
Arrays and Structures (1)
Arrays
처음 배우게 되는 자료구조는 배열(Array)입니다. 배열은 대부분의 언어에서 중요하게 다루는 자료구조이기 때문에 이미 알고 있으실 수도 있습니다. 배열의 가장 큰 특징은 메모리의 일부분을 연속적으로 할당한다는 것입니다. 배열의 구조는 굉장히 단순하기 때문에, 대부분의 언어에서 배열에 대해서는 복잡한 연산 기능을 제공하고 있지 않습니다. 일반적으로 배열을 생성한 후에는, 배열에 새로운 값을 할당하거나 이미 할당된 값을 찾는 기능이면 충분하기 때문입니다.
배열의 추상 데이터 타입(ADT)은 다음과 같이 정의됩니다.
ADT Array is
Object : A set of pairs <index, value> where for each value of index there is a value from the set item. Index is a finite set of one or more dimensions, for example, {0, ..., n-1} for one dimension, {(0,0), (0,1), (0,2), (1,0), (1,1), (1,2), (2,0), (2,1), (2,2)} for two dimensions, etc.
Functions :
for all A ∈ Array, i ∈ index, x ∈ item, j, size ∈ integer
Array Create(j, list) ::= return an array of j dimensions where list is a j-tuple whose ith element is the size of the ith dimension. Items are undefined.
Item Retrieve(A, i) ::= if (i ∈ index) return the item associated with index value i in array A
else return error
Array Store(A, i, x) ::= if (i ∈ index) return an array that is identical to array A except the new pair <i, x> has been inserted
else return error
end Array
C 언어에서 배열은 int list[5]와 같은 방법으로 정의합니다. 이것은 배열의 이름이 list이고, index는 0부터 4까지 5개가 있으며, 값은 int 자료형으로 정의하겠다는 뜻입니다. 이렇게 정의할 때는 실제로 다음과 같이 메모리 주소가 할당됩니다.
- list[0]의 주소 : a (base address)
- list[1]의 주소 : a + sizeof(int)
- list[2]의 주소 : a + 2 * sizeof(int)
- list[3]의 주소 : a + 3 * sizeof(int)
- list[4]의 주소 : a + 4 * sizeof(int)
이 때, C 언어에서 배열은 int에 대한 포인터로 취급됩니다. 이것을 이용해 배열을 int *list와 같이 포인터로 정의할 수도 있습니다. 따라서 list[i]는 *(list+i)로 표현할 수도 있고, &list[i]는 (list+i)로 표현할 수 있습니다.
다음은 배열을 이용한 간단한 C 프로그램입니다.
Program 2.1: Example array program
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <stdio.h>
#define MAX_SIZE 100
float sum(float[], int);
float input[MAX_SIZE], answer;
int i;
int main() {
for (i = 0; i < MAX_SIZE; i++)
input[i] = i;
answer = sum(input, MAX_SIZE);
printf("The sum is: %f\n", answer);
return 0;
}
float sum(float list[], int n) {
int i;
float tempsum = 0;
for (i = 0; i < n; i++)
tempsum += list[i];
return tempsum;
}
이 프로그램에서 sum 함수가 호출될 때, 매개변수로 들어가는 input은 &input[0]으로 번역되어 sum 함수의 배열 list에 대입됩니다. 배열이 대입연산자에서 호출이 될 때는 오른쪽에서 호출이 되었냐, 왼쪽에서 호출이 되었냐에 따라 처리되는 방식이 달라집니다. 만약 list[i]가 연산자 =의 오른쪽에서 호출될 때는 (list+i)가 가리키는 값으로 처리되는데, 연산자 =의 왼쪽에서 호출될 때는 (list+i)로 처리됩니다.
