
Support for Object-Oriented Programming

드디어 프로그래밍 언어론의 마지막 장입니다. 이 장은 객체 지향 프로그래밍에 대해 상세하게 알아보겠습니다. 순서대로, 객체 지향 프로그래밍의 기본 개념, 객체 지향 프로그래밍 언어의 사례 연구로써 몇 가지 예시와 함께 C++의 대한 소개, 그리고 객체 지향 프로그래밍의 장점과 단점에 대해 다루어보겠습니다.

이번 장의 순서는 다음과 같습니다.
- 서론
- 객체 지향 프로그래밍에 대한 기본 개념들
- 추상 데이터 타입
- 객체와 메시지 전송
- 클래스와 인스턴스
- (다중) 상속
- 동적 바인딩과 다형성
- 객체 지향 프로그래밍 언어
- 분류
- C++ 언어를 통한 사례 연구
- 분석
- 정리
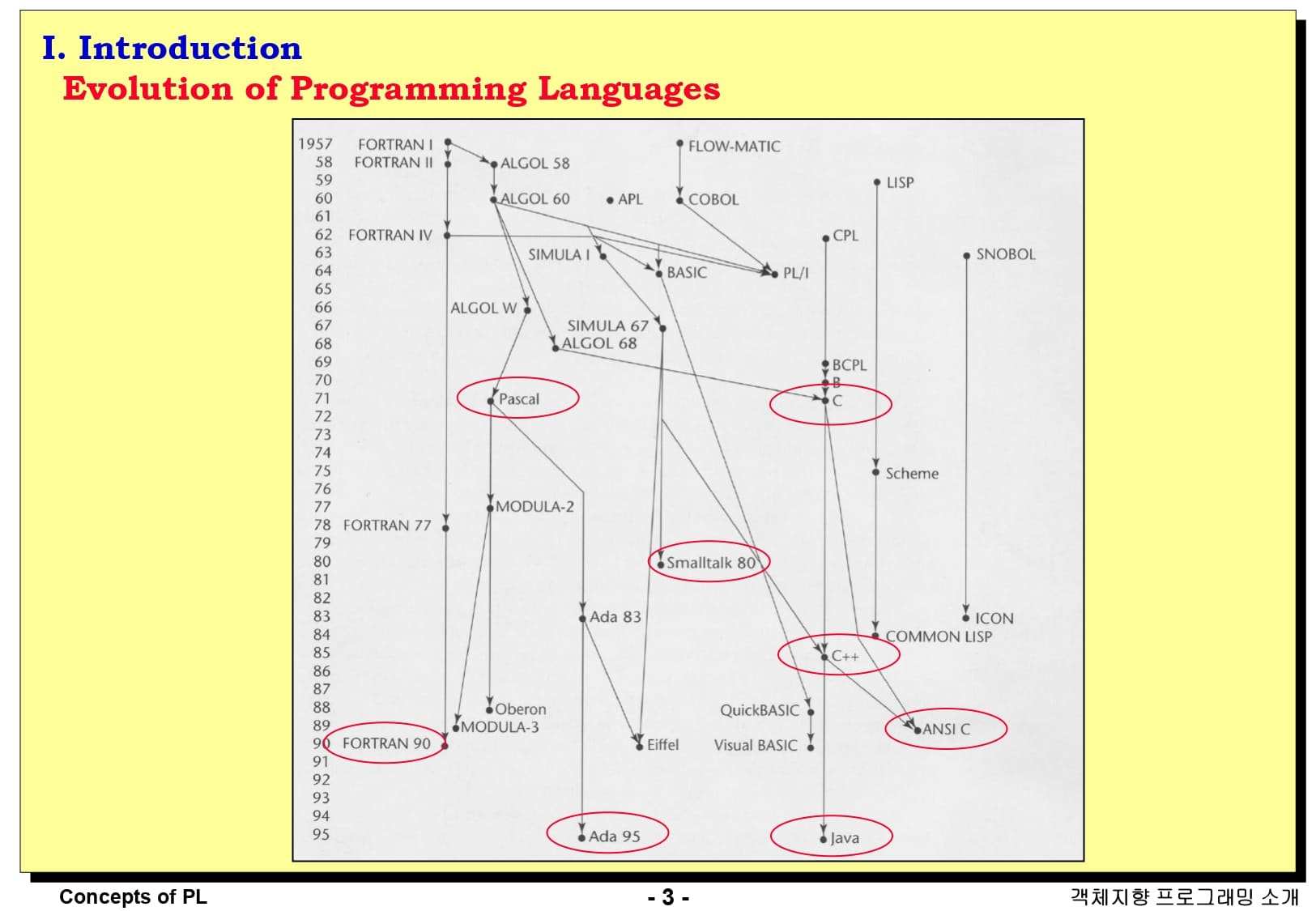
이 그림은 2장 프로그래밍 언어의 발전사에 나왔던 그림입니다. 이 중에서 C++, Java, Ada 95는 객체 지향 프로그래밍을 완벽하게 지원하는 언어이고, 그 외의 언어들은 완벽한 객체 지향 프로그래밍을 지원하지는 않지만 영향을 미친 언어들입니다.

2장에서 배웠던 프로그래밍 언어의 패러다임을 다시 정리하겠습니다. 참고로 시간에 따라 정리된 것이 아닙니다!
-
블록 구조(절차 지향 프로그래밍) : 프로그램은 블록과 프로시저의 중첩된 집합으로 구성되어 있습니다. 1960년대와 1970년대의 주요 패러다임으로 ALGOL, Pascal, PL/I, Ada, Modula 등의 언어가 이 패러다임의 영향을 받았습니다.
-
객체 기반(객체 지향 프로그래밍) : 프로그램은 상호작용하는 객체의 집합으로 구성되어 있습니다. 주로 1970년대와 1980년대 유행하였으며, Simula 67, Smalltalk, C++ 등의 언어가 이 패러다임의 영향을 받았습니다.
-
동시 수행(분산 프로그래밍 패러다임) : 여러 개의 부프로그램이 동시적으로 수행되는 것을 중시합니다. 프로그램은 다중 스레드, 동히과, 통신 등의 기능을 가지고 있습니다. Fork-join, Ada-CSP, Linda 등의 언어가 이 패러다임의 영향을 받았습니다.
-
함수형 프로그래밍 패러다임 : 프로그램은 함수 정의의 집합으로 구성되어 있습니다. LISP, ML, Miranda, Haskel 등의 언어가 이 패러다임의 영향을 받았습니다.
-
논리 프로그래밍 패러다임 : 프로그램은 정리(Theorem)라는 해결 원리의 집합으로 구성되어 있습니다. 명확한 의미 체계와, 많은 암시적인 병렬 처리가 특징입니다. Prolog, Parlog, GHC 등의 언어가 이 패러다임의 영향을 받았습니다.

그렇다면 객체 지향 프로그래밍을 왜 사용하는 것일까요? 다음과 같은 이유가 있습니다.
- 현실 세계의 문제를 자연스럽게 모델링할 수 있음 (여러 자치적인 요소, 시뮬레이션 시스템)
- 모듈성 (데이터와 프로시저로 구분됨, 문제를 세부 문제로 나눌 수 있음, 정보 은닉)
- 소프트웨어의 재사용성 증가 (상속, 유용한 클래스 라이브러리)
- 병행 (각 객체를 병렬로 실행 가능)
- 단지 새로운 프로그래밍 패러다임이라서!

객체 지향 프로그래밍이란 개념은 SIMULA 67에서 처음 시작되었습니다. 그러나 완전한 객체 지향 프로그래밍은 1980년 Smalltalk가 만들어지고 나서야 개발되었습니다. 그 때 정립된 객체 지향 프로그래밍은 프로그램이 객체들의 협동적인 집합으로 구성된 구현 방법으로, 각각의 객체는 어떤 클래스의 인스턴스를 나타내고, 그 클래스는 모두 상속 관계를 통해 결합되는 클래스 계층 구조의 구성원으로 정의됩니다.
객체 지향 프로그래밍의 패러다임은,
- 어떤 클래스를 원하는지 결정하기
- 각각의 클래스에 대해 전체 동작의 집합을 제공하기
- 상속을 사용하여 명시적으로 공통점을 만들기
등등이 있습니다.

