstraction)가 있습니다. 먼저 프로세스 추상화는, 수행 방법을 명시하지 않고 일부 프로세스가 수행되도록 프로그램이 실행될 수 있도록 하는 방법입니다. 이 개념은 프로그래밍 언어 설계에서 가장 오래된 개념 중 하나입니다. (약 1940년대부터 대중화가 시작) 예를 들어, 9장에서 배운 부프로그램은 호출하는 프로그램에서 프로세스가 어떻게 동작하는지에 관해서 상세하게 지정할 필요가 없습니다. 따라서 모든 부프로그램은 프로세스 추상화입니다. 예를 들어, 프로그램이 어떤 데이터를 정렬하려고 할 때, SORT_INT(LIST, LENGTH)와 같이 호출할 수 있습니다.
그러나 이러한 호출은 SORT_LIST의 알고리즘이 명시되지 않은 정렬 프로세스의 추상화입니다. 따라서 이 부프로그램의 호출은 호출된 부프로그램에서 구현된 알고리즘과 독립적입니다. 이 부프로그램의 필수 속성은 정렬할 배열의 이름, 원소의 타입, 그리고 배열의 길이입니다. SORT_INT의 알고리즘이 버블 정렬인지, 퀵 정렬인지는 상관이 없습니다.
데이터 추상화는 표현 및 구현 세부사항을 프로그래메에 의해 숨기는 것을 말합니다. 이렇게 설명하면 프로세스 추상화와 매우 비슷하게 들리겠지만, 실제로 데이터 추상화와 프로세스 추상화는 매우 연관되어 있습니다. 왜냐하면 프로세스 추상화의 광범위한 사용은 결국 데이터 추상화를 이끌어내기 때문입니다.

이 장에서는 데이터 추상화에 대해서만 더 집중적으로 논의해보겠습니다. 데이터 추상화는 프로그래밍 방법론의 개념 중 하나인데, 프로세스 추상화보다 훨씬 늦게 발견되었습니다. 이것은 COBOL과 함께 Data-oriented Programming이 화두가 되었던 1960년대에 시작되었습니다. 데이터 추상화를 위한 동기는 프로세스 추상화가 만들어진 동기와 비슷합니다. 즉, 크고 복잡한 프로그램을 더 잘 다룰 수 있도록 복잡성에 대항하기 위한 방법 중 하나입니다.
대표적인 데이터 추상화의 구현으로써 추상 데이터 타입(Abstract Data Type)이 있습니다. 추상 데이터 타입은 레코드 타입의 데이터 구조이지만, 데이터를 다루는 부프로그램을 포함하고 있습니다. 구문적으로 따졌을 때, 추상 데이터 타입은 한 개의 특별한 데이터 타입과, 그 데이터의 표현 및 연산을 제공하는 부프로그램을 포함합니다. 접근 제어를 이용하여 불필요한 세부 사항들은 외부로부터 숨길 수 있습니다. 추상 데이터 타입을 사용하는 프로그램 단위는, 그 타입의 변수를 선언할 수 있지만 어떻게 구현되었는지는 숨겨집니다. 추상 데이터 타입의 인스턴스(Instance)를 객체(Object)라고 부릅니다.
먼저, 추상 데이터 타입으로써 부동 소수점을 알아보겠습니다. 프로그램에 내장된 데이터 타입은 전부 추상 데이터 타입입니다. 예를 들어, 대부분의 언어는 한 가지 이상의 부동 소수점 데이터 타입을 가지고 있습니다. 부동 소수점 데이터 타입은 일반적으로 실수의 값을 저장하는데 사용됩니다. 실제로 부동 소수점 데이터 타입은 부동 소수점 데이터에 대한 변수를 생성하는 수단을 제공합니다. 그리고, 그 유형의 객체를 조작하기 위한 산술 연산(+, *, -, /)을 제공합니다.
그러나, 6장에서 데이터 타입에 대해 구체적으로 배우기 전까지는 이러한 데이터 타입이 어떻게 구성되어 있는지 모르거나 관심이 없었을 겁니다. 즉, 메모리 셀에서 부동 소수점 데이터가 실제로 어떻게 저장되어 있는지는 사용자로부터 숨겨지고, 사용자가 부동 소수점 객체의 표현을 직접 수정할 수 없습니다. 따라서 이것은 데이터 추상화의 중요한 개념인 정보 은폐(Information Hiding)라고 볼 수 있습니다.