Program 2.2: One-dimensional array accessed by address
void print1(int* ptr, int rows) {
/* print out a one-dimensional array using a pointer */
int i;
printf("Address Contents\n");
for (i = 0; i < rows; i++)
printf("%8u%5d\n", ptr + i, *(ptr + i));
printf("\n");
}
print1은 1차원 배열에서 주소가 어떻게 할당되는지 확인하는 함수입니다. 실제로 이 함수를 호출해서 int형 배열인 list의 주소를 출력해보면 컴퓨터마다 다르겠지만 index가 하나 증가할 때마다 4씩 차이가 나는 것을 확인할 수 있습니다. 일반적으로 int 자료형의 크기가 4바이트로 정의되어 있기 때문입니다.
Dynamically Allocated Arrays
C 언어에서 배열을 선언할 때는 크기까지 한번에 같이 선언하는 경우가 많습니다. 하지만 그렇게 선언할 경우 배열의 크기를 변경할 수 없다는 치명적인 문제가 있습니다. 필요한 배열의 크기를 미리 알 수 있는 상황에서는 그에 맞게 정의하면 되지만, 만약 필요한 배열의 크기를 알 수 없거나 프로그램이 실행되는 상황에 따라 크기가 변동되는 경우에는 어떻게 선언해야할지 난감한 상황이 발생합니다.
이 경우 가장 좋은 방법은 동적 메모리 할당(Dynamic Memory Allocation)입니다. 다음과 같이 동적 메모리 할당을 이용하면 프로그램을 실행할 때마다 원하는 크기로 배열을 할당할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
#include <stdlib.h>
int main() {
int n, *list;
printf("Enter the number of numbers to generate : ");
scanf_s("%d", &n);
if (n < 1) {
fprintf(stderr, "Improper value of n \n");
exit(EXIT_FAILURE);
}
list = (int*)malloc(n * sizeof(int));
return 0;
}
하지만 2차원 배열인 경우에는 문제가 조금 복잡해집니다. 2차원 배열은 1차원 배열을 모아놓은 구조이기 때문입니다. 예를 들어, int x[3][5]와 같이 배열을 정의했을 때, 할당된 메모리를 그림으로 표현하면 다음과 같습니다.
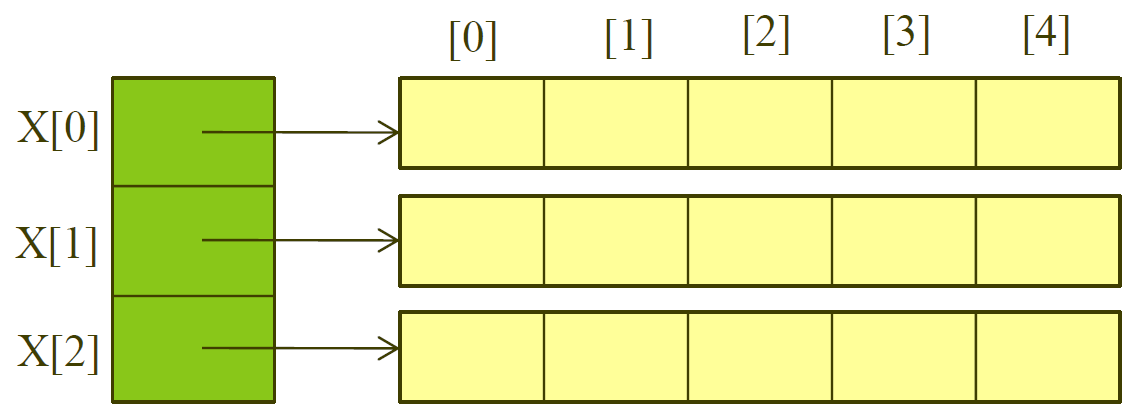
따라서 2차원 배열을 동적으로 할당할 때는, 먼저 1차원 배열을 할당한 다음에 1차원 배열의 각 index를 방문해서 하나하나 동적 할당을 해주셔야 합니다. C 언어로 예를 들면 다음과 같습니다.