추상 데이터 타입(Abstract Data Type)은 11장에서도 다루었지만, 캡슐화와 정보 은닉을 모두 지원하는 데이터 구조입니다.
데이터와 이것을 조작하는 코드가 함께 정의되고, 각각의 데이터는 연관된 코드와 분리되거나 별도로 접근할 수 없는 것이 캡슐화입니다. 그리고 데이터는 코드 내에 캡슐화되고, 지역화된 프로시저의 집합만 데이터를 직접 조작할 수 있습니다. 캡슐화는 소프트웨어 구성 요소 간의 상호 의존성을 줄여, 시스템의 신뢰성과 수정 가능성을 보장하기 때문에 중요합니다.
정보 은닉은 프로그램의 구현 및 내부 표현을 고려하면 안 된다는 원칙입니다. 캡슐화는 결국 방법(How)보다 무엇(What)을 강조하는 것입니다. 캡슐화는 프로시저 추상화(서브루틴)과 데이터 추상화(추상 데이터 타입)으로 구분할 수 있습니다.
추상화는 결국 사람들이 자신이 뭘 하고 있는지 생각하는 데 도움이 되고, 캡슐화는 제한된 노력으로 프로그램의 변경을 신뢰할 수 있게 만듭니다.
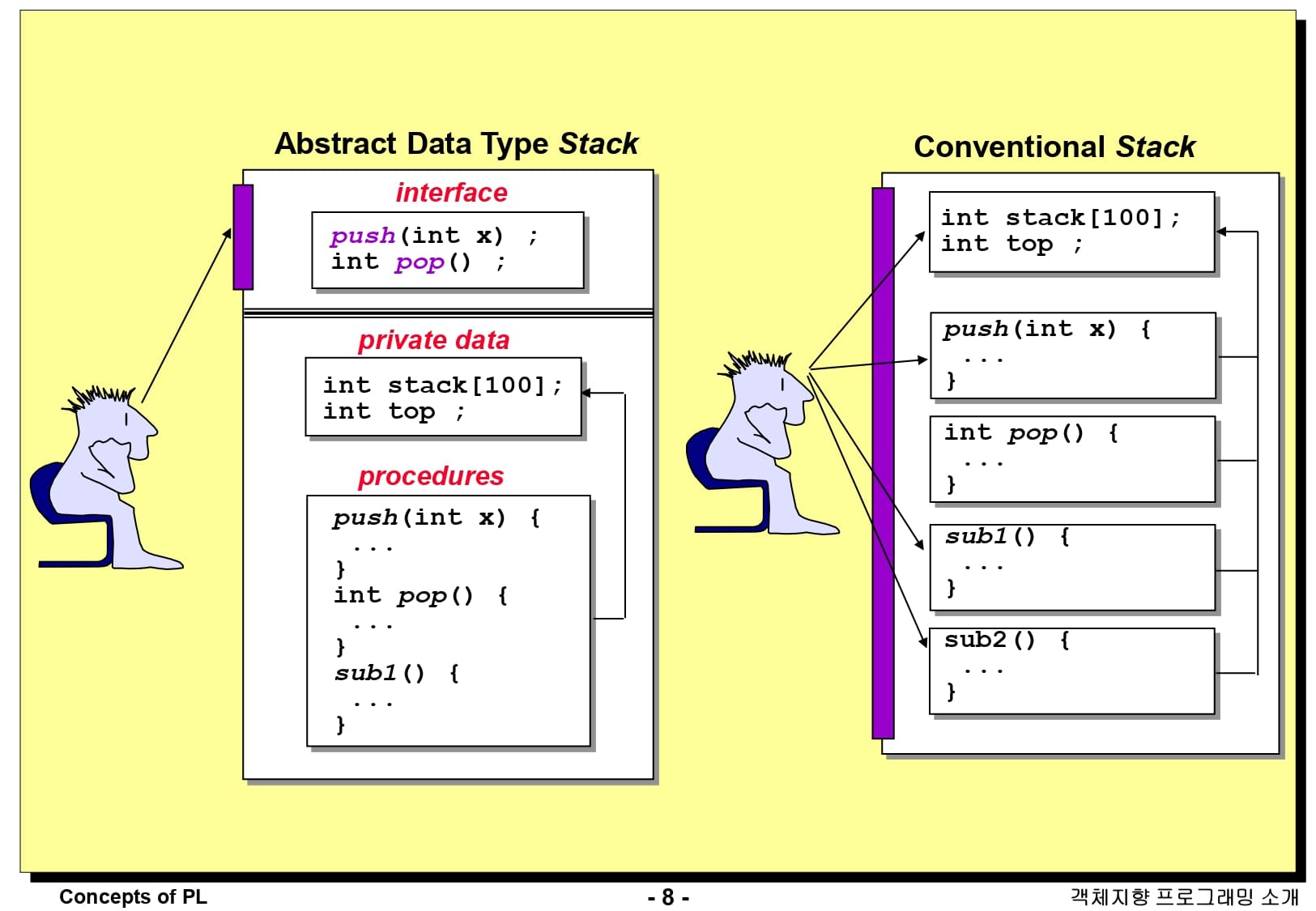
가령 스택을 C 언어와 같은 일반적인 방법으로 구현한 것과, 추상 데이터 타입으로 구현한 것을 비교해봅시다. 오른쪽 같은 경우에는 프로그래머가 스택을 사용하기 위해서 스택이 정의된 배열인 stack과 가장 위를 나타내는 변수인 top을 파악해야 합니다. 또한, 스택의 연산을 수행하기 위해 push, pop, sub1, sub2… 등의 프로시저를 모두 파악하고 있어야 합니다. 그러나 왼쪽과 같이 추상 데이터 타입으로 스택을 구현한다면, 스택의 인터페이스인 push와 pop에 대해서만 신경을 쓰면 되고, 스택을 구현하는 데이터인 stack, top이나 프로시저에 대해 신경을 쓸 필요가 없습니다.