부동 소수점 타입에서는 정보 은폐로 인해, 사용자가 사용 가능한 유일한 작업은 시스템 내에서 제공하는 작업들 뿐입니다. 게다가, 부동 소수점 데이터 타입에 대한 새 작업을 생성할 수 없습니다. 이것으로 인해, 부동 소수점 데이터 타입은 특정 형식으로 고정되지 않고, 어느 정도 자유로운 데이터 표현 방법을 가질 수 있습니다.
이러한 표현의 장점은, 기계마다 다른 방법으로 부동 소수점 타입을 표현하더라도 쉽게 프로그램을 이식할 수 있다는 것입니다. 예를 들어, IEEE 704 표준 부동 소수점 표현이 1980년대에 정립되었는데, 그 전에는 컴퓨터 구조마다 부동 소수점 타입을 조금씩 다르게 표현했습니다. 그러나 부동 소수점 타입을 사용하는 프로그램이 여러 컴퓨터 구조에 이식되는 것에 문제가 없었습니다.
사용자 정의 추상 데이터 타입(User-defined Asbtract Data Type)은 일반적인 추상 데이터 타입으로써 다음 두 가지 조건을 만족하는 데이터 타입을 말합니다.
첫 번째 조건은 타입의 선언과 타입의 객체에 수행되는 작업이 단일 구문 단위(그룹, 컴파일 유닛)로 포함된다는 것입니다. (캡슐화)

두 번째 조건은 타입 객체의 표현은 그 타입을 사용하는 프로그램 단위로부터 숨겨지고, 이러한 객체에 직접적으로 수행 가능한 연산은 타입의 정의에서 제공하는 연산 뿐이라는 것입니다. (정보 숨김)
이렇게 표현과 연산을 단일 구문 단위로 패키징하면 다음과 같은 장점이 있습니다.
-
캡슐화에 의한 지역적 수정 : 이러한 타입을 사용하는 프로그램 단위는 표현의 세부사항을 볼 수 없으므로, 표현의 방법에 의존하지 않습니다. 게다가 표현 방법은 해당 타입을 사용하는 프로그램 단위에 영향을 주지 않고, 언제든지 변경할 수 있습니다.
-
정보 은폐로 인한 신뢰성 향상 : 프로그램 단위는 의도적으로, 또는 우연히 표현의 일부를 직접 변경할 수 없으므로, 해당 객체의 무결성(Integrity)이 향상됩니다. 객체는 오로지 제공하는 연산을 통해서만 변경할 수 있습니다.
무결성으로 인한 정보 은폐의 대표적인 장점 중 하나는 신뢰성이 증가한다는 것입니다. 또 다른 장점은 프로그래머가 프로그램을 작성하거 읽을 때 유의해야할 코드의 범위와 개수가 줄어든다는 것입니다. 특히, 추상 데이터 타입 내에서 정의된 변수의 값은 제한된 영역에서만 변화될 수 있기 때문에 코드를 이해하기 쉽고, 의도치 않게 그 값이 변경되는 사태를 막을 수 있습니다.
만약 추상 데이터 타입에 있는 데이터를 Public과 같은 공용으로 명세하고, 그 데이터 대한 접근 방법을 제공하는 것은 추상 데이터 타입의 원리를 위반하는 것이므로 주의하시기 바랍니다.

예를 들어서, 스택(Stack)에 대한 추상 데이터 타입을 살펴보겠습니다. 스택에서 허용된 연산은 다음과 같이 정의되어 있습니다.
- create(stack) : 스택 객체를 생성한다.
- destroy(stack) : 스택을 위한 기억공간을 해제한다.
- empty(stack) : 스택이 비어있으면 true, 그렇지 않으면 false를 반환한다.
- push(stack, element) : 스택에 element 원소를 추가한다.
- pop(stack) : 스택 가장 위의 있는 원소를 제거한다.
- top(stack) : 스택 가장 위의 있는 원소를 반환한다.
그러나 이러한 기능들만 만족하면, 내부 구현이 배열로 구성되었던 연결 리스트로 구성되었던 전혀 신경쓸 필요가 없습니다. 이렇게 데이터 추상화의 목표는 데이터 객체를 하나하나 표현하는 것이 아니라, 추상적인 속성에만 의존하여 프로그램을 작성할 수 있는 기능을 제공하는 것입니다. 게다가, 나중에 스택의 구현 내용을 수정하더라도, 각각의 기능의 프로토타입이 변경되지 않는다면 스택 객체를 사용한 코드를 변경할 필요가 없다는 것도 장점입니다.