Program 2.3: Dynamically create a two-dimensional array
int** make2dArray(int rows, int cols)
{ /* create a two dimensional rows * cols array */
int** x, i;
/* get memory for row pointers */
x = (int**)malloc(rows * sizeof(int*));
/* get memory for each row */
for (i = 0; i < rows; i++)
x[i] = (int*)malloc(cols * sizeof(int));
return x;
}
지금까지 동적 메모리 할당을 수행할 때는 malloc 함수를 사용했습니다. C 언어에서는 malloc 외에도 다른 동적 할당 방식이 존재하는데, 여기서는 간단하게만 짚고 넘어가도록 하겠습니다.
void* calloc(elt_count, elt_size): calloc은 malloc과 비슷하게 동적할당을 하는 함수입니다. 매개변수 elt_size 크기의 변수를 elt_count개 만큼 저장할 수 있는 메모리 공간을 할당합니다.void* realloc(p, s): realloc은 이미 할당한 공간의 크기를 변경하고 싶을 때 사용하는 함수입니다. 포인터 변수 p의 크기를 s 만큼 변경합니다.
Structures and Unions
구조체(Structure)는 각각의 항목이 타입과 이름으로 식별되는 데이터의 모음입니다. 프로그래밍 언어에 따라 레코드(Record)라고 부르는 경우도 있습니다. C 언어에서 구조체는 다음과 같이 선언할 수 있습니다.
struct {
char name[10];
int age;
float salary;
} Person;
이 구조체는 Person이라는 이름을 갖는 구조체로써, name이라는 문자형 배열 변수, age라는 정수형 변수, salary라는 실수형 변수를 항목으로 가지고 있습니다.
구조체에서 각 항목에 접근할 때는 다음과 같이 구조체 변수 이름 다음에 .(마침표)를 사용합니다.
strcpy(person.name, "james");
person.age = 10;
person.salary = 35000;
C에서 구조체를 선언할 때 typedef를 사용해서 선언할 수도 있습니다. 저도 구조체는 보통 이런 식으로 선언합니다.
typedef struct {
char name[10];
int age;
float salary;
} Person;
이렇게 선언할 경우, 구조체 변수를 선언할 때 Person p1, p2;과 같이 선언할 수 있다는 장점이 있습니다.
서로 다른 구조체 변수 사이의 항목을 비교하고 싶을 때는 구조의 각 항목을 하나하나 비교해주어야 합니다. 예를 들어 다음과 같이 if문을 사용하여 두 구조체 변수가 같은지 확인하려고 하면 컴파일 에러가 발생합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#include <stdio.h>
typedef struct {
char name[10];
int age;
float salary;
} Person;
int main() {
Person p1, p2;
strcpy(p1.name, "Ryu");
p1.age = 33;
p1.salary = 100.0;
strcpy(p2.name, "Ryu");
p2.age = 33;
p2.salary = 100.0;
if (p1 == p2) // Compile Error!
printf("Same");
else
printf("Different");
return 0;
}
서로 다른 구조체 변수가 같은지 다른지 비교하기 위해서는 다음과 같이 별도의 함수를 만들어서 모든 요소가 같은지 하나하나 비교하셔야 합니다.