다음은 객체와 메시지 전송에 대해 알아보겠습니다. 객체(Object)란, 사적 데이터(Private data)와 메소드를 가진 엔티티(Entity)입니다. 객체는 상태라는 인스턴스 변수와 메소드라는 일련의 작업으로 구성되어 있습니다.
데이터는 객체로부터 얻을 수 있는데, 객체에게 메시지를 보냄으로써 간접적으로 프로시저를 호출하여 얻습니다. 객체 또한 정적 바인딩과 동적 바인딩으로 구분할 수 있습니다. 객체 지향 프로그래밍의 모든 행동은 객체 간의 메시지 전송에서 비롯되며, 메시지의 선택기는 작업의 종류를 지정합니다.
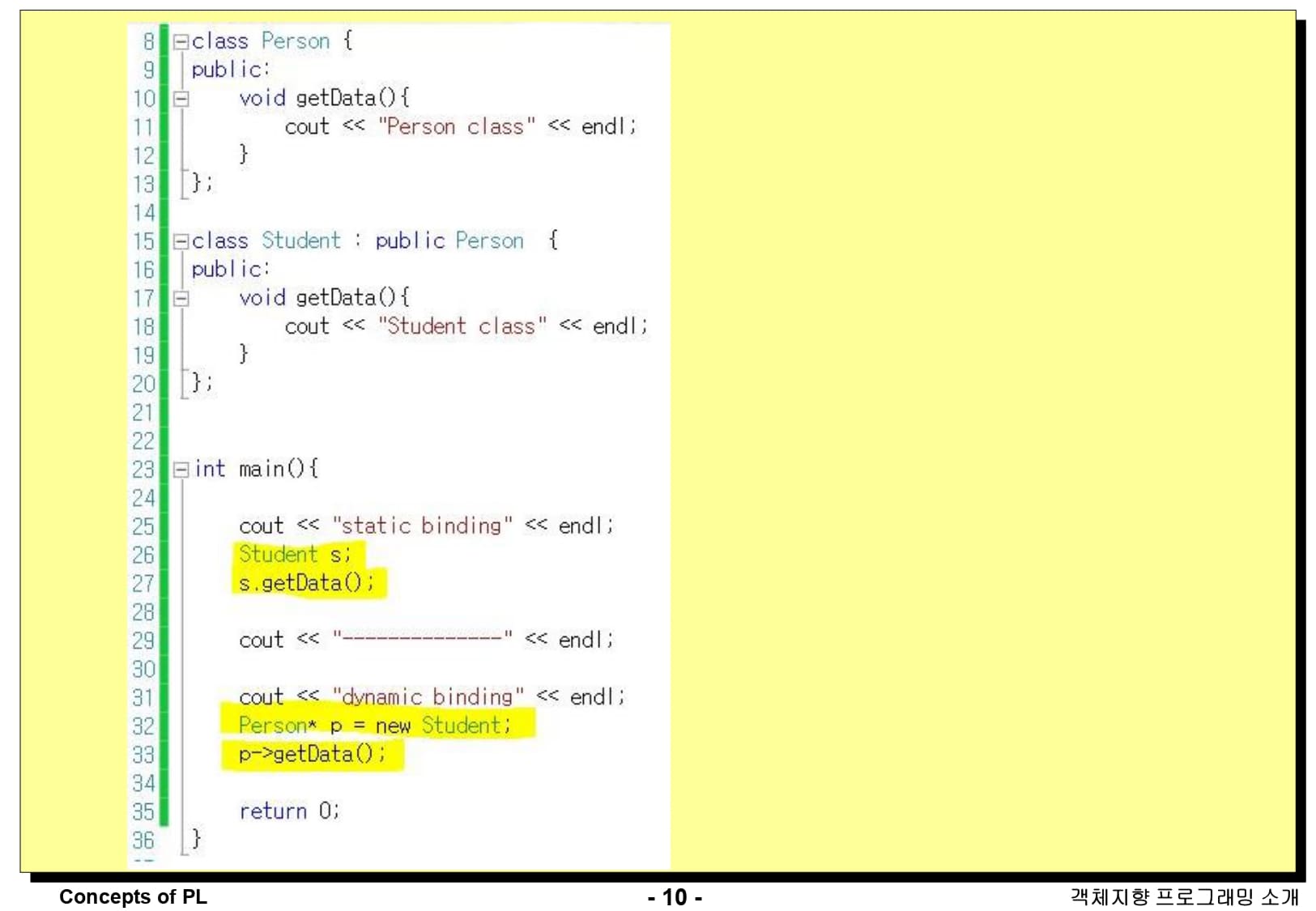
간단한 C++ 코드를 보면서 지난 슬라이드에서 배운 내용을 확인해보겠습니다. 먼저 Person이라는 클래스가 있고, Student 클래스는 Person 클래스로부터 상속을 받았습니다. 두 클래스 모두 사적 데이터(Private data)는 없고, getData()라는 메소드 하나씩만 보유하고 있습니다.
main() 함수를 확인해보면, Student 클래스의 객체인 s는 정적으로 메모리에 바인딩 되었습니다. 또한 s.getData()라는 메시지를 통해 s의 메소드를 호출하고 있습니다. Person 클래스의 객체인 p는 포인터를 이용하여 동적으로 메모리에 바인딩하고 있습니다. 이 때, Person 클래스의 객체에 Student의 객체를 할당하지만, Student가 Person의 서브 클래스이기 때문에 이러한 문법은 허용됩니다. p는 포인터 객체이기 때문에 p에서 getData()를 호출할 때는 ->를 이용하여 호출합니다.
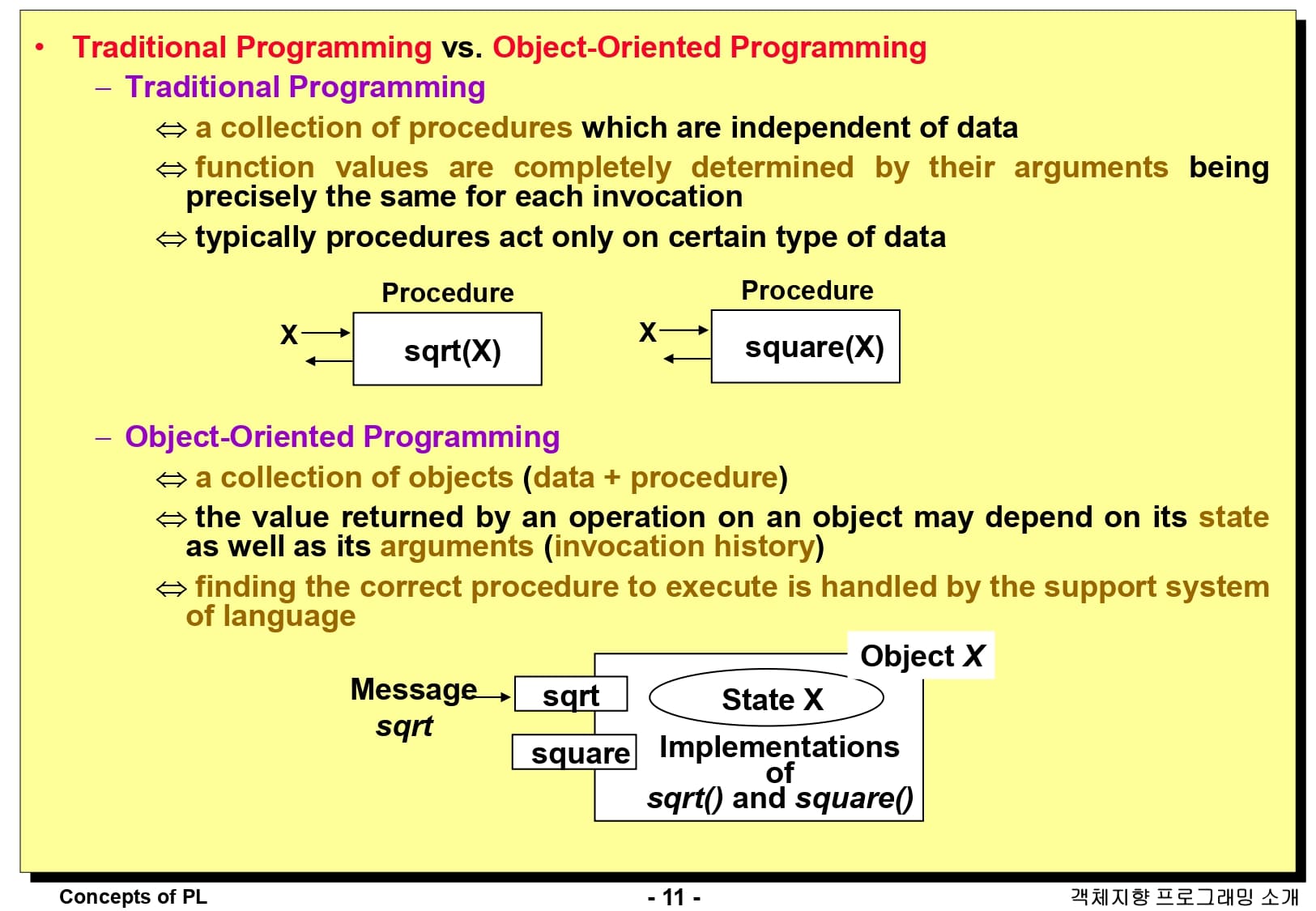
이번에는 전통적인 프로그래밍과 객체 지향 프로그래밍을 비교해보겠습니다.
먼저 전통적인 프로그래밍은, 데이터와 독립적인 프로시저에 의해 구성되어 있습니다. 함수의 값은 각각의 호출에 대해 정확한 인수를 가져야만 완전히 결정됩니다. 또한, 일반적으로 프로시저는 특정 타입의 데이터에만 적용됩니다.
그에 반해 객체 지향 프로그래밍은 데이터와 프로시저의 묶음인 객체로 구성되어 있습니다. 객체에 대한 연산이 반환되는 값은 상태와 인수, 그리고 호출 기록에 따라 달라질 수 있습니다. 실행할 올바른 프로시저를 찾는 것은 언어 지원 시스템에서 처리됩니다.