그렇다면 추상 데이터 타입을 설계할 때 무엇을 고려해야 할까요? 언어에서 추상 데이터 타입을 정의하기 위해서는 타입 선언과 그 타입의 객체에서 가능한 연산을 구현하는 부프로그램을 같이 설계해야 합니다. 또한 추상화를 사용하는 다른 프로그램 단위가 타입 이름과 부프로그램 헤더(프로토타입)를 볼 수 있어야 합니다. 물론 타입의 표현은 은폐되어야 합니다.
타입에 대한 정의와 함께 주어지는 연산 외에도, 일반적인 연산들이 추상 데이터 타입 객체에 제공되어야 합니다. 이러한 연산은 대표적으로 배정(Assignment), 동치(Equality) 비교가 있습니다. 만약 객체 내의 변수가 있다면, 그 변수를 외부에서 직접 수정하는 것은 최대한 지양되어야 합니다. 대신, 객체 내의 연산을 통해 간접적으로 객체 내의 변수를 조절할 수 있어야 합니다. 동치 비교 또한 두 개의 객체가 같은지, 다른지는 ==와 같은 일반적인 연산 대신 객체 내에 정의된 연산으로 비교가 가능해야 합니다.
또한 추상 데이터 타입의 캡슐화 요구 사항은 두 가지 방법으로 충족할 수 있습니다. 첫 번째 방법은 단일 데이터 타입과 그 연산을 사용자가 직접 정의할 수 있도록 제공하는 것입니다. Pascal과 Smalltalk, C++이 이러한 방법을 사용합니다. 두 번째 방법은 많은 객체를 정의할 수 잇는 일반화된 캡슐화 구조를 제공하는 것입니다. 이러한 각각의 객체는 외부에 선택적으로 보일 수 있도록 지정할 수 있습니다. Modula-2와 Ada 같은 언어가 이러한 방법을 사용합니다.

추상 데이터 타입을 설계할 때 고려해야 할 것들을 정리하면 다음과 같습니다.
- 추상적일 수 있는 타입의 종류를 어떻게 제한할 것인가?
- 추상 데이터 타입이 제네릭, 또는 매개변수화 될 수 있는가?
- 지역 이름과 비지역 이름 간의 충돌을 방지하기 위해 가져온 타입을 어떻게 한정할 것인가? (접근 제어)
그렇다면 각각의 언어에서 추상 데이터 타입을 어떻게 정의하고 있는지 하나씩 살펴보겠습니다.
가장 먼저 살펴볼 언어는 SIMULA 67입니다. SIMULA 67 언어는 완전한 추상 데이터 타입을 위한 지원은 없지만, 데이터 추상화의 개념이 처음 시작된 언어입니다. 캡슐화의 관점에서 SIMULA 67의 클래스 정의는 타입에 대한 템플릿(Template)입니다. 클래스의 인스턴스는 사용자 프로그램의 요청에 따라 동적으로 생성되며, 포인터 변수로만 참조가 가능합니다.
클래스 정의의 구문 형식은 인스턴스 생성 시, 클래스 변수 초기화를 위해 클래스 인스턴스 코드 부분이 한 번만 실행됩니다.

SIMULA 67이 데이터 추상화를 위해 기여한 점은 클래스 구조를 통해 데이터를 선언하는 것과 이를 다루는 프로시저를 구문적으로 캡슐화 했다는 것입니다. 즉, 슬라이드에 나온 것처럼 슬라이드의 정의에서 변수와 부프로그램을 클래스 내에 선언하는 것입니다.
정보 은폐 관점에서 보자면, SIMULA 67의 클래스에서 선언된 변수는 클래스 객체를 할당하는 다른 프로그램 단위에서 숨겨지지 않습니다. 즉, 클래스의 부프로그램에서 접근하거나, 아니면 이름을 통해 직접 접근할 수 있습니다. 따라서 정보 은폐가 완벽하게 제공되지 않는다는 단점이 있습니다.

다음은 Modula-2 언어에서의 추상 데이터 타입에 대해 알아보겠습니다. Modula-2는 추상 데이터 타입의 표현을 숨기는 기능을 포함한 데이터 추상화를 지원합니다.
Modula-2 언어에서 데이터 추상화 기능을 제공하는 프로그램 단위는 모듈(Module)입니다. 모듈은 다른 프로그램 단위에서 접근할 수 있는 타입, 객체 및 부프로그램의 정의를 모두 포함할 수 있습니다.
모듈의 정의에서는, 클라이언트 장치에서 부프로그램의 헤더뿐만 아니라 타입 및 객체의 최소한의 부분 사양을 볼 수 있습니다. 또한, 모듈의 인터페이스를 지정할 수 있습니다.
모듈의 구현에서는, 해당 정의 모듈에서 부분적으로만 정의된 모든 타입의 완전한 정의가 이루어집니다. 또한 해당 정의 모듈에 헤더가 나타나는 부프로그램의 전체적인 정의도 포함해야 합니다. 이러한 모듈은 별도로 컴파일이 가능합니다.