Program 2.4: Function to check equality of structures
int humans_equal(Person p1, Person p2)
{
if (strcmp(p1.name, p2.name))
return 1;
if (p1.age != p2.age)
return 1;
if (p1.salary != p2.salary)
return 1;
return 0;
}
humans_equal 함수에 main 함수를 포함하여 전체 프로그램을 구현하면 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
typedef struct {
char name[10];
int age;
float salary;
} Person;
int main() {
Person p1, p2;
strcpy(p1.name, "Ryu");
p1.age = 33;
p1.salary = 100.0;
strcpy(p2.name, "Ryu");
p2.age = 33;
p2.salary = 100.0;
if (humans_equal(p1, p2) == 0)
printf("Same");
else
printf("Different");
return 0;
}
int humans_equal(Person p1, Person p2)
{
if (strcmp(p1.name, p2.name))
return 1;
if (p1.age != p2.age)
return 1;
if (p1.salary != p2.salary)
return 1;
return 0;
}
구조체 안에 구조체를 삽입하는 것도 물론 가능합니다. 이 때는 간단하게 구조체 안의 변수를 구조체로 형태로 선언만 해주시면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <stdio.h>
typedef struct {
int month;
int day;
int year;
} Date;
typedef struct {
char name[10];
int age;
float salary;
Date birthday;
} Person;
int main() {
Person p1;
p1.birthday.month = 3;
p1.birthday.day = 1;
p1.birthday.year = 1991;
return 0;
}
Unions
공용체(Union)는 구조체와 비슷한 구조를 갖고 있으나, 공용체로 선언된 항목들은 같은 메모리 공간을 공유한다는 특징을 가지고 있습니다. 즉, 공용체로 선언된 항목들은 한번에 한 가지만 사용할 수 있으며, 메모리 공간은 그들 중 가장 큰 공간을 가지고 있는 항목을 기준으로 할당됩니다. 먼저 C 언어에서 공용체의 예시를 보여드리겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <stdio.h>
#include <stdbool.h>
typedef struct {
enum tag_field { female, male } sex;
union {
int children;
bool beard;
} u;
} sex_type;
typedef struct {
char name[10];
int age;
float salary;
sex_type sex_info;
} Person;
int main() {
Person p1, p2;
p1.sex_info.sex = male;
p1.sex_info.u.beard = false;
p2.sex_info.sex = female;
p2.sex_info.u.children = 4;
return 0;
}
이 프로그램에서 공용체로 선언된 항목인 정수형 변수 children과 bool형 변수 beard는 둘 중 하나만 사용할 수 있습니다. 즉, 구조체 p1에서는 beard 변수를 이미 사용했기 때문에, children 변수는 사용할 수 없습니다. 단, bool형 변수의 크기는 원래 1 byte이지만, 정수형 변수 children과 같은 공용체로 묶여있기 때문에 차지하는 크기는 4 byte가 되는 것에 유의해주시기 바랍니다.
Self-Referential Structures
자기 참조 구조체(Self-Referential Structures)는 쉽게 말하면 구조체를 가리키는 포인터를 말하는 것입니다. 일반적으로 자기 참조 구조체라고 하면 구조체 내에서 그 구조체의 포인터형 변수가 항목으로 포함되어 있는 경우를 말합니다. 이게 어디에 쓰일까 싶으실텐데, 추후 배울 연결 리스트(Linked List)를 구현하기 위한 필요한 방법이기 때문에 어떻게 사용하는지 간단하게 짚고 넘어가겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
typedef struct {
char data;
struct list *link;
} list;
int main() {
list item1, item2, item3;
item1.data = 'a';
item2.data = 'b';
item3.data = 'c';
item1.link = item2.link = item3.link = NULL;
item1.link = &item2;
item2.link = &item3;
return 0;
}
이 프로그램에서 구조체 list는 자기 자신의 포인터형 변수인 *link를 가지고 있습니다. main 함수를 보시면 list형 구조체 변수인 item1, item2, item3이 정의되어 있는데, item1의 link가 item2를 가리키고, item2의 link가 item3을 가리키게 만들었습니다. 이렇게 데이터가 순차적으로 연결된 구조를 연결 리스트라고 합니다. 연결 리스트에 대해서는 나중에 자세히 다룰 예정입니다만, 연결 리스트가 자료구조의 핵심 파트라고 생각하기 때문에 미리 간단하게 설명을 드렸습니다.
이렇게 자료구조에서 사용되는 C 언어의 문법을 간단하게 정리해봤습니다. 다음 포스트에서는 이것들을 활용하여 구체적으로 어떤 자료들을 다루는지 자세히 알아보도록 하겠습니다.
Leave a comment