객체 지향 언어에서의 추상 데이터 타입은 일반적으로 클래스(Class)라고 불립니다. 클래스는 new나 create와 같은 명령을 통해 객체를 만들 수 있는 템플릿으로써, 구조(인스턴스 변스), 동작(메소드), 그리고 상속(부모)의 명세와 같은 것들을 포함합니다. 객체는 인스턴스화를 통해 클래스에서 생성되는데, 특정 클래스의 객체를 해당 클래스의 인스턴스라고 합니다.
클래스는 두 가지 종류의 변수를 갖고 있는데, 클래스의 모든 인스턴스에서 값을 공유하는 클래스 변수와 각각의 객체에 별도로 공간이 할당되는 인스턴스 변수가 있습니다. 또한 클래스가 객체인 경우, 클래스에는 메타 클래스라는 클래스가 있어야 합니다. 대표적으로 Python에서는 클래스 자체가 객체가 될 수 있는데, type이라는 명령어를 이용하여 메타 클래스를 만들 수 있습니다.
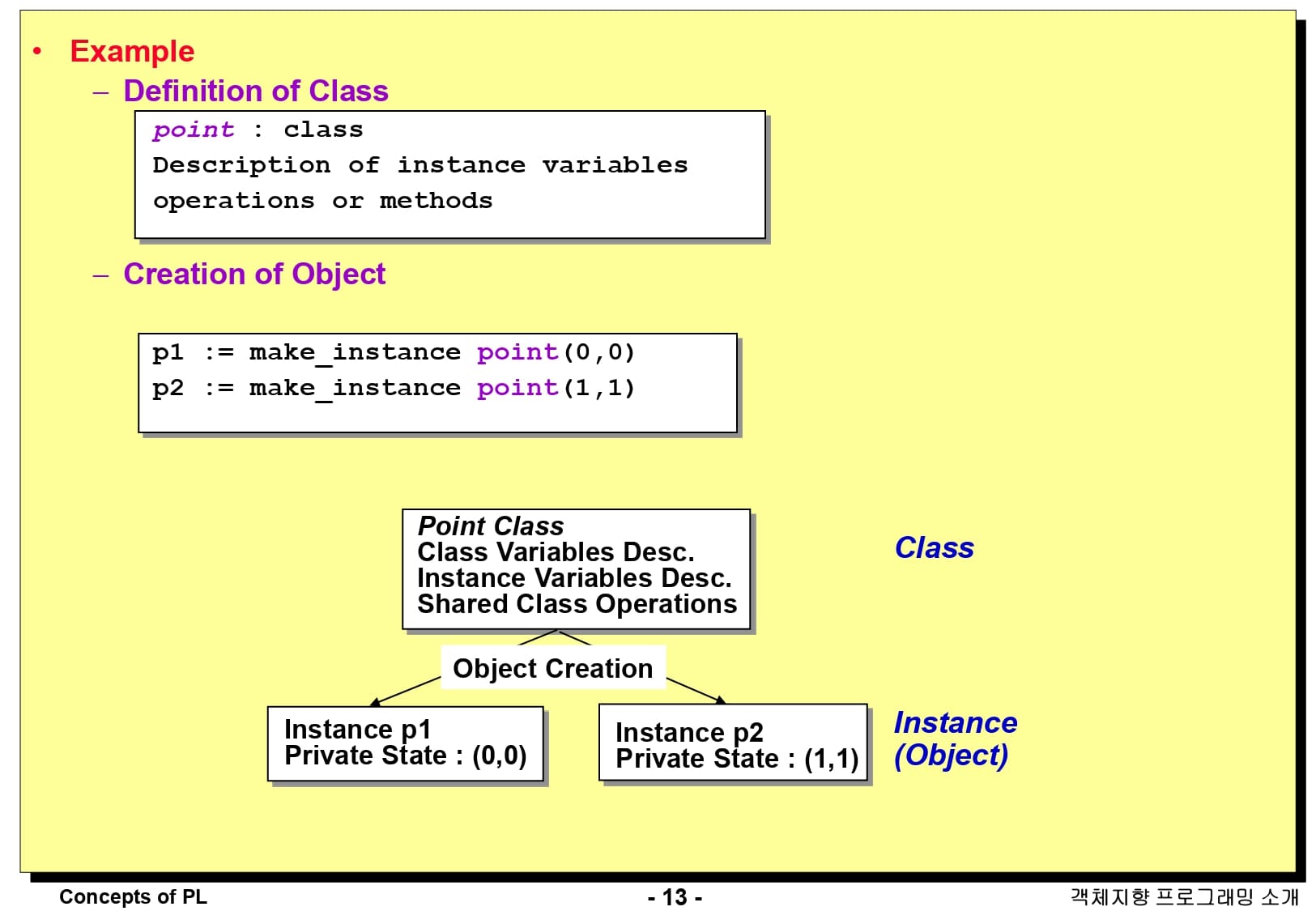
이 슬라이드에서는 클래스 구성의 예시를 나타내고 있습니다. point라는 클래스에서 인스턴스 변수와 메소드를 정의합니다. 그 후, 이 클래스를 이용한 객체를 생성하는 것은 p1과 p2 처럼 객체 생성 명령어를 사용하여 point 클래스의 객체를 생성합니다.