만약 모듈의 정의에서 표현이 포함되어 있다면, 그 타입은 투명(Transparent)하다고 하며, 그 표현을 가져오는 모듈에서는 숨겨지지 않습니다.
그러나 모듈의 정의에서 표현이 포함되어 있지 않고, 구현 모듈에 표현이 포함된다면 그 유형은 불투명(Opaque)하다고 합니다. 추상 데이터 타입은 당연히 불투명해야하지만, Modula-2 언어에서는 포인터 타입만 불투명할 수 있습니다.
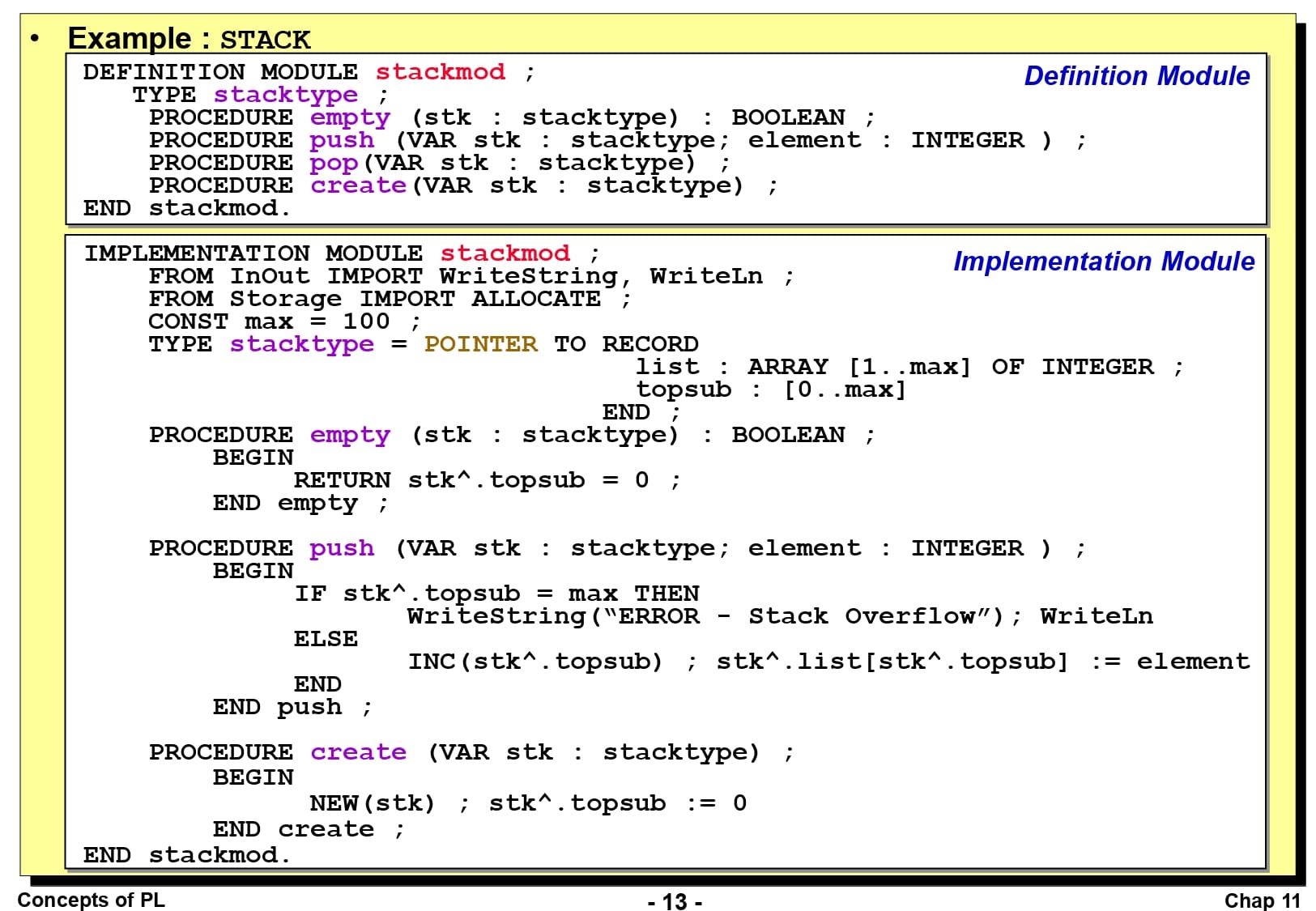
실제 Modula-2의 코드를 보고 이것이 무슨 의미인지 알아보겠습니다. 이것은 Modula-2 언어로 스택을 구현한 프로그램입니다. 스택 모듈의 이름은 stackmod로 정의되어 있습니다. 모듈은 정의 모듈(Definition Module)과 구현 모듈(Implementation Module)로 나뉘어 있는데, 정의 모듈에는 타입과 프로시저의 헤더가 선언되어 있고, 구현 모듈에 상세한 구현 내용이 작성되어 있습니다.

만약 다른 모듈에서 이전 슬라이드에서 정의한 stackmod 모듈을 사용하고 싶다면, FROM ~ IMPORT 명령어를 이용하여 stackmod 모듈의 프로시저를 하나하나 호출해줘야 합니다.
클라이언트에서 모듈의 프로시저를 호출할 때는 2가지 방법이 있습니다. 명시적으로 어떤 모듈의 프로시저인지 나타내는 방법과, 그냥 프로시저의 이름만을 호출하는 경우입니다. 만약 프로시저 이름의 중복이 없다면 그냥 프로시저의 이름만 호출해도 사용이 가능하지만, 만약 다른 모듈에서 같은 이름의 프로시저가 있다면 모듈의 이름을 반드시 명시해야 합니다.

다음으로 살펴볼 언어는 Ada입니다. Ada는 추상 데이터 타입을 완벽하게 지원하는 최초의 언어입니다.
Ada 언어의 캡슐화 구성 요소나 모듈은 패키지(Package)라고 부릅니다. 패키지는 명세 패키지(Specification Package)와 몸체 패키지(Body Package) 두 부분으로 구성되는데, 각각을 그냥 패키지라고 부르기도 합니다. 모든 패키지가 몸체 패키지를 갖고 있는 것은 아니고, 만약 패키지 앞에 body 로 시작하는 명령어를 입력하면 컴파일러는 이 패키지를 몸체 패키지로 인식합니다. 명세 패키지와 몸체 패키지는 서로 별도로 컴파일이 가능한데, 이 때는 반드시 명세 패키지를 먼저 컴파일해야 합니다. 또한 명세 패키지만 컴파일 된다면, 몸체 패키지를 컴파일하지 않아도 클라이언트 코드를 컴파일할 수 있습니다.
명세 패키지에는 두 개의 섹션이 있습니다. 한 섹션은 외부에서 볼 수 있게 완전히 공개되고, private로 정의된 섹션은 외부에서 볼 수 없기 감춰집니다. 이 때, private는 반드시 명세 패키지의 마지막 부분에 작성해야 합니다.
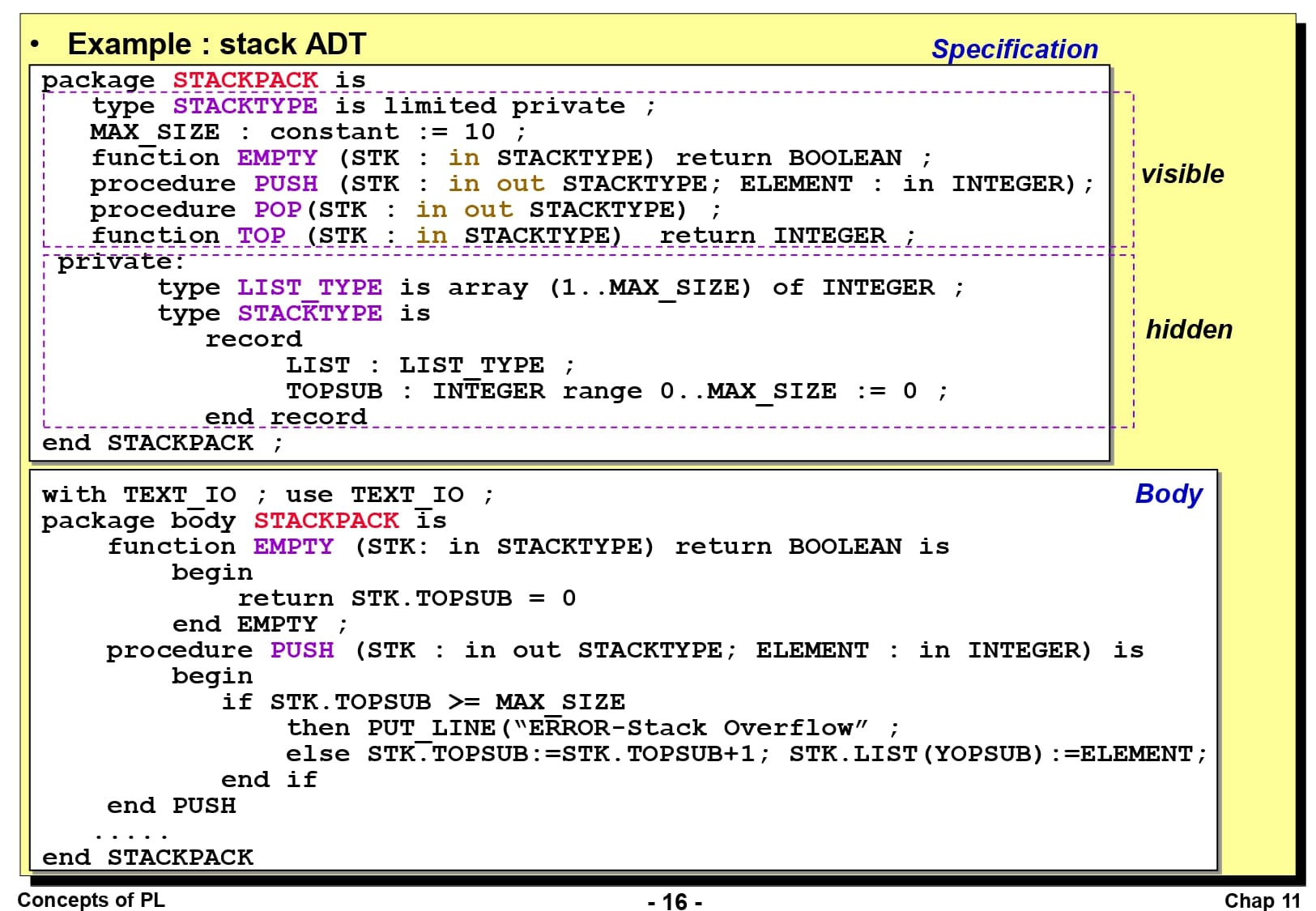
Modula-2에서 보여드렸던 스택 코드를 Ada 언어로 구현한 코드입니다. 이전과 어떠한 차이가 있는지 같이 알아보겠습니다. 먼저, Modula-2 언어에서는 보이는 부분과 보이지 않는 부분을 별도의 모듈을 사용해서 구현했으나, Ada 언어는 하나의 패키지에서 보이는 부분과 보이지 않는 부분이 모두 나타나 있습니다. 대신, 그 구분을 private를 이용하여 나타냈습니다.
패키지 첫 줄에는 limited private가 있습니다. 이것은 STACKTYPE 패키지가 제한된 전용 타입(Limited Private Type)이라는 의미로, 이러한 타입의 객체에서 내장된 연산이 없다는 의미입니다. 예를 들어서, 생성자와 같이 미리 정의되는 배정 연산이나 비교 연산 같은 것이 없다는 것입니다. 스택에서 이러한 연산은 거의 사용되지 않기 때문에 여기에서는 limited private가 사용되었습니다.
몸체 패키지에서는 스택의 각 함수와 프로시저가 구현되어 있습니다. 첫 줄에서 with / use 명령어가 사용되는데, with TEXT_IO은 텍스트 입출력을 위한 함수를 제공하는 외부 패키지를 볼 수 있게 만드는 것이고, use는 TEXT_IO를 참조할 때 명시적으로 참조하지 않게 만드는 역할을 합니다.