한 클래스가 다른 클래스의 상위 클래스인 클래스 간의 관계를 상속(Inheritance)이라고 합니다. 상속은 객체 지향 프로그래밍에서 소프트웨어 재사용을 지원합니다. 기반 클래스에서 상태 구조와 명령을 상속하는 기능을 통해, 프로그래머는 기존 객체의 요소 뿐만이 아니라, 기반 클래스의 구성 요소를 수정하고, 추가하여 새로운 객체를 정의할 수 있습니다. 그로 인해 기반 클래스를 토대로 새로운 문제에 맞게 프로그램 조직화 및 전문화가 가능해집니다.
상속의 구조를 예시로 들면 슬라이드와 같습니다. 포유류라는 기반 클래스를 상속받아 사람과 코끼리는 하위 클래스를 새로 정의하였습니다. 이 들은 분명 다른 클래스이지만 포유류의 특성을 모두 갖고 있습니다. 또한 사람의 하위 클래스로써 학생과 배우라는 직업을 기준으로 분류가 가능하며, 이를 토대로 철수, 영희와 같은 객체를 생성할 수 있습니다.
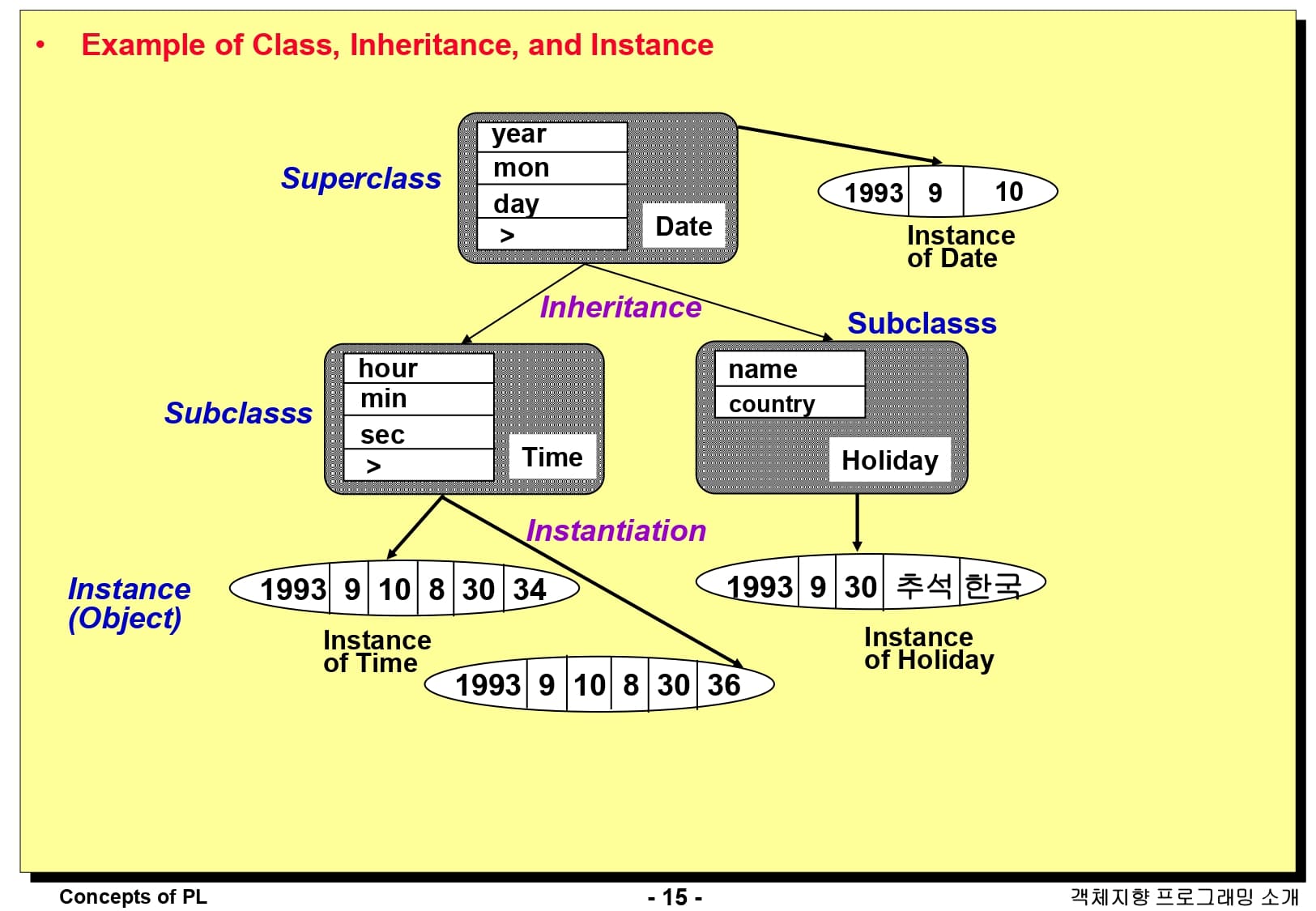
구체적으로 상속의 예시를 들어보겠습니다. 먼저 기반 클래스는 year, mon, day라는 인스턴스 변수를 가지고 있는 Date라는 클래스입니다. 이 클래스의 객체는 1993년 9월 10일과 같이 날짜를 표현할 수 있습니다. Date 클래스를 상속받아 Time과 Holiday라는 서브 클래스가 정의되었습니다. Time 클래스에서는 hour, min, sec라는 인스턴스 변수가 새로 정의되어, 기반 클래스가 가지고 있던 인스턴스 변수를 포함해 총 6개의 인스턴스 변수를 갖게 되었습니다. 이로 인해 날짜와 시간을 함께 표시할 수 있는 클래스로 정의되었습니다.
Holiday 클래스는 name과 country라는 새로운 인스턴스 변수가 정의되었습니다. 이를 토대로, 기반 클래스에서 상속받은 날짜에 국가와 명절 이름을 같이 표기할 수 있는 클래스가 되었습니다.

객체 지향 프로그래밍과 관련된 개념을 보여주는 데이터 구조입니다. 클래스에서는 인스턴스 변수의 개수, 이름 등과 같은 다양한 내용을 저장하고 있습니다. 이 중 메소드 사전(Method Dictionary)라는 것이 있는데, 만약 현재 클래스에서 정의된 메소드라면 이 메소드 사전을 통해 접근하게 됩니다. 만약 기반 클래스에서 정의된 부분이라면 기반 클래스의 메소드를 참조하게 됩니다.