실제로 이 패키지를 사용하는 클라이언트에서는 마찬가지로 with / use 명령어를 이용하여 STACKPACK과 TEXT_IO를 가져옵니다. 나머지 코드의 부분은 직접 스택 패키지를 사용하는 예제를 나타낸 것이므로 별도의 설명이 필요하지 않을 것 같습니다.
데이터 추상화의 관점에서 Modula-2와 Ada 언어를 비교해보겠습니다. Modula-2 언어는 포인터로만 불투명 내보내기를 제한하였지만, Ada의 추상 데이터 타입은 그렇지 않기 때문에 더 유연하다는 장점이 있습니다. 그러나, Modula-2의 설계는 모듈의 요소를 선택적으로 가져올 수 있기 때문에 패키지의 일부만 필요한 경우에는 Ada 언어보다 낫다는 장점이 있습니다.

다음은 유명한 언어 중 하나인 C++ 언어의 추상 데이터 타입에 대해 알아보겠습니다. C++은 C 언어에서 객체 지향 프로그래밍을 지원하는 기능이 추가된 언어이며, 그렇기 때문에 당연히 데이터 추상화도 지원합니다.
C++의 클래스는 데이터 타입에 대한 템플릿이기 때문에, 여러 번 인스턴스화할 수 있습니다. 클래스에서 정의된 데이터는 데이터 멤버(또는 인스턴스 변수)라고 부르고, 클래스에서 정의된 함수는 멤버 함수(또는 메소드)라고 부릅니다. 데이터 멤버와 멤버 함수는 클래스와 인스턴스에 나타나는데, 클래스의 멤버는 클래스와 관련이 있고, 인스턴스 멤버는 클래스 인스턴스와 관련이 있습니다. 여기서는 클래스의 인스턴스 멤버만 고려하겠습니다.
클래스의 모든 인스턴스는 멤버 함수를 공유하지만, 각각의 인스턴스는 자신의 데이터 멤버를 갖습니다. 클래스 인스턴스는 객체라고도 불립니다.
클래스 인스턴스는 정적, 스택 동적, 힙 동적일 수 있습니다. 클래스 인스턴스가 만약 정적이나 스택 동적이라면 직접 참조할 수 있지만, 힙 동적이라면 포인터를 통해 참조됩니다. 정적이나 스택 동적인 경우는 객체 선언을 통해 생성되는 경우를 말하며, 힙 동적인 경우에는 new 연산자에 의해 생성되는 경우를 말합니다. 만약 클래스 인스턴스가 스택 동적일지라도, 클래스는 힙 동적 테이터를 참조하는 멤버 데이터를 포함할 수 있습니다.
클래스 멤버 함수는 두 가지 방법으로 정의될 수 있습니다. 클래스 정의에서 헤더만 작성하고 클래스 외부에서 몸체 부분을 정의할 수도 있고, 또는 헤더에서 완전히 모든 것을 구현하는 인라인 함수(Inlined Function)가 있습니다. 인라인 함수의 장점은 일반적인 부프로그램에서의 호출과 복귀 과정을 거치지 않는다는 장점이 있습니다. 대신 클래스 정의 인터페이스가 복잡해지기 때문에, 인라인 함수는 일반적으로 실행 시간 효율성이 매우 중요한 상황에서만 사용합니다.

C++ 클래스는 보이는 요소와 숨겨진 요소를 모두 포함할 수 있습니다. 이것은 접근 지정자를 표시하는 것으로 구별합니다. private 접근 지정자는 외부로부터 은폐되는 요소를 의미하며, public은 외부로부터 볼 수 있는 요소를 의미합니다. protected는 외부로부터는 은폐되지만, 상속받은 서브 클래스에는 보이는 요소를 의미합니다.
또한 C++ 언어에는 생성자(Constructor)와 소멸자(Destructor)가 존재합니다. 생성자는 객체 생성 프로세스에서 매개변수를 초기화하고 제공하는데 사용합니다. 생성자는 클래스 타입의 인스턴스가 생성될 때 묵시적으로 호출되며, 클래스와 동일한 이름을 갖습니다. 생성자는 중복으로 만들 수 있지만, 각각의 생성자는 매개변수가 달라야 합니다. 소멸자는 생성자와 마찬가지로 클래스 타입 인스턴스의 수명이 끝날 때 묵시적으로 호출됩니다. 생성자와 소멸자는 모두 반환 타입을 갖지 않고, return 명령어를 사용하지도 않습니다. 또한, 프로그래머가 명시적으로 생성자와 소멸자를 호출하는 것도 가능합니다.

이전에 나왔던 스택 예제를 C++의 클래스로 구현한 모습입니다. 먼저 Stack 클래스의 객체는 스택 동적이지만, 힙 동적 데이터를 참조하는 포인터 변수인 *stack_ptr을 포함합니다. Stack 클래스의 데이터 멤버 3개는 모두 private로 선언되어서 외부로부터 숨겨져 있습니다. 또한 Stack 클래스는 생성자, 소멸자, 그리고 4개의 멤버 함수를 가지고 있습니다. 이 예제에서는 모든 선언에 구현이 포함되어있기 때문에, 인라인 함수로써 취급됩니다. 현재 Stack 클래스는 생성자에서 항상 100개의 크기를 가지는 배열을 생성하지만, 동적인 크기를 갖는 배열로 변경하려면 생성자에 매개변수를 추가하여 그 크기만큼 배열을 생성하는 생성자로 변경할 수 있습니다.