클래스는 기반 클래스로부터 인스턴스 변수와 메소드를 상속받습니다. 상속받은 클래스를 주어진 문제에 전문화하기 위해서는 새로운 인스턴스 변수와 새로운 메소드를 정의하는 방법이 있습니다. 또는, 클래스의 변수나 메소드를 재정의할 수도 있습니다. 만약 여러 단계를 걸쳐 상속을 받았다면, 메소드를 호출할 때 어디서 정의된 메소드를 사용할 것인지를 결정해야 합니다. 일반적으로는 가장 가까이 있는 기반 클래스의 메소드를 사용하지만, 때에 따라 다른 메소드를 사용할 수도 있습니다.
상속 구조는 계측정 상속, 위임(Deligation)에 의한 상속, 그리고 다중 상속이 있습니다. 계층적 상속은 클래스가 단일 기반 클래스에서만 상속받는 것을 말합니다. 가장 널리 사용되는 상속으로써 Smalltalk에서 제안된 방법입니다. 간단하고 효율적이지만, 표현력이 제한적이라는 단점이 있습니다.
위임에 의한 상속은 각각의 객체가 처리할 메시지를 처리할 객체를 직접 선택하는 것입니다. 예를 들어, A 클래스에서 create()라는 메소드를 호출하는데, 이 메소드는 다른 클래스에서 정의된 메소드입니다. 이렇게 보면 일반적인 상속과 무엇이 다른가 싶겠지만, 직접적으로 “is-a” 관계가 아닌 경우(ex. 이전 슬라이드의 포유류 - 사람) 위임을 사용하는 것이 바람직합니다. 즉, 두 클래스 간의 종속성을 확립할 필요가 없거나, 그렇게 하면 문제가 생길 경우 위임을 사용한다고 보시면 됩니다.
마지막으로 다중 상속은, 클래스가 둘 이상의 기반 클래스로부터 상속을 받는 것을 말합니다.
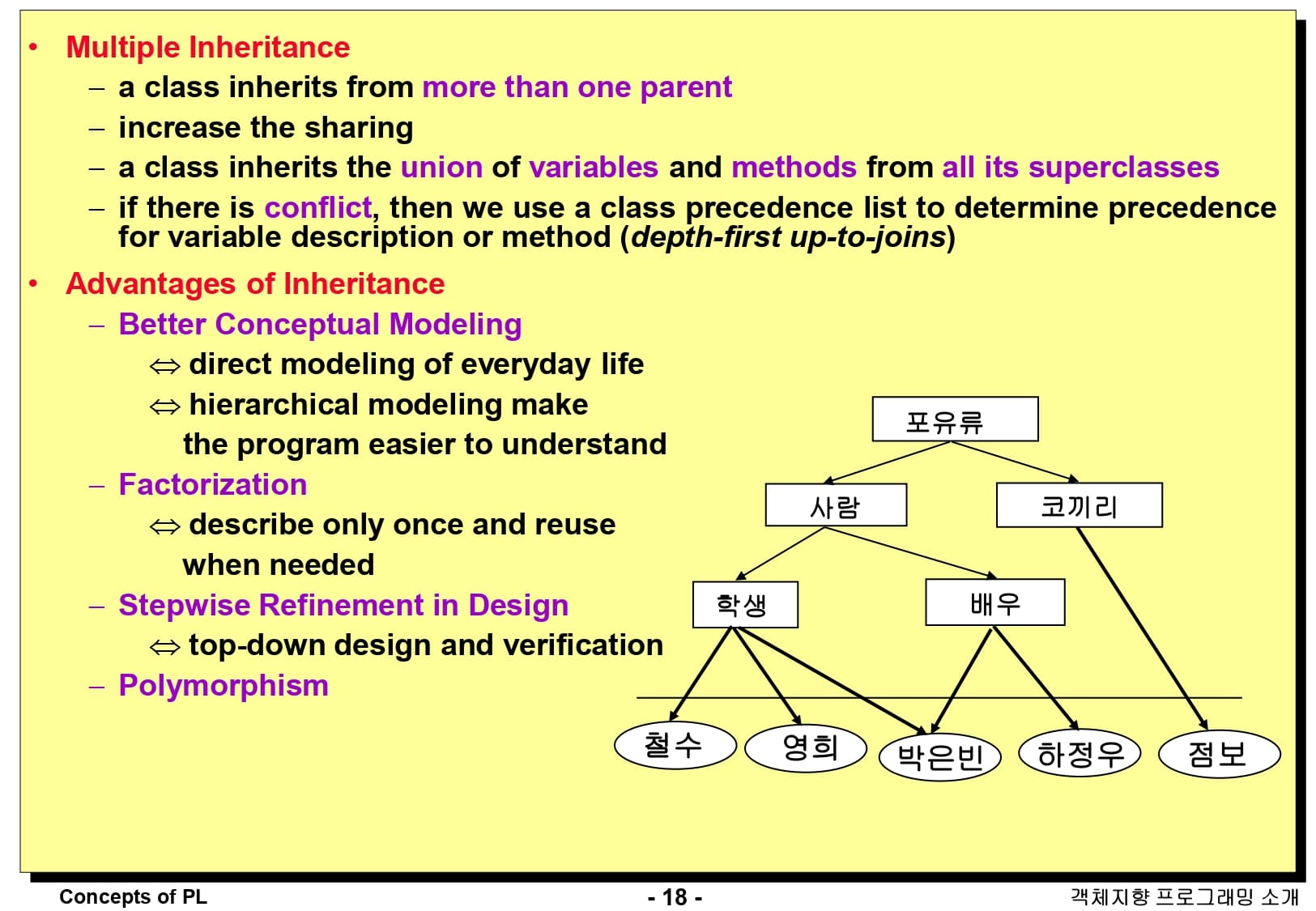
다중 상속에서는 클래스가 모든 기반 클래스로부터 변수와 메소드를 상속받습니다. 만약 상속받은 변수나 메소드에서 충돌이 있는 경우, 클래스 우선 순위 목록을 이용하여 상속의 우선 순위를 결정합니다. 일반적으로 깊이가 더 깊은 클래스를 우선적으로 상속받습니다. (Depth-first-up-to-join)
상속의 장점으로는 더 나은 개념을 모델링할 수 있다는 것입니다. 오른쪽 그림과 같이 일상적인 것을 직접 모델링할 수 있고, 계층적 모델링을 통해 프로그램을 더 쉽게 이해할 수 있습니다.
Factorization이라는 단어는 번역하기 참 애매한 단어인데, 공학에서 사용할 때는 보통 인수분해로 해석합니다. 다만 뒤에 나온 설명하고 뭔가 어울리지 않아서 애매하네요. 일단 여기에서는 한 번만 기술하고 필요할 때 재사용하는 장점으로 설명되어 있습니다.
다음으로는 디자인의 단계적인 개선을 통해 하향식 설계 및 검증에 유용하다는 장점이 있습니다. 마지막으로, 상속은 객체 지향 프로그래밍에서 다형성을 지원하도록 도와줍니다.
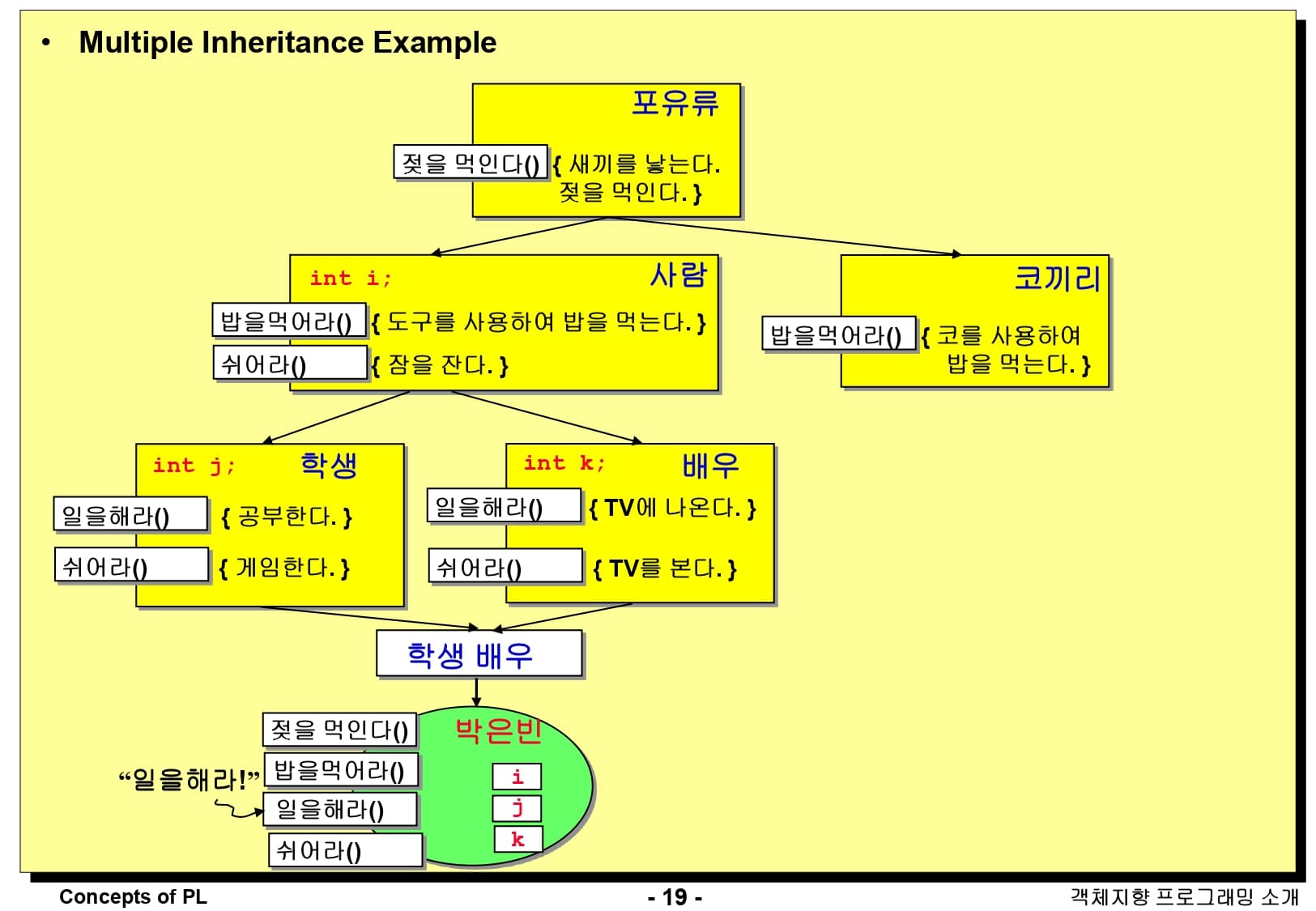
다중 상속의 예시는 다음과 같습니다. 학생과 배우라는 클래스는 사람이라는 기반 클래스로부터 파생된 클래스입니다. 그런데 학생 클래스는 일을 해라() 라는 메소드가 공부한다고 구현되어 있고, 배우 클래스의 일을해라() 라는 메소드는 TV에 나온다라고 구현이 되어 있습니다. 학생 배우라는 클래스는 학생과 배우로부터 상속받은 클래스입니다. 이 때, 일을해라()라는 메소드는 학생 클래스와 배우 클래스에 모두 존재하는 메소드입니다. 그렇다면 학생 배우 클래스의 인스턴스 객체인 박은빈에서 일을해라()라는 메소드는 어떤 행동을 해야하는가?라는 문제가 발생합니다. 이러한 문제를 죽음의 다이아몬드(Deadly Diamond)라고 하며, C++는 다중 상속을 지원하기 때문에 이러한 문제가 발생하지만, Java는 다중 상속을 지원하지 않기 때문에 이러한 문제가 발생하지 않습니다.

객체 지향 프로그래밍 언어에서는 메시지를 메소드 정의에 언제 바인딩하는지에 따라 정적 메시지 바인딩(Static Message Binding)과 동적 메시지 바인딩(Dynamic Message Binding)으로 나눌 수 있습니다.
정적 메시지 바인딩은 객체의 특정 메소드에 대한 메시지 바인딩이 컴파일 타임에 발생하는 것을 말합니다. 이것은 정적 유형 언어에서 사용하는 바인딩 방식입니다. 반대로 동적 메시지 바인딩은 특정 메소드에 대한 메시지 바인딩이 실행 시간에 발생하는 것을 말합니다. 이것은 다형성을 지원하는 강력한 메카니즘으로, 타입이 지정되지 않는 언어에서 사용됩니다.
이것이 어떤 차이가 있는지는 슬라이드 아래쪽에 나와있습니다. 동적 메시지 바인딩의 경우에는 draw라는 메시지가 호출되었을 때, 이것이 어느 클래스 객체인지에 따라 어떤 메소드에 바인딩될지가 결정됩니다. 그러나 정적 메시지 바인딩의 경우에는 클래스가 shape 하나만 있고, 그 안에서 type에 따라 어떤 기능을 수행할지 달라지는 형태입니다.
동적 바인딩이 정작 바인딩보다 우수한 점은, 소프트웨어 시스템이 개발과 유지보수 기간 동안 쉽게 확장될 수 있다는 것입니다.

객체 지향 프로그래밍에서 다형성(Polymorphism)이란 둘 이상의 타입, 또는 클래스에서 명령을 수행하는 능력을 말합니다. 다형성은 애드 혹 다형성(Ad hoc Polymorphism)과 유니버셜 타형성(Universal Polymorphism)으로 나뉩니다. 애드 혹 다형성은 강제 변환(Coercion)과 연산자 오버로딩(Operator Overloading)으로 구현됩니다. 유니버셜 다형성은 매개변수 다형성(Parametric Polymorphism)과 포함 다형성(Inclusion Polymorphism)으로 구현됩니다. 각각의 내용을 정리하면 다음과 같습니다.
- 강제 변환 : 연산자나 문맥을 통해 피연산자의 타입을 변경시키는 것
- 연산자 오버로딩 : 피연산자의 타입에 맞춰 같은 연산 기호가 다양한 의미에 대입되는 것
- 매개변수 다형성 : 클래스의 인스턴스 변수나 메소드의 매개변수 타입을 임의의 타입이 아니라 상황에 따라 다양한 타입으로 선언하는 것
- 포함 다형성 : 메시지가 동일하더라도 수신한 객체의 타입에 따라 실제로 수행하는 명령이 달라지는 것
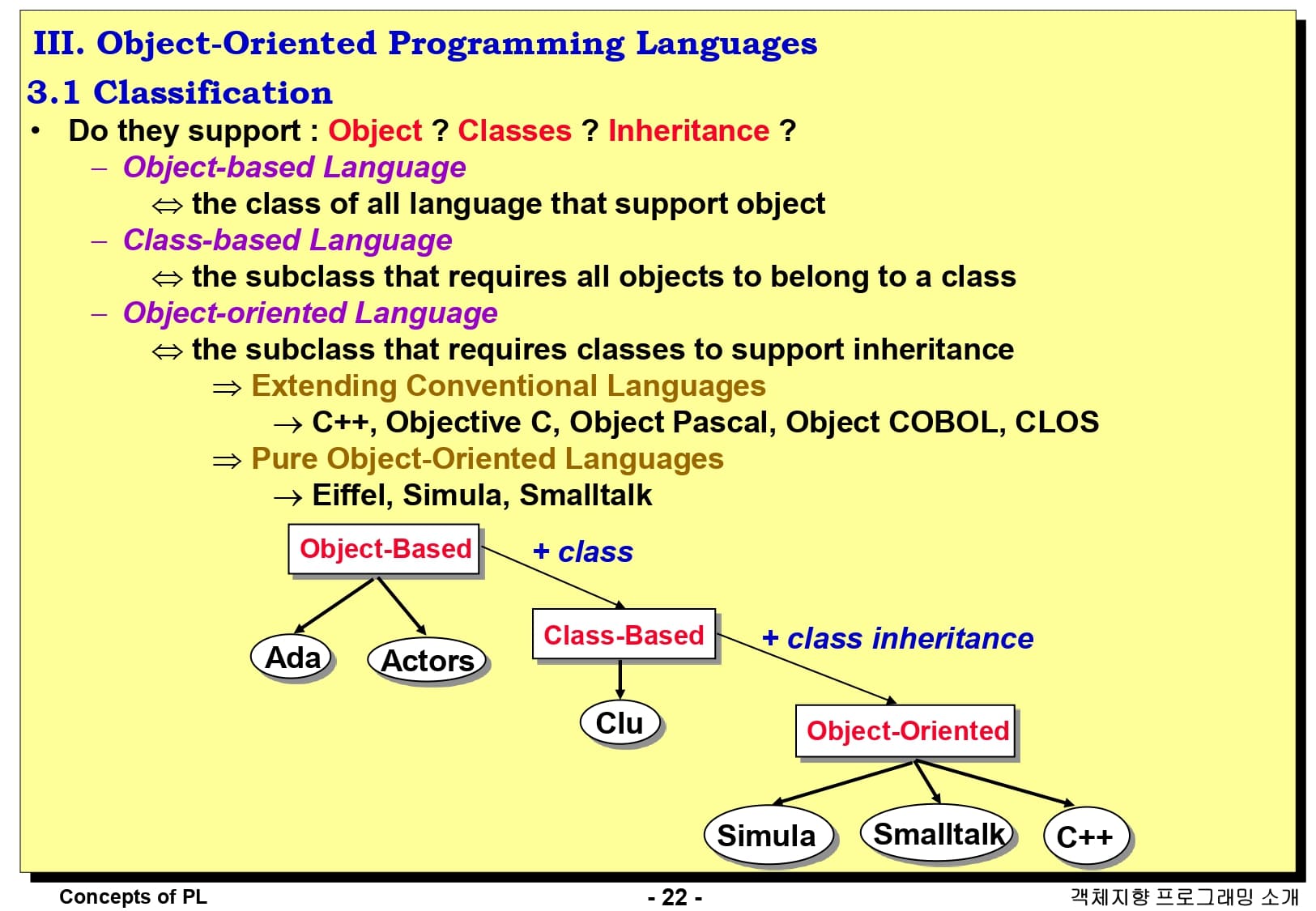
객체 지향 프로그래밍 언어는 다음과 같이 3가지 분류로 나눌 수 있습니다.
- 객체 기반 언어(Object-based Language) : 객체를 지원하는 모든 언어의 클래스
- 클래스 기반 언어(Class-based Language) : 모든 객체가 클래스에 속하도록 요구하는 하위 클래스
- 객체 지향 언어(Object-oriented Language) : 상속을 지원하기 위해 클래스가 필요한 하위 클래스
객체 지향 프로그래밍 언어 중 기존 언어를 확장해 만든 언어는 C++, Objective C, Object Pascal, Object COBOL, CLOS 등이 있고, 처음부터 순수 객체 지향 언어로 디자인된 언어는 Eiffel, Simula, Smalltalk 등이 있습니다.