이번에는 Java 언어에서의 추상 데이터 타입을 살펴보겠습니다. Jva에서의 추상 데이터 타입 지원은 C++ 언어와 매우 유사합니다. 그러나 C++ 언어와는 다음과 같은 여러 가지 차이점이 있습니다.
첫째로, Java의 모든 사용자 정의 데이터 타입은 클래스입니다. C++ 언어는 C 언어의 상위호환이기 때문에, 클래스가 아니라 함수와 같은 프로시저도 선언이 가능한 것과 대조적입니다. 또한, Java는 구조체(Structure)를 지원하지 않습니다. Java에서 모든 객체는 힙에서 할당되고, 참조 변수를 통해 접근할 수 있습니다. 게다가, Java 언어의 메소드 몸체는 반드시 헤더와 함께 나타나야 합니다. 따라서 Java의 추상 데이터 타입은 단일 구문 단위로 선언되고 정의됩니다.
또한 Java 언어에서는 쓰레기 수집기(Garbage Collector)가 있기 때문에 C++ 언어와 달리 소멸자가 없습니다.
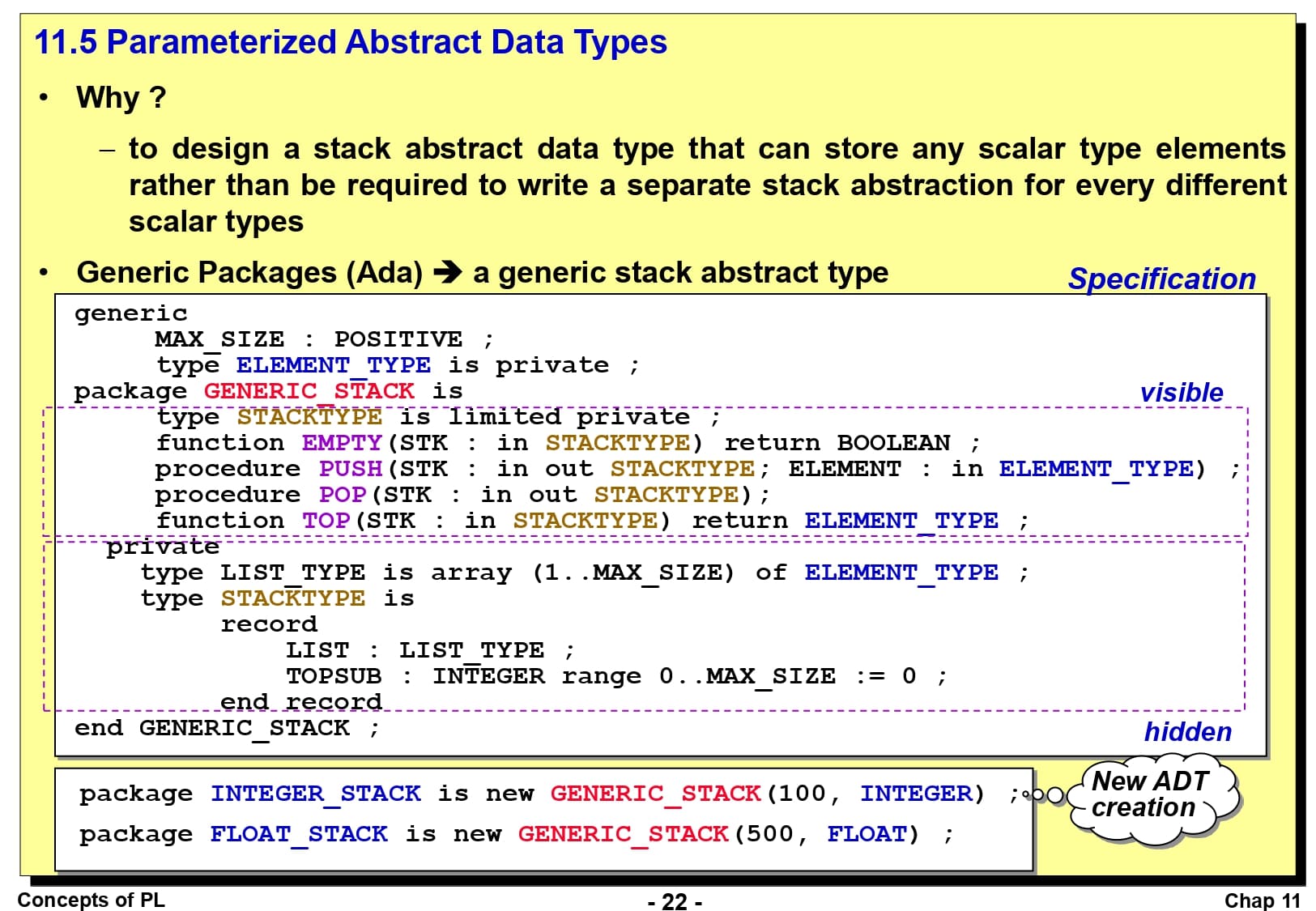
마지막으로 추상 데이터 타입을 매개변수화하는 것에 대해 알아보겠습니다. 이것은 때때로 매우 편리한데, 이전의 예제인 스택을 여러 개의 스칼라 데이터 타입에 사용할 필요가 있는 경우, 각각의 데이터 타입에 대해 별도의 스택 추상화를 작성할 필요가 없기 때문입니다. 만약 임의의 스칼라 타입 원소를 저장할 수 있는 하나의 스택 추상 데이터 타입을 설계할 수 있다면, 프로그램의 재사용을 통해 전체 코드의 길이를 압축할 수 있습니다.
슬라이드에 나온 코드는 Ada 언어에서의 제네릭 패키지(Generic Package)입니다. 이전에 나왔던 스택 코드를 다양한 스칼라 데이터 타입에 대해 사용할 수 있게 수정한 버전입니다. 주요한 점은 MAX_SIZE를 통해 스택의 크기를 조절할 수 있고, 데이터 타입이 ELEMENT_TYPE 으로 바뀌었다는 것입니다. 스택 객체를 생성하는 부분을 보면, 앞의 숫자를 통해 스택의 크기를 정의하고 뒷쪽의 자료형을 통해 원하는 자료형으로 생성하는 모습을 확인할 수 있습니다.
이러한 추상 데이터 타입 매개변수화는 정적 타입 언어만의 고려사항입니다. 왜냐하면 Ruby나 Python과 같은 동적 타입 언어에서는 이러한 매개변수화를 사용하지 않고도 임의의 스칼라 데이터를 저장할 수 있기 때문입니다.
11장의 내용은 여기까지입니다. 읽어주셔서 감사합니다!
Leave a comment