이 그림은 객체 지향 언어와 관련된 언어의 가계도를 나타낸 것입니다. 객체 지향 언어는 파란색으로 표시되어 있고, 객체 기반 언어는 녹색 문의로 표시가 되어 있습니다. 그 외의 언어는 객체 기반 언어나 객체 지향 언어는 아니지만, 그러한 언어들에게 영향을 준 언어들입니다.

객체 지향 언어에 대한 사례 연구로써 C++ 언어를 살펴보겠습니다. C++ 언어는 1980년 초, 벨 연구소에서 근무하던 Bjarne Stroustrup의 팀이 개발했습니다. C++ 언어는 C 언어를 기반으로 만들어졌는데, C 언어와 호환이 가능한 상위 언어를 목표로 개발되었기 때문에, C++ 컴파일러로도 C 언어로 개발된 프로그램의 컴파일이 가능합니다. C++ 언어는 객체 지향 개념과 클래스, 상속 등이 포함되어 있으며 제네릭 함수, 참조 타입과 같은 다른 고급 기능으로 C 언어를 확장하였습니다. C++ 언언은 가장 널리 사용되는 객체 지향 프로그래밍 언어 중 하나이며, 효율성과 C 언어와의 호환성을 강조하여 설계되었습니다.

C++에서 클래스와 접근 지정자는 데이터 추상화를 지원하고, 서브타입 다형성과 가상 함수를 통해 동적 바인딩을 지원합니다. 또한 이를 포함하여 다중 상속, 가상 기반 클래스 등으로 상속을 지원합니다. 마지막으로 템플릿 함수, 탬플릿 클래스, 그리고 연산자 오버로딩을 통해 다형성을 지원합니다.

데이터 추상화의 관점에서 C 언어와 C++ 언어를 비교해보겠습니다. 두 코드 모두 스택을 구현한 프로그램 코드입니다. C 언어의 경우에는 스택 본체를 전역 변수 배열로 선언하고, 스택의 각 기능을 함수로 정의하였습니다. 그에 반해 C++ 언어의 경우에는 스택 클래스를 통해 스택의 각 기능을 구현한 차이가 있습니다.
눈여겨볼 부분은 스택에서 사용되는 변수의 가시성입니다. C 언어에서는 stack 배열과 top이 전역 변수로 선언되어 있기 때문에 main() 함수를 포함한 모든 함수에서 볼 수 있고, 조작이 가능합니다. 이러한 가능성은 프로그래머의 의도와 다르게 해당 변수의 값이 변동될 수 있으므로 프로그램의 신뢰성을 낮추는 문제점이 있습니다. 그에 반해 C++ 언어에서는 이 변수들이 private로 선언되어 있기 때문에, 클래스 내에서만 접근이 가능합니다.

연산자 오버로딩은 동일한 기호나 함수 이름이 다른 의미로 사용될 수 있음을 말합니다. C++ 언어에서는 기존 클래스에서 정의된 연산자를 재정의할 수 있습니다. 예를 들어서, 이 슬라이드의 예제에서는 += 연산자를 재정의하고 있습니다. 재정의한 연산자는 두 개의 문자열을 이어붙이는 역할로 변경되었습니다.

C++ 언어는 접근 지정자를 통해 각 멤버의 접근을 제한합니다. private로 선언된 멤버는 선언된 클래스의 멤버 함수에서만 접근할 수 있습니다. protected로 선언된 멤버는 파생 클래스에서 접근할 수 있다는 차이점을 제외하면 private와 같습니다. public으로 선언된다면 모든 함수에서 접근할 수 있습니다.
또한 상속에서도 접근 지정자를 도입할 수 있습니다. public으로 상속한 클래스는 일반 기반 클래스와 동일하지만, private로 상속한다면 기반 클래스의 멤버가 파생 클래스에서 모두 private로 처리됩니다.

접근 지정자의 예시를 확인해보겠습니다. 왼쪽의 employee 클래스를 상속받은 manager 클래스가 있습니다. manager 클래스는 public으로 상속받았기 때문에 일반적인 상속이 발생합니다. 그런데, employee의 멤버 변수 중 list는 private로 선언되어 있기 때문에 manager 클래스에서 접근할 수 없습니다. protected와 public으로 선언된 나머지 멤버 변수들은 모두 접근이 가능합니다. 만약 manager에서 이 list 변수에 접근하고 싶다면, employee에서 list와 관련된 멤버 함수를 정의하고, 이 멤버 함수를 상속받아 간접적으로 접근하는 수밖에 없습니다.
오른쪽의 클래스 A, B, C 예제를 확인해보겠습니다. 클래스 C는 클래스 A와 B를 상속받았습니다. 클래스 A와 B 모두 display라는 가상 함수를 가지고 있지만, 매개변수의 타입이 다르기 때문에 죽음의 다이아몬드 문제가 발생하지 않습니다. 따라서 정상적으로 클래스 C에서 이 둘을 각각 정의하여 사용할 수 있습니다.

C++ 언어에는 다양한 내장 라이브러리가 존재합니다. 이중 가장 많이 사용했던 것은 MFC 라이브러리인데, 제가 학부를 다닐 때만 해도 학부 실습 시간에 MFC 프로그래밍을 가르쳤습니다. 최근에는 잘 사용하지 않는다는 이유로 빠져있더라구요.

C++ 언어에 대한 평가를 해보겠습니다. C++ 언어의 장점은 캡슐화 및 데이터 추상화 관점에서 신뢰성을 높이고, 구현에서 절차적 사양과 표현적 사항을 분리하는 것이 가능합니다. 또한 C++ 언어는 정적 바인딩이 사용되는지 동적 바인딩이 사용되는지를 명시할 수 있고, 동적 바인딩을 사용하는 경우에는 유연성을 증가시킬 수 있습니다. 또한 상속으로 인해 소프트웨어의 재사용성이 크게 증가합니다.
단점에 대해 언급해보자면 우선 높은 실행 시간 비용 문제입니다. 장점에서 언급했던 동적 바인딩은 실행 시간에 발생하고, 메시지 전달이 Smalltalk에 비해 1.7배 정도 느리기 때문입니다. 또한 의도와 코드 사이에서 발생하는 의미상의 차이와 소프트웨어 시뮬레이션의 어려움이 있으며, 클래스 라이브러리가 굉장히 많기 때문에 이것을 모두 배우기 어렵다는 문제가 있습니다.

정리하자면, 객체 지향 프로그래밍의 요소는 객체, 클래스, 메소드, 메시지, 상속, 동적 바인딩, 다형성 등의 특징을 가지고 있습니다.
객체 기반 언어에 클래스가 추가된 것이 클래스 기반 언어, 그리고 거기에 상속이 추가된 것이 객체 지향 언어입니다.

C++ 언어의 주요 개선사항 중 하나는 병렬 처리입니다. 최근 하드웨어는 다수의 CPU를 가지고 있기 때문에 병렬 처리를 수행할 수 있습니다. Java 언어에서는 Thread 클래스를 통해 병렬 처리를 지원하는데, C++도 마찬가지로 Thread, Async, OpenMP 등의 라이브러리를 통해 병렬처리 프로그래밍을 수행할 수 있습니다.

본 강의자료의 참고 문헌 목록입니다. 필요하신 분은 참고해주시기 바랍니다.

또한 강의자료에 많은 내용들은 An Introduction to Object-Oriented Programming를 많이 참고하였습니다.
12장의 내용은 여기까지입니다. 지금까지 읽어주셔서 감사합니다!
Leave a comment